【干货分享】AIOps之根因分析
点击关注腾讯大讲堂,置顶公众号
给成长加点料!

导读:运维中总会存在一些由于版本变更、业务变化、代码逻辑或网络波动等带来的各种问题,尤其是系统较为庞大、复杂时,做原因跟踪分析就显得尤为困难。本文将给出基于决策树的智能根因分析方法,针对多维(可变维可达到千万维)找出导致问题的根因。做数据、搞AI一定要基于具体业务,不可脱离业务谈数据、算法,否则将得不偿失。
决策树是具有强解释性的有监督分类模型,其本质是一棵由多个判断节点组成的树,并且其为多分支节点(由具体需要划分类别决定),如下图所示(就是一个经典的两层树结构:基于天气判断是否要出去玩):
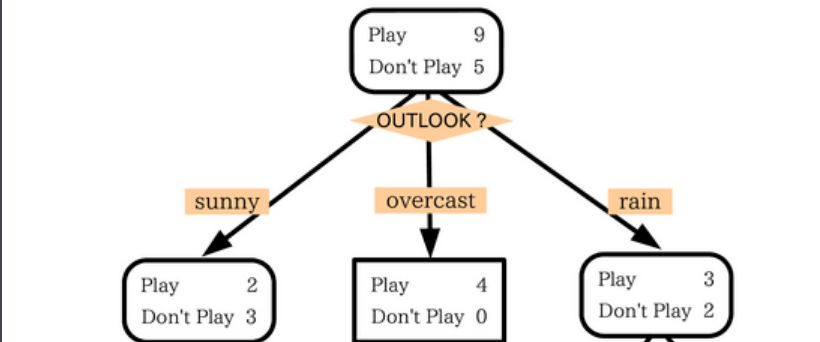
所以个人理解决策树就是,将一个数据集基于某个特征将其分成N类(N个子集),并且会循环划分子集,直到满足一定条件(子集数),或者子集中数据无法再继续划分。这样如果数据足够多、且稳定,就会得到一个类似上图的结果。
那么需要预测其类别的新数据就可以由此种树状结构基于相应特征进行流转,达到最终的节点(类别),也就是对新数据的预测结果。
简单了解决策树后,大家应该发现其核心是选择哪个特征作为当前划分标准,且划分的阈值是啥。对于这个不同决策树也有了不同的分类:
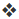
ID3分类树,只能用于分类不可用于回归,分类标准:信息增益,根据不同特征的不同特征值求信息熵,由:总体的信息熵 - 不同特征下的信息熵 = 信息增益,取使信息增益最大的特征为当前分类特征。
信息熵:
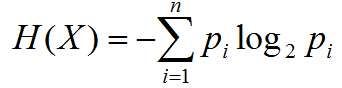
对于一个随机变量X,它的所有可能取值的信息量的期望成为熵。
基于信息增益分类存在一个很显著的问题,就是如果我们分析的数据中存在类似手机号的这样东西,那么由公式可知这样的信息熵约为0,也就是说,基于该特征通过对应的特征值可以很好地区分不同的数据。确实是这样,这里的手机号都类似于表中的唯一key键,当然可以很好地区分,但是在需求层面,这样的特征对我们是没有啥用的,所以使用ID3可避免这样的特征存在。
注意:信息熵是信息论中的概念,是用于评判信息混乱度的指标。由于生存的环境由各种因素影响会发生不同的变化,尤其是时间对事物变化的影响,这样事物发展就显示出了不确定性,而这样的不确定性可用熵来表示,熵越大表示越不确定。而人工智能想做的就是通过对历史的总结,希望能够预判出事物发展的趋势或方向(也就是引入了概率论),换句话说,做人工智能就是在利用一切可利用的工具、知识、数据等来控制熵使其尽可能的小。
与ID3相同只能用于分类,不可用于回归。针对ID3的信息增益存在的问题,C4.5做了相应的调整分类标准:信息增益率。
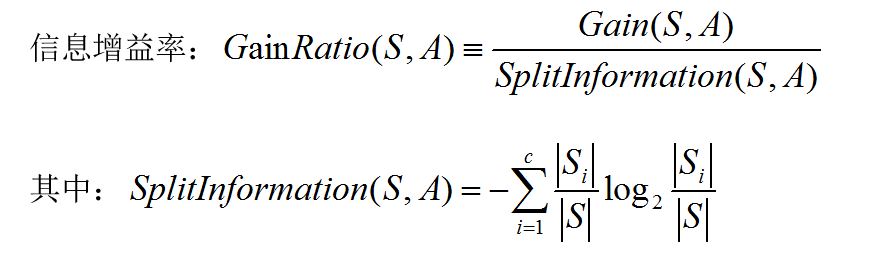
由公式可知:信息增益率还是基于信息增益考虑的Gain(S,A),但是其又多了一个分母SplitInformation(S,A),Si表示分的子集的含有的数据量,可以发现当Si越小时分母值越大。也就是不仅要考虑基于特征区分的效果,也要考虑划分子集的情况既要划的准又要划分的好。
C5.0是对C4.5的修订版,适用于处理大数据集,采用Boosting方式提高模型准确率,又称为BoostingTrees,需要购买使用。
CART(Classfication and Regression Tree :分类/回归树),既可以实现分类、又可以实现回归,当划分的节点是具体的数据集时,则是分类树,如果节点是基于数据集的线性函数,则是回归树。分类标准:基尼系数(gini):代表了模型的不纯度,基尼系数越小则不纯度越低,特征越好。
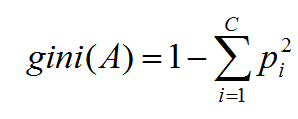
其中pi表示属于i类的概率,当gini(A) = 0 时表示所有数据属于同一个类,当C = 2表示是二分类是gini(A)最小值为:1/2(当pi = 1/2时);当C = 3时,三分类gini(A)最小值为:2/3(当pi=1/3时)。所以当C=2时,如果取pi=1/2则表示50%的概率,那么区分两类总体上来说是挺不错的。
本文使用的就是CART作为决策树算法。
介绍完决策树的一些基本信息,我们回过头来看一下为什么要选择决策树做根因分析呢?这明明是一个分类模型,和所谓的根因分析怎么挂上钩呢?
是这样的:决策树其本质就是 IF -- ELSE ,也是就说,我们根据一定的条件来对数据集做了分类,当一个数据落入某个节点时,它是有原因的,而不是随机生成的。其原因就是它的生成路径。例如:我饿了,然后我去吃饭了,那么反过来我去吃饭是因为我饿了(这个例子不是很好)。所以选择决策树在我看来有几个因素:
决策树分类路径作为根因分析行得通;
决策树是一种解释性很强的模型,所以对于原因这种需要有理有据的场景很合适;
决策树是一个经典的分类模型,有成熟的技术背景和文档等可寻。
根因分析的大体流程:
特征工程:选择合适的数据,并将数据数值化。
模型训练,利用sklearn等工具训练决策树模型。
基于训练结果做根因分析,或做新数据预测分析。
针对分析的结果做校验和优化。
在考虑使用什么样的数据进行训练分析,尤其是运维业务数据,其特点是数据相对复杂、数量多、影响因素多(服务端、客户端、业务逻辑层、技术方面等)。这里主要说一下几个可以考虑的方向,但是要结合具体使用场景来使用(场景是否需要,是否可以实现)。
注意:提前做好数据分析、处理是必要的,这部分工作通常会消耗1/2甚至更多时间,大家一定要有耐心,“天下没有免费的午餐”。切记,是数据决定了你的结果,不同模型、算法是使你更好地接近结果。
一、数据处理
数据展示:
数据展示工作是基础性的工作,但是有很多人会忽略这一部分工作,但是我觉得,大家在处理数据前,对要操作的数据有个整体感观是很有益的。
有很多方法可以实现:
(a)可以根据业务情况做些统计工作形成Excel表、透视图等;
(b)基于业务监控等已有的数据视图、表等;
(c)python中的pandas是一个很好的工具,可以很好地利用起来。
数据整体展示:
data = pd.read_csv("file.csv")
describe = data.describe()
print describe
imp_date reporttime appid resultcode tmcost
count 1.800000e+05 1.800000e+05 1.743380e+05 1.637210e+05 1.505090e+05
mean 2.017082e+09 2.017082e+13 8.769151e+05 2.506610e+04 8.123473e+09
std 8.180284e+01 8.186881e+05 3.162975e+05 2.432102e+06 1.101502e+11
min 2.017082e+09 2.017082e+13 0.000000e+00 -1.999000e+08 -2.133278e+09
25% 2.017082e+09 2.017082e+13 1.000027e+06 0.000000e+00 2.800000e+01
50% 2.017082e+09 2.017082e+13 1.000283e+06 0.000000e+00 1.630000e+02
75% 2.017082e+09 2.017082e+13 1.000361e+06 0.000000e+00 3.440000e+02
max 2.017082e+09 2.017082e+13 1.000458e+06 5.605577e+08 1.502082e+12
统计数据中空值情况(因为训练模型需要数值化所以必须要处理空值,根据空值不同情况有不同的处理方式,下面会介绍):
data = pd.read_csv("file.csv", '@', error_bad_lines=False)
colums = data.columns
for col in colums:
print col,' : ',data[col].isnull().sum()imp_date : 0
reporttime : 0
clientip : 0
ip : 0
appid : 5662
releaseversion : 5029
commandid : 12934
apn : 0
resultcode : 16279
device : 71191
sdkversion : 64575
touin : 214
空值处理:
空值处理是数据数值化前必做的工作,大家都知道不同的数据情况和业务需求,选择的处理方式是不一样的。主要有以下几种方式:
df.fillna(0) #用0填充缺失值 df.fillna('missing') 用字符串代替缺失值
df.fillna(method='pad')#用前一个数据代替NaN
df.fillna(method='bfill',limit=1)#用后一个数据替代NaN,限制每列只能替代一个NaN
df.fillna(df.mean()['one':'two'])#用平均数代替,选择one,two两列进行缺失值处理
df.dropna(axis=0) #删除含有NaN的行,axis=1 删除列
df.interpolate() #使用插值来估计NaN 如果index是数字,可以设置参数method='value' ,如果是时间,可以设置method='time'
df[key].fillna(value=mode, inplace=True) #使用众数替换空值
数据选择-数据预测:
拿某个业务的访问成功率举例,当成功率发生波动有异常,那么我们会将这一块时序数据拿出来分析。但是正常业务成功率是不可能波动特别大的,也就是异常数据占比小的问题,哪怕是真的出现了异常波动(失败数据)也是相对很少的。而且这部分数据中还有一些一直成功率就很低(比如一些老的服务器因素或者地域连接因素等)。
所以我们希望能够通过一些方式把真正导致异常波动的数据提取出来。借鉴方法可以做一层数据预测,如果场景中能够较好地做数据预测,那么提取数据就会好很多。
例如使用某个预测模型其准确率为80%,虽然不是很高,但是相较于直接使用数据要好很多,而且预测模型可能有更高的准确率。预测方法可以考虑:随机森林系列、线性回归、LSTM等。
数据选择-数据分类:
仍然以业务成功率为例,当出现成功率波动(异常出现),业务可能存在有不同的终端设备类型、不同的运营商、不同的服务器集群等。就拿终端来说,许多业务中iPhone苹果的性能和安卓的就不一样,可能某些业务几乎不可能是由于苹果导致的,那么分析的时候应该提前去掉这部分数据。
特征与标注:
数据整理想讲的也就是数据的数值化和特征数据的取舍,基于之前讲决策树基础时说到的类似手机号码这样的数据对于分析问题基本不起作用,反而可能会影响分析效果,所以类似这类数据大部分情况下应该不被考虑为分析数据。
对于一些数据,如运营商(版本、地域等)1:移动、2:电信、3:联通.........,这些只是为了是数据数值化才对应这样的数值,其并没有很强的可比性,如isp > 10 这样的结果基本没有作用。但是可以将其展开相应的值作为一个判断特征,如is-移动:判定是否是移动,is-v1.0.1:判定是否是v1.0.1版本等。
这里注意一下,在考虑通过特征值展开和特征值组合使用,使用one-hot编码等,可能会导致特征存在有百万或者更多维。这样会消耗很大资源进行运算,甚至可能无法计算,然而其中有很大特征是无需考虑的。这里大家可以尝试自己实现类one-hot编码。
数据标注:分类模型为了能够验证模型效果,需要对最终落入节点的数据进行验证,以作为模型使用的依据和模型优化的基准。根因分析中同样需要数据带有标注。
以业务成功率为例,可以将成功率高的记录标注为succ类型,而成功率低的记录标注为fail类型。这样的用处:
(a)可以用于模型优化;
(b)用于根因分析结果链路选取的依据,因为决策树根因分析结果是多条路径,而通常我们选择的根因因素是其中某几条。
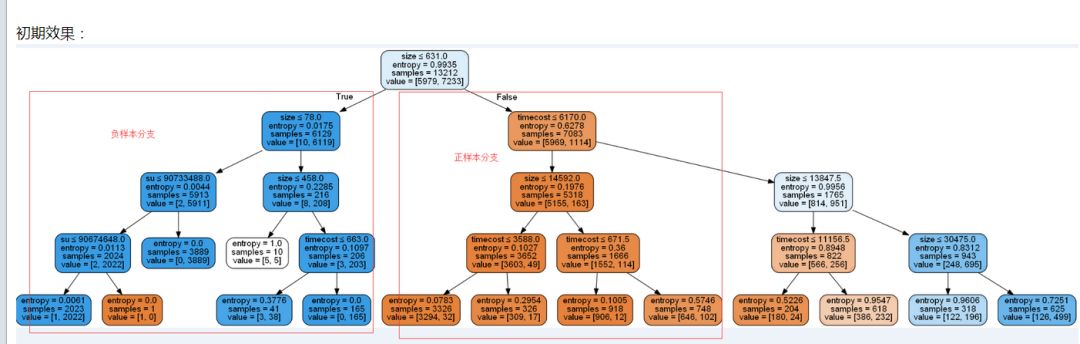
讲了许多,这里给出一个较为初始的结果图便于对照,其中蓝色是我们希望得到的负样本,而橘黄色是正样本,树是由不同条件和其分支组成,所以某些路径就是根因的某些原因。
二、决策树模型:
模型训练主要是基于特定的工具完成,所以相对来说较为方便。
from sklearn.tree import DecisionTreeClassifier
clf = DecisionTreeClassifier(criterion="gini",max_depth=6,min_samples_split=0.1) #构建树
clf.fit(df, label) #训练数据
dot_data = tree.export_graphviz(clf, out_file=None,
feature_names=featureNames,
filled=True, rounded=True,
special_characters=True) #将数据构建成树数据结构graph = pydotplus.graph_from_dot_data(dot_data) #构建树图
display(Image(graph.create_png())) #打印树图
graph.write_pdf("dc00944_4.pdf") #保存树图
模型训练这里需要强调的就是构建树的时候参数选择(这里讲几个常用到的):
criterion:string类型,可选(默认为"gini")有两种:gini 和 entropy
splitter:string类型,可选(默认为"best")"best",选择最好的分类,"random"选择最好的随机分类。
max_depth:int or None,可选(默认为"None")表示树的最大深度。
min_samples_split:int,float,可选(默认为2)区分一个内部节点需要的最少的样本数(int:最小样本点,float:ceil(min_samples_split*n_samples)样本占比)。
min_samples_leaf:int,float,可选(默认为1)一个叶节点所需要的最小样本数:
这里criterion用于选择不同的特征选择方式,以及splitter用于判断树特征的选择标准。其他的max_depth、min_samples_split和min_samples_leaf等用于树剪枝,使得得到的结果更优,这里也就是大家所说的“调参侠”的工作了。
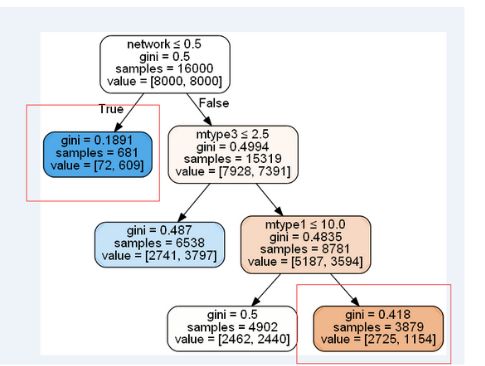
决策树剪枝:有两种方式前剪枝和后剪枝,前剪枝就是通过限定这些分支的结束条件完成的,也是我们通常控制的。后剪枝是在测试集和训练集上完成的,从上而下的找到叶子节点,用测试集来判断将这些叶节点合并是否能够降低测试误差,通过后期检验节点情况来判断是否应该拆分。
通过剪枝就可以切掉过多的叶节点,可以更好地展示效果。如上图,就可以剪枝到类似如下的效果(两者不是同一份数据 ,只是让大家看一下效果)。
结果处理
结果处理一般分为两个大的方向:
如上面的图所示就是以图的形式或者数据结构的形式展示,然后由人定性做分析给出结论。
结果自动化处理(这里主要讲一下这个点):
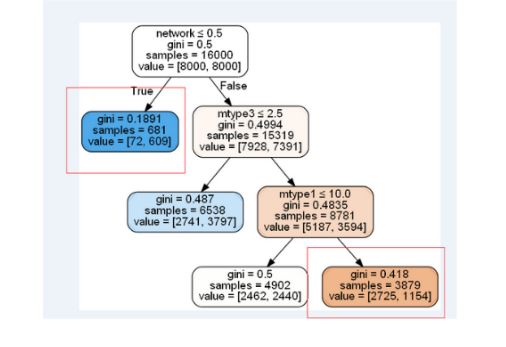
选取gini(节点中负样本/总样本)小的路径:可以通过解析树数据结构获取gini值,然后通过固定gini值,如选取节点上gini值=0.1的路径。也可以选取gini最小的路径作为根因。
选取负样本节点多的路径:上面是通过gini正负样本的比例,但是有时候也要优秀考虑负样本量。如下图所示当考虑使用gini时那么会选择第二层的左节点,但是里面负样本为609对于整体负样本的8000来说真的不多。
有时候我们需要考虑的是解决大头问题,就如第二层右边节点虽然gini不是很好,但是其负样本有7391。所以有的场景要撇开正样本只考虑负样本,选择以负样本量大的路径为根因。
基于决策树的根因分析大体上就如果上面所述,下面讲一下对于根因分析的发散,也是从不同的角度去分析这个根因,基于交叉熵或相对熵的根因分析。
信息熵:
相对熵(relative entropy)又称为KL散度(KL距离):
用于衡量两个分布(真实分布和预测分布)之间真实差别,是两个随机分布间的距离的度量。两分布的差距越大相对熵越大。
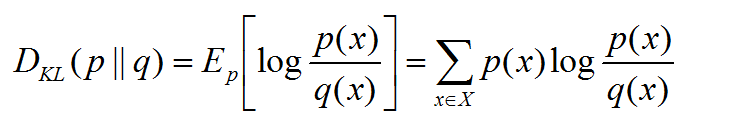
p:预测分布,q:真实分布。
交叉熵:
用于衡量两个分布(真实分布和预测分布)之间要消耗系统中的不确定性所需要付出的努力的大小。
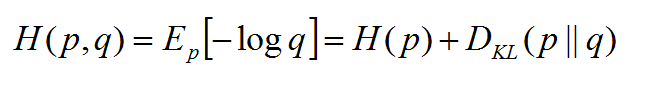
简单来说就是有两个数据集,一个是正常情况下的,一个是发生波动的数据集。相对熵可以度量出两个数据集特征间的差异,而交叉熵是比对从一个数据集到另一个数据集变化所需要的消耗。
以下面表为例,假设数据集中有版本和区域两个特征,正常情况下对应的特征值排位如下。
然而当异常发生的时候必然会有数据的波动,从而使得特征值的排位发生变化。如版本的2.1就由第三位到了第一位,而区域特征没有变化,相对熵和交叉熵简单来说就是用来统计两个数据集间特征值的变化波动情况。
正常情况下排位就应该是这样的,特征值占比排位变化了,那么问题很大程度上就是由变动大的特征值引起的,即变动大的特征值很大可能就是根因。
版本(正常) |
区域(正常) |
版本(异常) |
区域(异常) |
|
1.0 |
南京 |
2.1 |
南京 |
|
1.1 |
深圳 |
1.0 |
深圳 |
|
2.1 |
广州 |
1.1 |
广州 |
|
2.2 |
上海 |
2.2 |
上海 |
这也是为什么选用相对熵或交叉熵来找根因,就是这样我知道业务指标波动了,那拉出一份正常情况下的数据集和一份发生异常时的数据集。只需要用相对熵或交叉熵找出两者间的波动是由哪个或哪些特征主要引起的,就找到了导致业务异常的关键了。
选用相对熵或交叉熵的好处:
可解释性强,找出数据波动因素,将其转变成导致指标异常的原因。
计算简单,相对于决策树相对熵和交叉熵求解更为简便。
计算分为两个步骤:
步骤一:定位到那个特征波动值最大
for key, value in negative.iteritems(): //negative 波动数据集 positive 正常数据集
if key in positive:
sum += value * np.log2((value / positive[key]))
else:
sum += value * np.log2(value * n)
print col, ' : ', sum
if sum > max:
max = sum
max_col = col
这里用了一个判断是因为具体业务中存在的,也就是如果异常情况下丢失了正常情况下的某些特征值,那么就会导致求解有问题。这里将丢失的特征值用除以1/n(n要足够大,或者自己设置大的值)来替换。
步骤二:从特征中找到波动最大特征值
for key, value in (df_after[max_col].value_counts() / df_after.shape[0]).iteritems():
if key in positive:
kl = value * np.log2((value / positive[key]))
else:
kl = value * np.log2(value * n)
if kl > max_kl:
max_kl = kl
max_value = key
print max_value
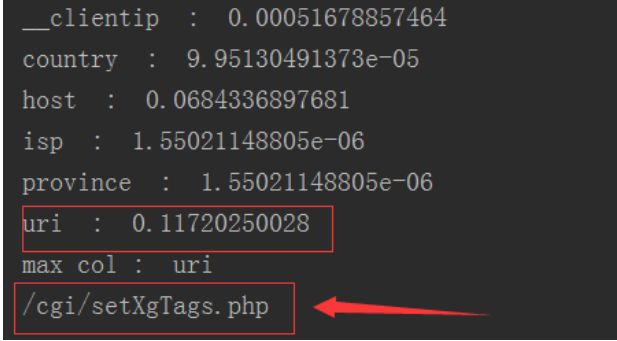
如下图有特征_clientip、country、host、isp、province、uri,通过求解得到uri的相对熵最大那么定位问题是由uri引起。再进一步分析由特征中那个值引起的,得到/cgi/setXgTags.php,通过验证,确实是由其引起的异常波动。
这里使用的相对熵和交叉熵实现的是单层单维的分析,可以根据业务具体情况做多层多维分析。这里可以将相对熵和交叉熵的结果与决策树的结果结合使用,以实现多模型分析增加分析的准确性。
补充:
这里对于决策树根因分析一些遗憾点做阐述。
决策树只能是先训练模型,然后跑数据做判断,模型的时效性不够。
业务变化是正常的,如果拿着之前业务形态的模型来做当前的分析确实存在问题,但是为什么一定要训练模型再跑数据呢?直接通过跑模型,那模型结果作为分析依据不就好了,实时地做分析。
业务中固定状态是占主体的,比如2G下的业务效果就是差,而根因分析出来也是定位到2G,且干扰其他想得到的因素怎么办?
这是一个基于决策树做根因的阻碍点,前面有提到希望对处理的数据做预测,如果预测层做的好,那么2G这样的因素应该是被过滤掉的。如果没有预测层,那么就需要严格调控正负样本那规避这样的问题,或者做结果分析的时候有选择的去除等。
正如前面所说,做AIOps一定要以业务需求为导向和归依。我们的研究和产品,如织云等也都是从这点出发,为了让业务能更加高效地完成,帮助企业建立智能运维门户。期待和大家分享更多AIOps的主题内容。
文章来源:腾讯织云
微信公众号(ID:TencentCOC)



