人脑90%都是自监督学习,AI大模型离模拟大脑还有多远?

新智元报道
新智元报道
【新智元导读】人的大脑和自监督学习模型的相似度有多高?

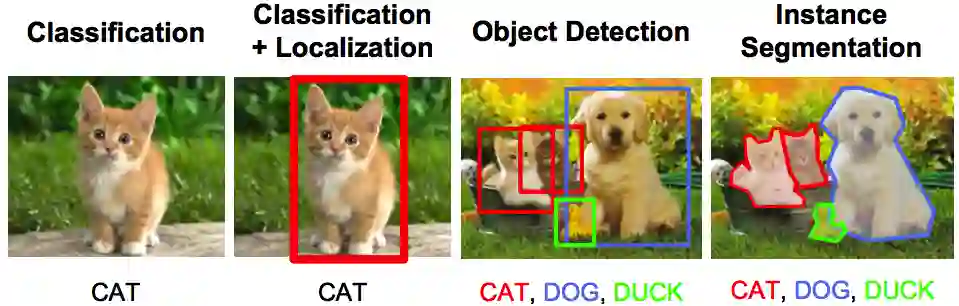
我们正在培养的算法,就像是一整个学期都没来上课的本科生,虽然他们并没有系统学习这些材料,但他们在考试中表现出色。
有缺陷的监督
大约10年前,受人工神经网络启发的大脑模型开始出现,同时一个名为AlexNet的神经网络彻底改变了对未知图像进行分类的任务。
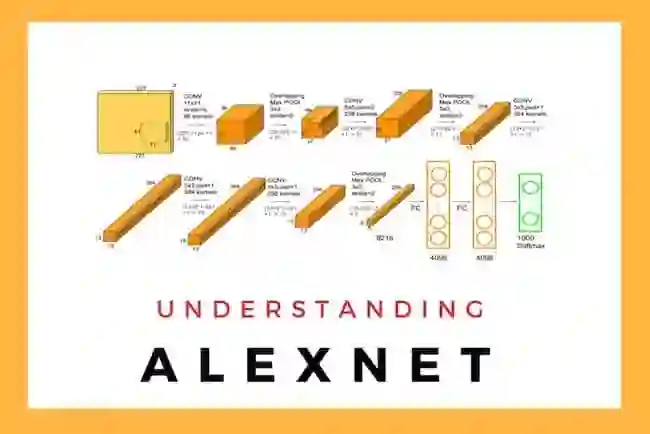

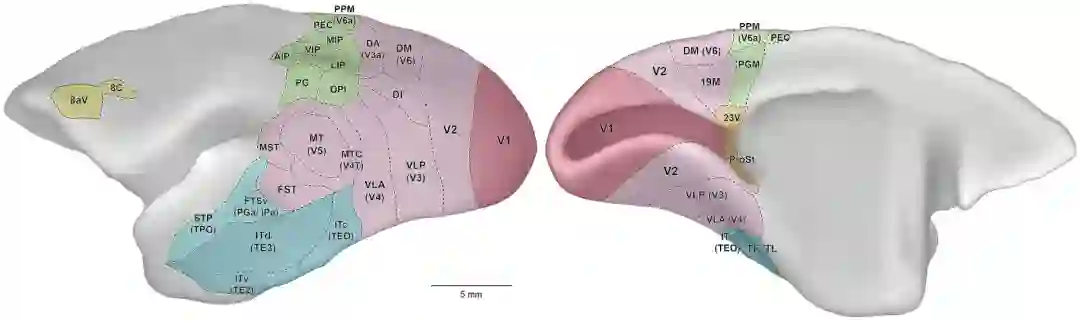

在这种方法中,人类不会标记数据,相反,标签来自数据本身。自监督算法本质上是在数据中创建空白,并要求神经网络填补空白。

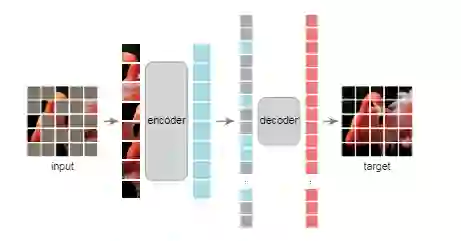
大脑也是「自监督」的
大脑也是「自监督」的


有人不同意:模拟大脑?模型、算法都差的远
有人不同意:模拟大脑?模型、算法都差的远


登录查看更多
相关内容

Arxiv
0+阅读 · 2022年11月23日
Arxiv
10+阅读 · 2021年10月4日



相关VIP内容
相关资讯