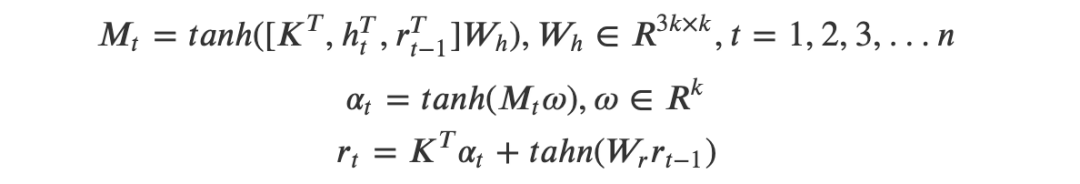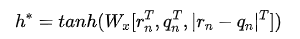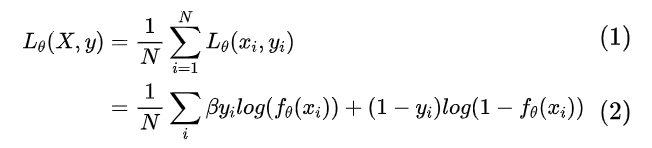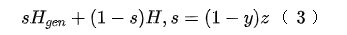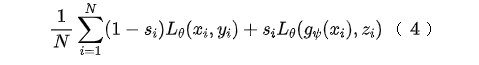本文介绍的是 ACL 2020 论文《Learning Robust Models for e-Commerce Product Search》,论文作者来自爱荷华州立大学、亚马逊。
作者 | 机智的叉烧
编辑 | 丛 末
论文地址:https://arxiv.org/pdf/2005.03624.pdf
1
背景
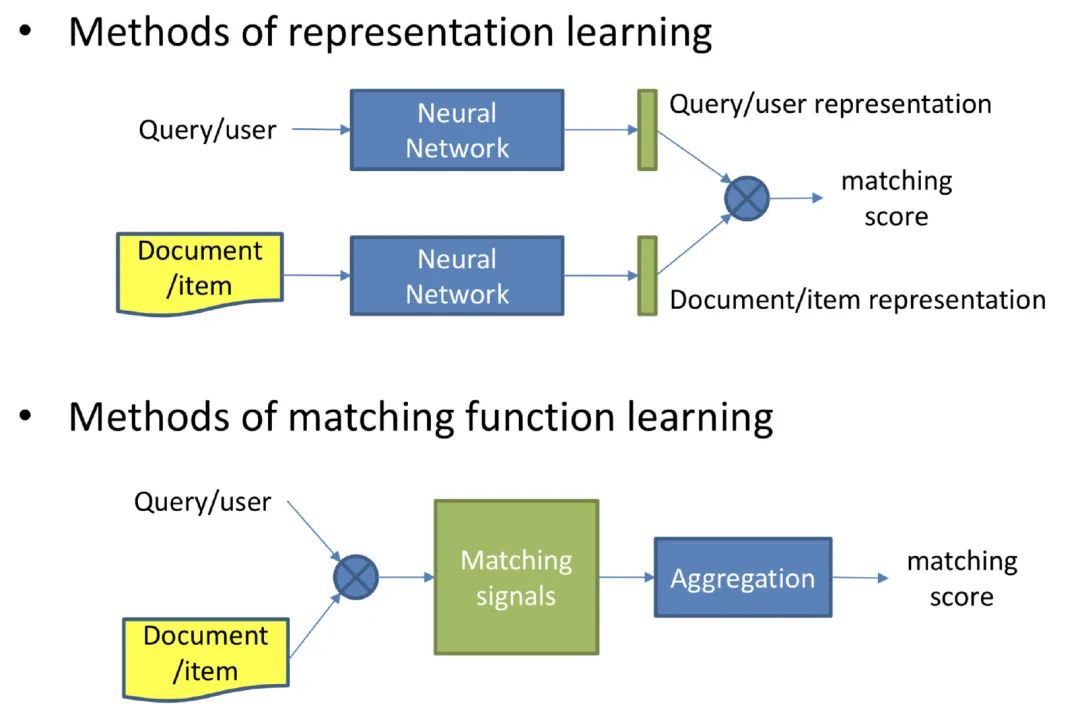
搜索和推荐经常会被放在一起对比,其中最突出的区别就是搜索中存在query,需要充分考虑召回内容和query之间的相关性,而如果内容是搜索广告,则对内容有更高的要求,相关性过低的内容被展示会让用户有很差的体验。相关性在一定程度上可以被抽象成doc和query之间的语义相似度问题,其实当前语义相似度的研究已经非常成熟,在sigir2018中有人曾经对搜索和推荐中的深度学习匹配进行了非常全面的综述:Deep Learning for Matching in Search and Recommendation[1]。在语义匹配上,大家的关注点经常在于如何去定义“匹配”上,尤其是分析如何将两者的编码内容更好地匹配起来。常见的其实就是两个思路:
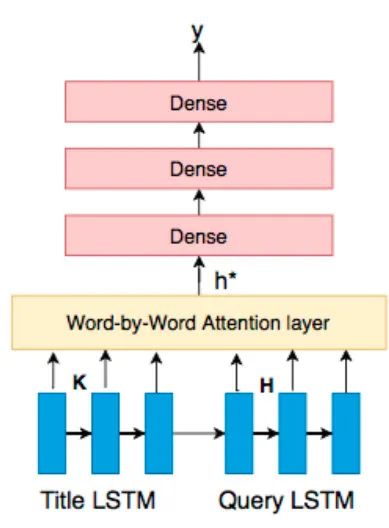
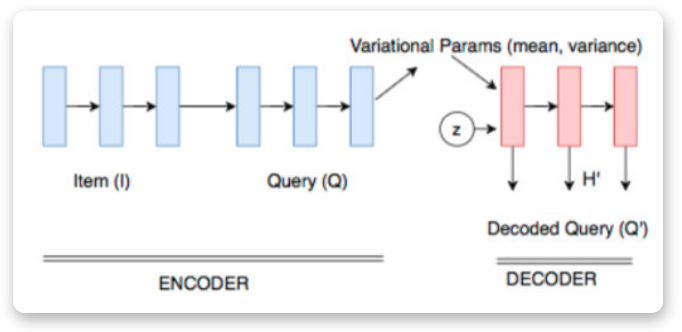
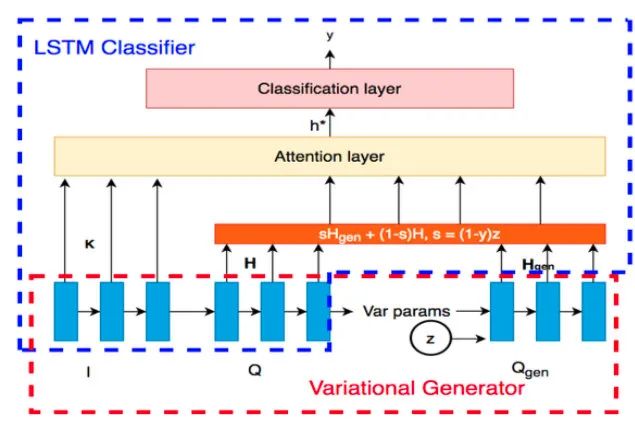
其中是一个调整正样本权重的超参数,在本文中会更看重正样本(不匹配的),因此有。4、文本生成器搜索引擎下正样本(不匹配)很简单,但是要找到与对应title不匹配,但是和对应query比较相似的文本,也就是我们所说的“对抗样本”,真的不容易,我们希望的是找到对抗样本协助训练,从而提升模型的鲁棒性。文章里作者使用的是VED——变分编码解码器,我们希望的是,输入,能够生成一个,这个与不匹配,但是与非常接近(其实某种程度上可以理解为我们要去挖掘相似度分类的“决策边界”)。作者本身对VED没有很多的改进,而是直接沿用(Bahuleyan et al., 2017)[7]的操作,具体的格式就变得很简单:5、生成器和query的联动 由于内部其实涉及了两个任务:分类和生成,要使这两者总体端到端化,有必要涉及一个统一的损失函数,权衡两者使两者尽可能同时达到最优。回过头来重新看看整个模型架构,尤其是橙色部分:
[2] Learning deep structured semantic models for web search using clickthrough data: https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/cikm2013_DSSM_fullversion.pdf
[3] Learning Robust Models for e-Commerce Product Search: https://arxiv.org/abs/2005.03624
[4] Adventure: Adversarial training for textual entailment with knowledge-guided examples: https://arxiv.org/abs/1805.04680
[5] Reasoning about entailment with neural attention: https://arxiv.org/pdf/1509.06664.pdf
[6] Neural machine translation by jointly learning to align and translate.: https://arxiv.org/abs/1409.0473
[7] Variational attention for sequence-to-sequence models.: https://cs.uwaterloo.ca/~ppoupart/publications/conversational-agents/variational-attention-sequence.pdf