微软发布SynNet:两步打造可迁移学习的机器阅读理解系统
李根 编译整理
量子位 出品 | 公众号 QbitAI
我们先把“机器灭绝人类”的探讨放一放,因为还有很多“看起来简单做起来难”的问题未得到解决,比如阅读理解。
对于人类来说,阅读理解是一项最基本的认知技能,并且人类很小的时候,就能在阅读完某一篇文章后,回答其中心思想和关键细节。
但这对AI并不简单。目前让机器实现完全的阅读理解,仍旧是一个不小的挑战,不过这又是打造通用AI而必须完成的目标。
实际上,机器阅读理解(MRC)对于解决很多现实问题和场景,都是非常有帮助的。比如用户服务、咨询、建议、问答对话和客户关系管理等,更具体一点,如果机器阅读更好用,就能帮助医生在数以千计的文件中快速找到重要信息——时间的价值想必在救死扶伤的行业中不言自明。
当然,机器阅读能力的提升,也会影响到每个用户的日常。
比如在搜索中,如果给出的是一个精确的答案,而不是一个内有答案的长篇网页的URL,可能用户体验会好太多。另外,有一些冷门或特定领域的文章中的特定知识,仅依靠现在算法获得的搜索数据,或许非常有限——机器阅读理解能力的提升将为此带来质的改变。
值得一提的是,如果你是工程师/开发者,现在也能通过最新的研究方法,打造一个机器阅读理解方面的AI了。
这一进步得益于微软AI研究院的最新成果。Po-Sen Huang,Xiaodong He和来自斯坦福大学的David Golub,公布了一种机器阅读理解解决方案:运用迁移学习算法解决机器阅读理解中的问题,运用真实数据,解决现实问题——而不是理论意义的算法模型。
说到这,如果你对机器阅读理解有过尝试,可能就会眼前一亮了。
因为现在最先进的机器阅读系统,都基于有监督的训练数据,用来训练这些系统的数据样例,不仅包含文章本身,还有手动标注出来的文章相关问题和答案。深度学习MRC模型通过这些标注数据学习读懂问题,并进一步基于文章推断答案,这中间涉及多个推理和推理步骤。
然而,在很多垂直领域,这种监督训练数据并不存在。比如我们想要通过一个新的机器阅读系统来帮医生找关于新疾病的重要信息,可能会有多个文档可用,但并没有关于文章的手动标注问题,以及相对应的答案。这不是一个小问题。
如果需要为每一个不同的新疾病建立单独的MRC系统,而且所有迅速增加的文献都要纳入其中,关于标注和训练数据带来的工作量,就会指数级增加。
那是否可以将现有的MRC系统转移到之前没有训练数据的新领域呢?这就是此次微软AI研究团队的成果。
微软AI团队开发了一种名为“两阶段综合网络”的模型,也称SynNet。这个模型中,SynNet先基于一个领域的可用训练数据,学会阅读理解该文章中潜在的知识点。第二阶段,SynNet模型在文章中基于上下文,针对第一阶段的“知识点”形成自然语言问题。
于是一旦训练完成,SynNet就可以应用到新领域,阅读新文档,再生成潜在问题和对应文本的答案。然后SynNet就能不断形成必要的训练数据,用来训练该领域的MRC系统。
在这个SynNet模型中,生成问答的过程可以被分解称两个步骤:
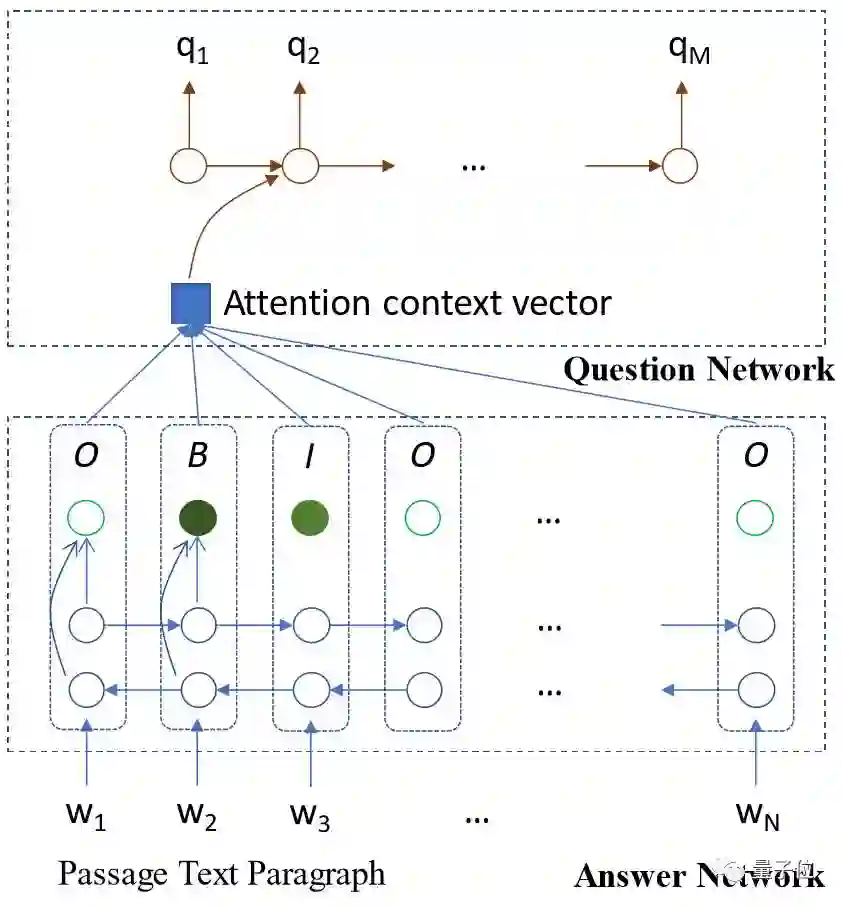
一、以段落为单位,生成答案,背后原理是使用双向长短期记忆(LSTM)来预测输入段落的内外起始点(inside-outside beginning, IOB)标签,找到潜在的关键语义概念;
二、生成问题,使用单向LSTM来产生问题,同时参与段落中的单词和IOB ID的嵌入。
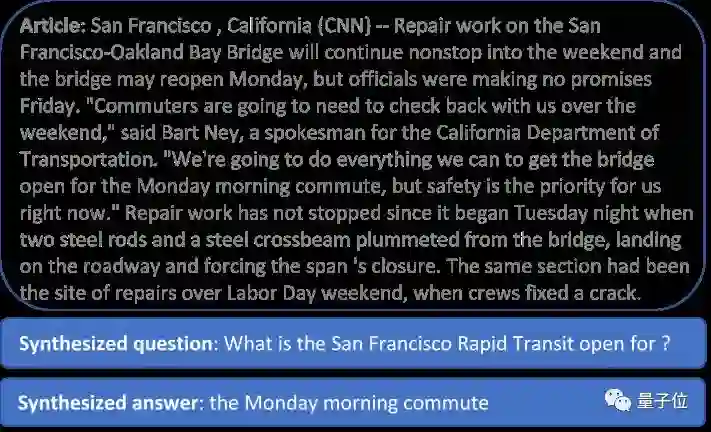
有两个利用这种方法生成的问题和答案的例子:

最后,可能你会关注使用SynNet实际应用的效果。微软AI研究团队先用SQuAD(维基百科文章)训练SynNet,然后把它应用到NewsQA(新闻文章)上,发现它的效果与直接在NewsQA上训练的网络相差无几。
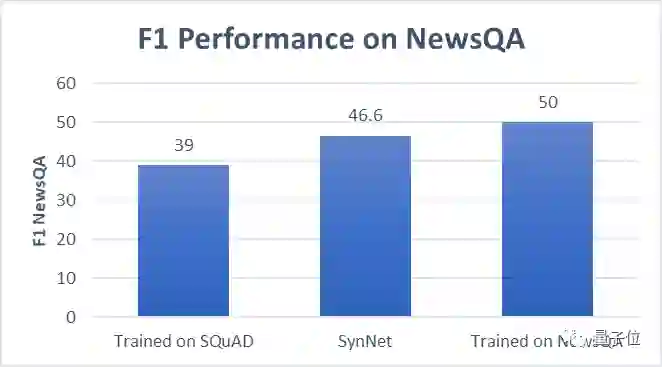
也就是说,通过使用SynNet,可以开始在无需额外标注、训练数据的基础上,在新领域打造一个完全监督的MRC系统。
相关论文:
https://www.microsoft.com/en-us/research/publication/two-stage-synthesis-networks-transfer-learning-machine-comprehension/
【完】
活动报名

8月9日(周三)晚,量子位邀请三角兽首席科学家王宝勋,分享基于对抗学习的生成式对话模型,欢迎点击这里报名~
交流沟通
量子位还有自动驾驶、NLP、CV、机器学习等专业讨论群,仅接纳相应领域的一线工程师、研究人员等。
请添加小助手qbitbot2为微信好友,提交相应说明,符合条件将被邀请入群。(审核较严,敬请谅解)
诚挚招聘
量子位正在招募编辑/记者等岗位,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。

△ 扫码强行关注『量子位』
追踪人工智能领域最劲内容




