500亿参数,支持103种语言:谷歌推出「全球文字翻译」模型
选自GoogleAIblog
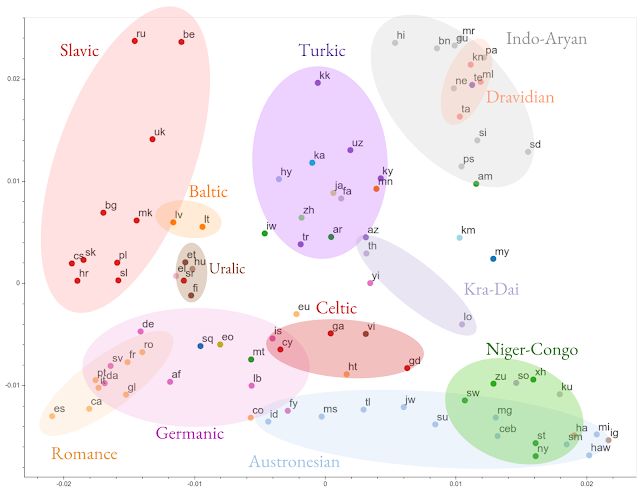
由于缺乏平行数据,小语种的翻译一直是一大难题。来自谷歌的研究者提出了一种能够翻译 103 种语言的大规模多语言神经机器翻译模型,在数据丰富和匮乏的语种翻译中都实现了显著的性能提升。他们在 250 亿个的句子对上进行训练,参数量超过 500 亿。




登录查看更多
相关内容
专知会员服务
13+阅读 · 2020年3月12日
Arxiv
7+阅读 · 2019年2月3日


相关VIP内容
专知会员服务
13+阅读 · 2020年3月12日
相关资讯
相关论文
Arxiv
7+阅读 · 2019年2月3日