Facebook 正改进聊天机器人的对话能力,让它们学会「闲聊」

Facebook 的 AI 研究院发表了一篇有关于聊天机器人的论文,指出了聊天机器人应该如何提升。
尽管 Facebook 关闭了自家个人助手 M,但 Facebook 依然没有放弃聊天机器人。在过去的几年里,Facebook 曾做过很多尝试,如让聊天机器人代表用户进行谈判;关闭了两个突然开始自行对话的机器人「Alice」和「Bob」;发布研究工具 ParlAI。如今,他们正在努力改进聊天机器人的对话和交谈能力,让机器人学会「闲聊」。
虽然它被叫做「聊天机器人」,但聊天机器人不能真正聊天。近日,Facebook 的 AI 研究院发表了一篇有关于聊天机器人的论文,指出了聊天机器人在一些层面上需要得到提升。首先,它们不会表现出「一贯的个性」,在整个对话过程中不会有自己的性格;其次,缺乏明确的长期记忆,机器人不记得自己和对话者过去曾经说过什么;第三,机器人倾向于产生如「我不知道」这样非特定问题的回答。这三个问题结合在一起,带来了不好的体验。
研究人员认为,其中的一些问题没有得到解决是由于没有一个好的公开的聊天数据集。而学术界则侧重于任务驱动的对话系统,如查询航班信息、预订餐厅。但大量的人类对话集中在社会化、个人兴趣和闲聊上。例如,Twitter 上只有 5 % 不到的帖子是问题,而大约 80 % 的帖子是关于个人情感状态、想法或活动。
但 Facebook 的研究人员正面临的问题是如何获取到正确的数据。例如,很多聊天机器人都是从电影剧本中学习对话的。这意味着他们在进行不是像客户服务那样的对话时,可能会出现各种问题。为了解决这个问题,Facebook 的工程师建立了自己的数据集来训练聊天机器人,这个数据集被称为 Persona-Chat,这些数据集来自亚马逊的 Mechanical Turk 线上市场,包含了超过 16 万条对话。
Persona-Chat 的优势之处在于,它的数据不是完全随机的。据报道,为了制造出一个有个性的聊天机器人,Mechanical Turk 团队甚至给所有的机器人都创建了个性化角色档案。例如,其中的一个聊天机器人对自己的描述为「我是一个艺术家。我有四个孩子。我最近有了一只猫。我喜欢散步锻炼。我喜欢看《权力的游戏》」。
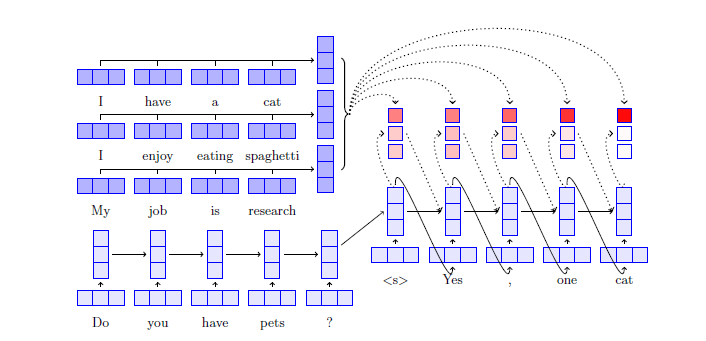
这些数据被用来训练用于现有聊天机器人的神经网络,然后由另外一组团队成员对结果进行评估。在 Facebook 创建的「角色扮演」型机器人与人类和其它聊天机器人同台 PK 的过程中,「角色扮演」型机器人在「流畅性」和「一致性」这样的标准上虽然没有超过人类,但它超越了由电影剧本对话数据所训练的机器人。
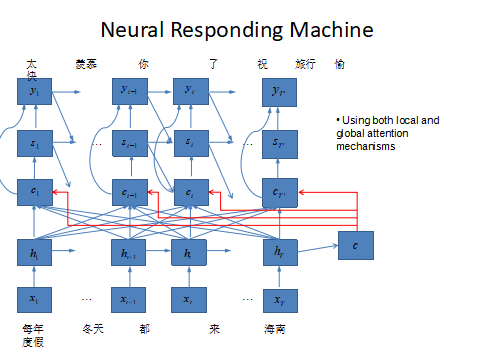
除了 Facebook,很多研究人员也展开了不同方式的探索。很多聊天机器人的对话系统都是检索式的,系统会检索出最相关的回答,而华为的诺亚方舟实验室则尝试了产生式的单轮对话系统,输入一句话后,会产生无数不相同的回复。研究人员通过爬取微博上的 400 万数据训练了这套系统。这个系统能回答你没见过的话,但也存在风险,可能出现回答符合语境但事实错误的情况(如提问姚明身高是多少,回答为一米二)。
但无论是 Facebook 还是其他研究人员的项目,都离落地还有一定的距离。不过,像 Siri 和 Alexa 这样的语音助手已经走入了我们的生活,我们很期待新的技术能够走向现实。
头图来源:视觉中国
责任编辑:双筒猎枪
本文由极客公园原创
转载联系 zhuanzai@geekpark.net








