【华为】对标谷歌Dropout专利,华为开源自研算法Disout,多项任务表现更佳
点击上方,选择星标或置顶,每天给你送干货
阅读大概需要7分钟
跟随小博主,每天进步一丢丢


来源|量子位
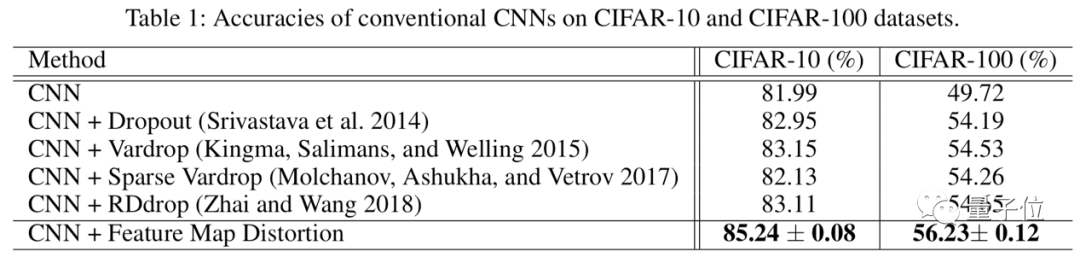
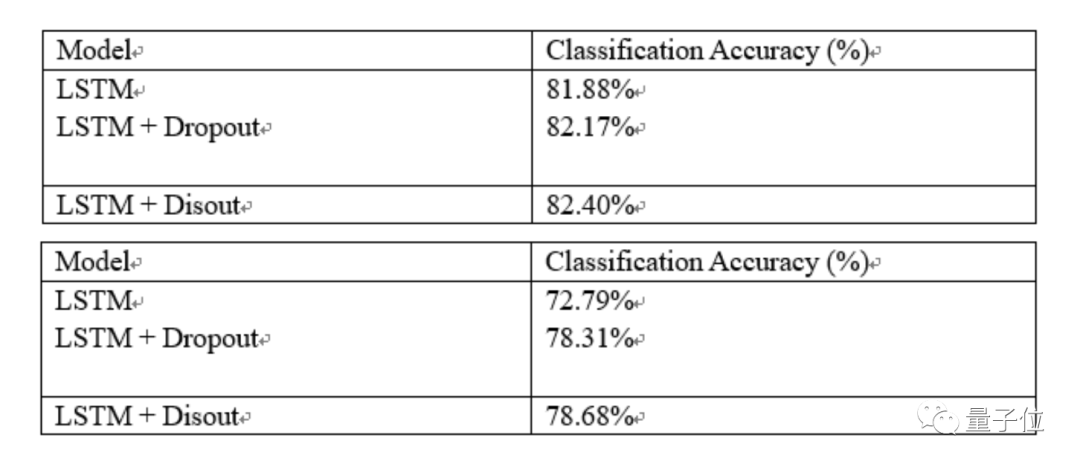
华为自研Disout:多项AI任务超越Dropout
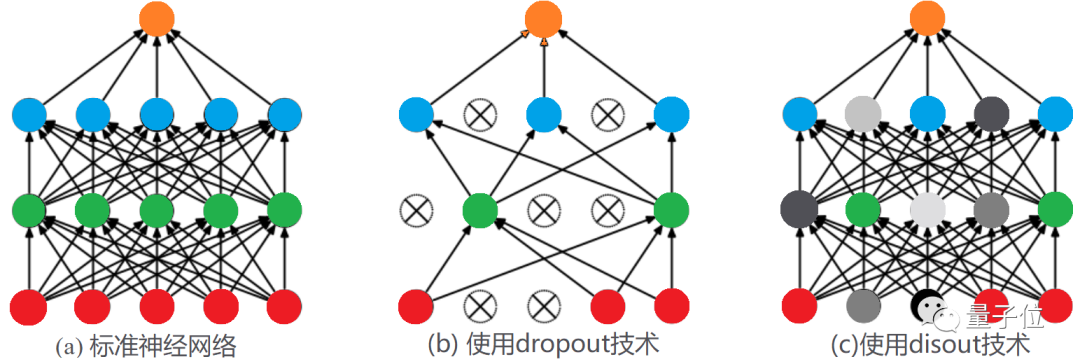

核心突破:对输出特征进行扰动,而不是丢弃
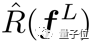 是:
是:
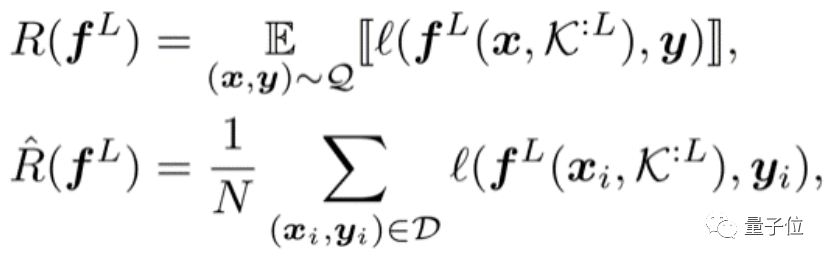
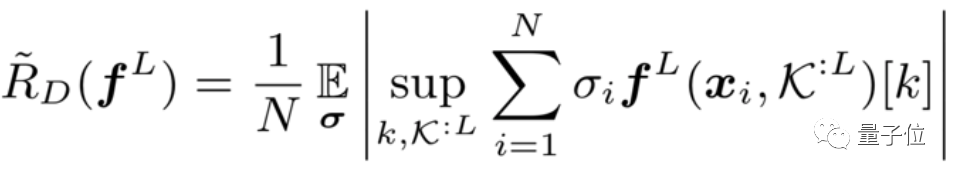
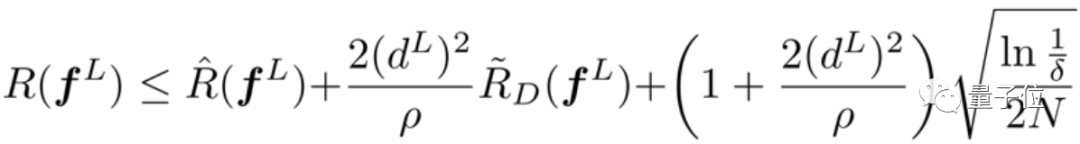
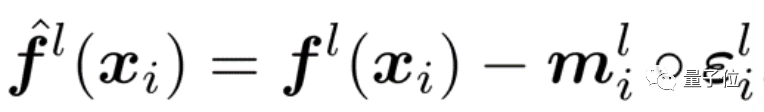
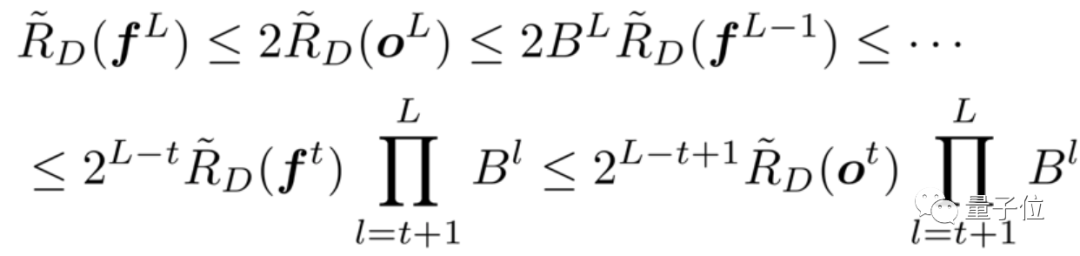
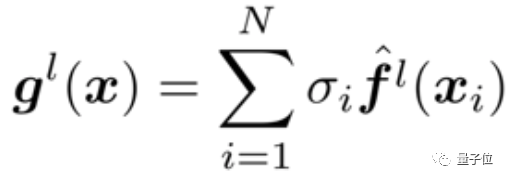
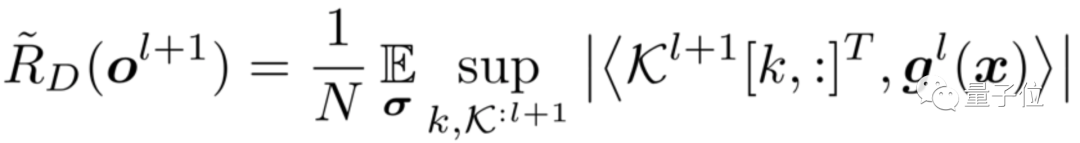
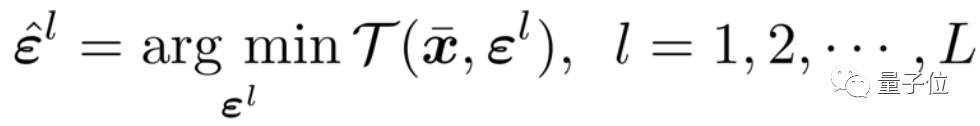

实习生一作,华为诺亚实验室出品

https://github.com/huawei-noah/Disout
https://www.aaai.org/Papers/AAAI/2020GB/AAAI-TangY.402.pdf


登录查看更多
相关内容

Arxiv
11+阅读 · 2020年2月18日
Arxiv
5+阅读 · 2018年4月5日

相关VIP内容
相关资讯
相关论文
Arxiv
11+阅读 · 2020年2月18日
Arxiv
5+阅读 · 2018年4月5日