中国团以98%精度夺得MegaFace人脸识别冠军(开源)

2018 年 2 月,DeepInsight 洞见实验室团队将 MegaFace 的精度提升到了 98%,超过俄罗斯 Vocord 公司保持的 91% 的纪录,让这一大规模人脸识别具备了一个更加良好的 baseline。我们同时公布了代码[0],数据,以及相应论文[1],希望能推动人工智能从业人员进一步来解决更大规模的人脸识别挑战。
1、网络结构
1.1 网络输入设定 :在我们所有的实验当中,都根据人脸的 5 个关键点进行对齐,并且切割设置大小到 112x112。因为这个图片大小是 ImageNet 输入的 1/4,我们考虑取消常见网络结构起始的降分辨率操作,即替换(conv77-stride22)为(conv33-stride11)。我们这个输入放大版的网络结构标记为 L。
1.2 网络输出设定 :此处输出指代特征向量这一层。我们实验了多种从最后一个卷积层之后如何连接到特征向量的方法,发现了最优的结构代号 E,即 (Convolution -> BN -> Dropout -> FullyConnected -> BN),更多的选择和实验结果可以参考原文 [1]。
1.3 ResNet 单元设定 :在ResNet 中,我们发现 3*BN[5] 的单元相比原始实现[6]和 Identity Mapping[7]的 unit 性能更好,标记为-IR。
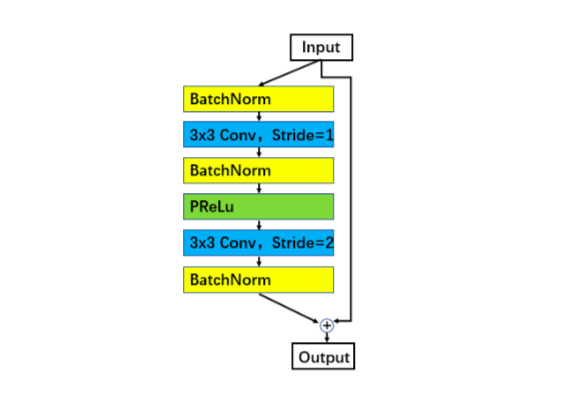
图 1: Improved residual unit: BN-Conv-BN-PReLu-Conv-BN
1.4 评测数据 :我们在 VGG2 数据集上用 Softmax 测试了不同网络骨干和不同配置,得到以下结果:
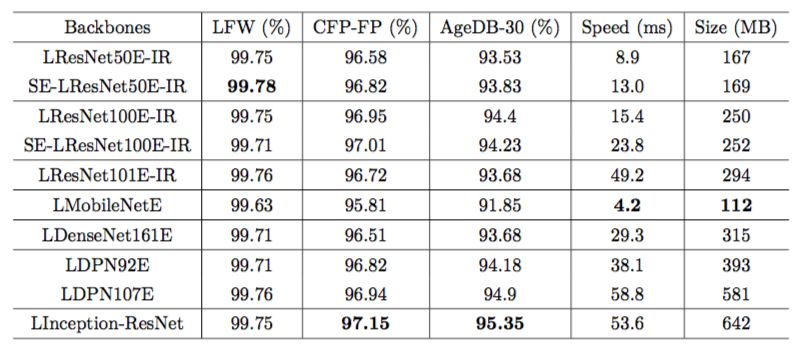
表 1: Accuracy (%),speed (ms) and model size (MB) comparison between different backbones (Softmax@VGG2)
据此,我们选择 LResNet100E-IR作为我们的主力网络骨干,因为它出色的性能和相对不大的开销。
2、损失函数
2.1 Softmax :损失函数是另一个提升识别精度的关键工作,在大家极力压榨网络骨干结构换取性能提升的时候,回头再来看损失函数这个网络训练的指挥棒,会有更多的发现。做为最常见的分类损失 Softmax,其定义如下:
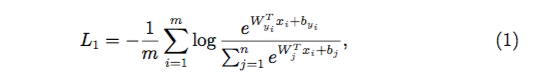
Softmax 是最常见的人脸识别损失函数,然而,Softmax 不会显式的优化类间和类内距离的,所以通常不会有太好的性能。
2.2 Triplet Loss :Triplet Loss 作为一种 Metric Learning,也在人脸识别中广泛使用。定义为:
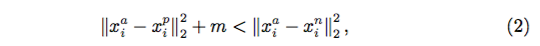
相比 Softmax,其特点是可以方便训练大规模 ID(百万,千万)的数据集,不受显存的限制。但是相应的,因为它的关注点过于局部,使得性能无法达到最佳且训练需要的周期非常长。
2.3 SphereFace :由于 Tripelet Loss 训练困难,人们逐渐寻求结合 Metric Learning 思想来改进 Softmax 的思路,其中 SphereFace[2] 是其中的佼佼者,作为 17 年提出的一种方法,在当时达到了 state-of-the-art。其定义如下:
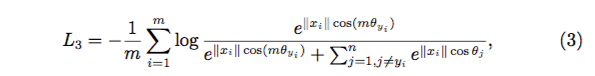
在具体实现中,为了避免加入的 margin(即 m) 过大,引入了新的超参 λ,和 Softmax 一起联合训练。
那么这里的 margin 具体是什么? 包括下述的几种算法都会提到 margin。我们从 Softmax 说起,参考上一节他的公式
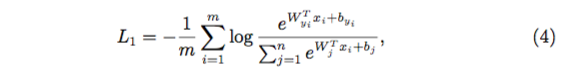
为了方便计算,我们让 bias=0,则全联接的 WX 可以表示为
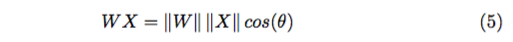
θ 表示 W 和 X 的夹角,归一化 W 后:
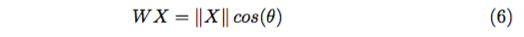
对特定的 X,|| X || 是确定的,所以这时 Softmax 优化的其实就是 cos 值,或 者说他们的夹角 θ。
在这样的 Softmax 中,类和类之间的界限只是一条线。这样会产生的问题是: 落在边界附近的点会让整个模型的泛化能力比较差。为了解决这个问题,作者就想到了让这个界限变大一些,让不同类之间的点尽量远。在投影的夹角上加入一个 margin 可以达到这个目的,如下图:
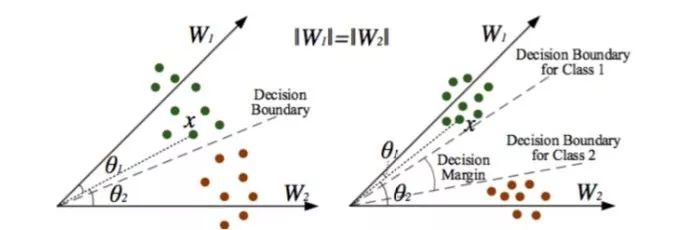
图 2: sphereface
可以看到在这样做之后,即使是类间距离最近的点也有一定的 margin。在训练中,相同类的人脸图片会向着自己的 w − vector 压紧。
2.4 Additive Cosine Margin :最近,在 [3],[4] 中,作者提出了一种在 Cosine 值上加入 Margin 的策略,定义如下:
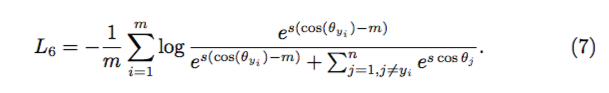
模型获得了比 [2] 更好的性能,同时实现很方便,也摆脱了和 Softmax 联合训练的困扰,在训练起始阶段不再有收敛方面的问题。
2.5 Additive Angular Margin :我们 [1] 提出了在角度上增加固定值的 Margin,在 Cosine Margin 的基础上,更具有几何 (角度) 解释性并且获得了更好的性能,定义如下:
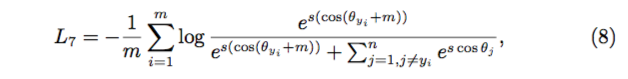
这里我们同时 normalize 了 weight(到 1) 和 feature(到 s,默认 64),则 (Cosine Margin 也同理):
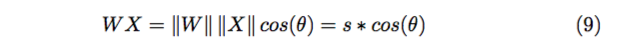
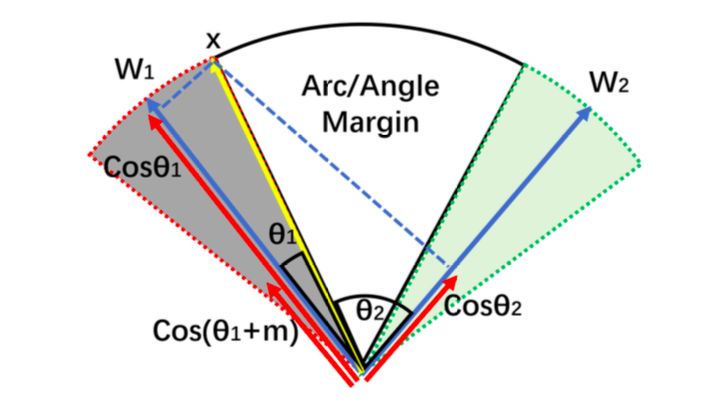
图 3: ArcFace 几何解释
2.6 对比:以二元分类举例,以上各算法的 decision boundary 如下:
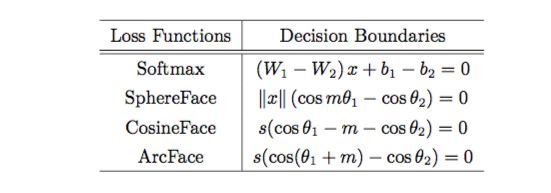
表 2: Decision boundaries for class 1 under binary classification case
为了方便对比和找出算法优劣的原因,我们也比较了不同 Margin 下目标 Logit 的值:
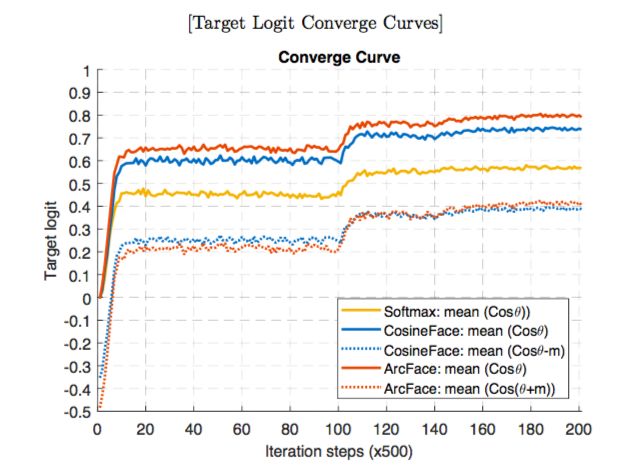
图4: Target logit analysis
3、评测
3.1 验证集 :首先,我们对 3 个 1 比 1 比对的验证集进行测试,网络结构为 LResNet100E- IR,训练数据集 Refined-MS1M,所有结果都为单模型。
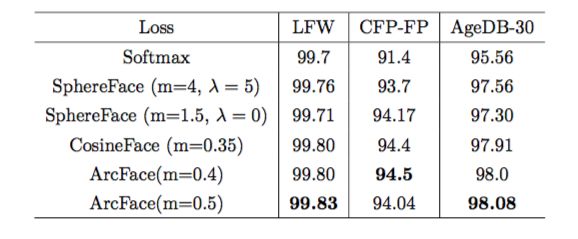
表 3
3.2 MegaFace 百万人脸测试 :需要声明的是,我们对 MegaFace 干扰集做了仔细的比对和清理 (标记 (R)),这样获得的性能才是模型本来的性能,也移除了噪音带来的随机性。参考 SphereFace 和 ArcFace(m=0.4) 在移除噪音前后的性能对比。真实性能 ArcFace(m=0.4) 是好于 SphereFace,但是在移除噪音之前正好相反。
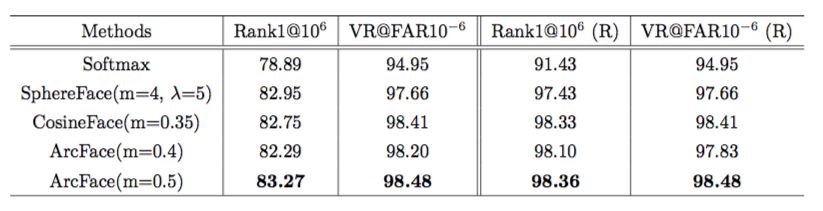
在上面的实验基础上,我们做了更严格的实验:移除所有训练集合中和 probe-set(FaceScrub) 足够相似的人物,得到以下结果:
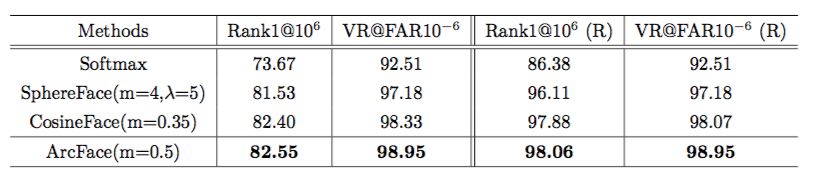
可以看到移除和 probe-set 重复的训练集人物还是有一定影响的,这也符合常理。另外我们也可以看到 ArcFace 和 CosineFace 受到的影响较小。
4、开源库 InsightFace
在我们的开源代码 InsightFace[0] 中,我们提供了 ArcFace 的官方实现,以及其他一系列 Loss 的第三方实现,并支持一键训练。利用项目中提供的 Refined-MS1M 训练数据集,可以轻松达到论文中标称的准确率值。
4.1 安装:在 Linux 下两行命令即可完成安装:pip install six scipy scikit−learn opencv−python scikit −image easydict mxnet−cu80 git clone
4.2 训练:一行命令即可获得最佳的模型: CUDA_VISIBLE_DEVICES= ’0 ,1 ,2 ,3 ’ python −u train_softmax . py −−network r100 −−l −−prefix ../model−r100
4.3 地址:https://github.com/deepinsight/insightface.git
-马上报名学习,挑战百万年薪-

点击“阅读原文”,查看详情

