ICML'21:一种计算用户嵌入表示的新型协同过滤方法
本文介绍今年发表在ICML'21的工作,提出了一种计算推荐系统中用户嵌入表示(embedding)的新方法,有望被用来解决冷启动问题或在线场景中及时处理新用户。方法的核心思想如下:1)对数据集中一部分用户(例如点击数较多的用户)采用传统协同过滤得到嵌入表示;2)利用这些用户的嵌入表示的加权组合去计算其他用户(例如点击数较少的用户或全新的用户)的嵌入表示。这样做的目的是利用一部分well-trained的用户表示去间接计算另一部分few-shot或zero-shot的用户表示(直接计算容易过拟合),从而提升在少样本用户或新用户上的泛化性能。同时,这种表示方法可以实现inductive learning,即模型可以灵活的处理未来出现的新用户,不需要重新训练。
该方法的核心思想很简单,但有严格的理论保障,也在公开数据集上取得了优异的结果。核心思想可以被拓展到其他推荐系统的场景和方法上,也能被用到其他领域去处理一般化的实体表征学习的问题。
论文题目:Towards Open-World Recommendation: An Inductive Model-based Collaborative Filtering Approach
论文链接:https://www.zhuanzhi.ai/paper/ce51881bcc095c542fdc18e21119d4da
代码链接:https://github.com/qitianwu/IDCF
推荐系统背景知识
假设系统包含 个用户与 个物品,他们组成了一个被观测到的交互矩阵 ,这里每一个 表示用户 对物品 的交互记录。常见的交互记录包含评分或是否点击,前者是一个连续值(explicit feedback),后者是0-1值(implicit feedback)。推荐系统的问题可以定义为一个矩阵补全的问题:给定 中的部分观测值,预测其他未被观测的值,即用户未来对物品的评分或是否点击某个商品。
解决上述问题最广泛使用的方法就是协同过滤(model-based collaborative filtering)或矩阵分解(matrix factorization),这二者在文献中经常交替使用。主要思想就是为每一个用户 假设一个待求的 维嵌入表示(embedding),记为 ,同时为每一个物品 也假设一个嵌入向量 。而后,利用二者作为输入来预测用户 对物品 的未来交互 。最后,考虑预测得到的交互矩阵 与真实矩阵 中观测值的部分的距离来衡量误差,即 。学习的过程就是优化所有用户和物品的嵌入表示 , 使得误差最小化:
这里的 可以是向量内积,此时对应经典的矩阵分解;也可以是神经网络,此时学习过程也包含了对 参数的优化。
上面提到的用户嵌入向量 实际上就是对用户id的embedding表示,因为我们可以把每一个用户 表示为一个 维的one-hot向量(只有id对应位置为1,其余都为0),记为 ,把用于表示所有用户的embedding看作一个 维的矩阵 。而后用户 的embedding就是 。这里的 也常被称为用户的one-hot embedding表示。
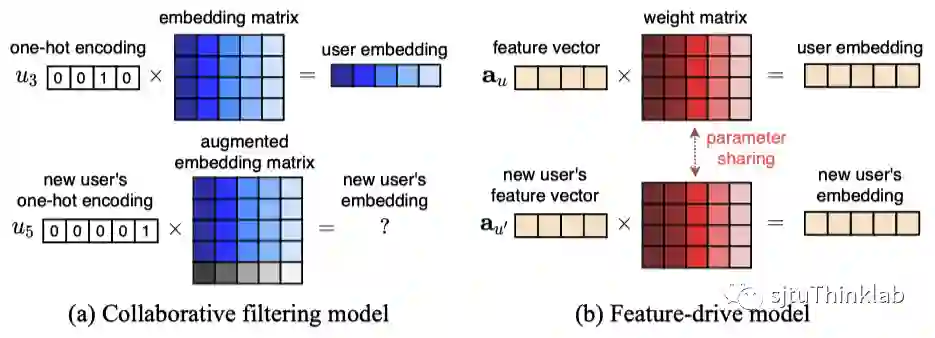
实际的场景中可能还存在用户和物品的属性特征,例如用户的年龄、职业,物品的类别等信息。这些属性特征也可以通过引入一个表示模型(如神经网络)为每个用户计算得到一个嵌入向量,用于预测。然而,基于属性特征的嵌入表示却没有基于id的嵌入表示那么强的表达能力。原因是,基于id的嵌入表示为每个用户单独假设了一个从输入id到embedding的映射关系,而基于属性特征的表示方法所采用的从输入特征到embedding的映射是共享于所有用户的。比如,现实中,相同年龄和职业的用户可能对于电影有完全不一样的喜好,然而推荐模型计算出针对这两个用户的基于属性特征的embedding却是一样的。
(神经)协同过滤/矩阵分解的局限性
虽然基于id的嵌入表示拥有更强大的表达能力,然而它却带来了一个很大的局限性:模型只能处理训练阶段见过的用户,而无法在不进行重新训练的情况下对新用户给出预测。原因是,当测试阶段出现新用户时,所对应的id embedding是全新的,它并没有被训练过,如果直接使用用以预测就会取得很差的性能。然而,要获得比较准确的id embedding,就需要对整个模型在新数据上进行重新训练,这将非常耗时。
因此,可以看到,基于id的嵌入表示与基于属性特征的嵌入表示本身存在一个trade-off。前者具有足够的表达能力,但不能处理新用户,这里使用文献中常用的术语,叫做只能做transductive learning(训练集和测试集必须共享同一部分用户);后者由于映射的共享特性则可以灵活的处理新用户,用于inductive learning(测试集中会出现训练集中没有的新用户),但却不能提供理想的表达能力。下图中的(a)和(b)为这两种方法做了一个直观的对比。
那么,是否存在一种新的用户嵌入表示方法,能够同时提供足够强大的表达能力,又不会限制模型在新用户上的泛化能力呢? 这就是本文主要研究的问题,为此作者提出了一种基于图学习的归纳式协同过滤方法。
基于图学习的归纳式协同过滤/矩阵分解
下图展示了本文提出方法的示意图。
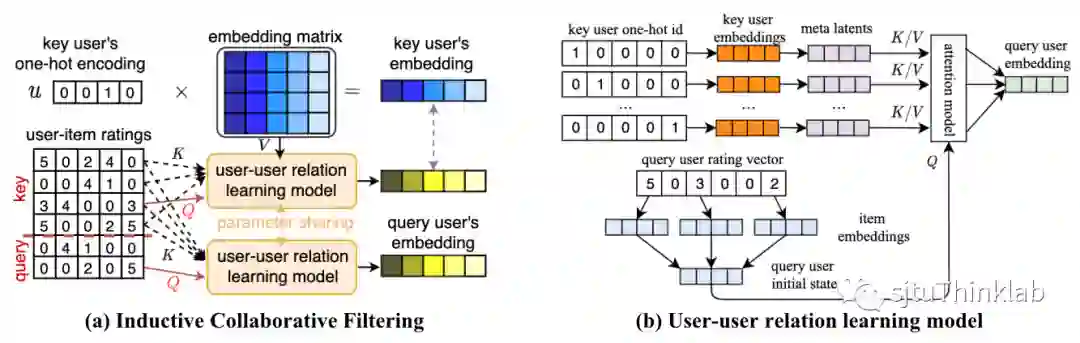
整体思路是:1)将数据集中的用户分为两部分,分别称为key用户和query用户;2)针对key用户利用传统协同过滤方法学习出id embedding;3)针对query用户,学习一个从key用户到query用户的关系图,基于图结构所以定义的近邻关系,利用与之相连的key用户的id embedding来计算query用户对应的嵌入表示。这种表示方法可以灵活处理任何的新用户,并且能够保证足够的表达能力(之后给出理论分析)。
下面是提出方法的符号和公式表达。首先将用户分为两部分,key用户集合 和query用户集合 ,假设key用户数量为 ,query用户数量为 。
-
针对key用户,采用传统的协同过滤方法:假设用户嵌入表示 ,物品的嵌入表示 ,以及预测模型 。真实交互矩阵设为 ,则学习目标为
-
针对query用户,采用一种新的归纳式协同过滤方法:用户 的嵌入表示记为 ,其中向量 表示query用户 对每一个key用户 的注意力权重,由如下公式计算:
这里的 是query用户 的初始表示向量,比如可以通过聚合用户历史点击过的物品的嵌入表示计算得到,或者使用用户的属性特征作为辅助信息。由以上方式得到的用户嵌入表示会被用来计算针对query用户的预测值 ,学习目标表示为(假设 为注意力机制的参数)
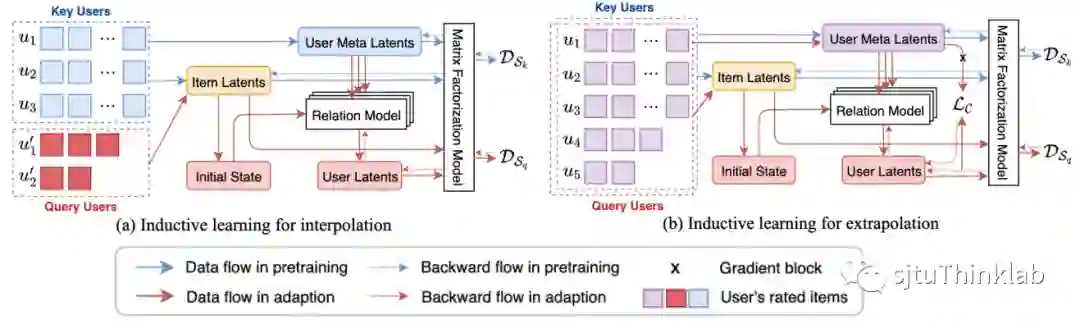
下面介绍模型的训练过程,主要分为两步:1)预训练key用户的id embedding;2)训练用于计算query用户embedding的关系推断模型(即注意力机制)。同时,针对两种情况考虑不同的训练策略。
-
处理few-shot query用户(包含少量训练数据的用户):预训练阶段在key用户的交互数据上训练得到id embedding;第二阶段利用query用户的少量训练数据来更新关系推断模型。
-
处理zero-shot query用户(训练阶段未出现的新用户):预训练阶段在key用户的交互数据上训练得到id embedding;第二阶段将key用户当作假想的“query用户”,即计算每一个key用户对其他key用户的注意力权重,利用关系推断模型得到embedding和预测值,再更新关系推断模型。
下图显示了上述的两种训练策略的更新过程,其中user meta latents表示第一阶段预训练得到的key用户的id embedding。
理论分析:表达能力与泛化能力
有趣的是,可以从数学上证明采用提出的方法得到的用户嵌入表示具有与传统的协同过滤/矩阵分解所得到的id embedding相同的表达能力,具体由以下定理给出。
定理1. 只要当所有key用户的id embedding,即 ,满足列满秩,那么采用归纳式矩阵分解所得到的用户嵌入表示就可以表示任意的 维向量。
这一结果表明,新方法计算得到的嵌入表示具有与传统矩阵分解同样的表达能力。同时, 列满秩的充要条件,是其 个行向量中至少存在一个子集包含了 个线性无关的向量,这一条件很容易被满足(因为 通常远大于 )。
此外,也可以给出在few-shot query用户上的泛化误差上界。
定理2. 假设:1)损失函数 满足 -Lipschitz,2)模型的预测值有界,即 ;3)注意力权重向量 的L1范数不大于 。那么,对于 中任意大小为 的观测子集(即query用户的训练样本集),泛化误差与训练误差的差将以概率 小于上界
上述定理表明,在query用户上的泛化误差主要与key用户数量 ,query用户数量 以及query用户的训练样本数 有关。有趣的是,当key用户数量越多,泛化误差界将越松弛,直观上理解就是key用户增多将导致本文提出的归纳式表示模型的复杂度增加。不过,要满足定理1的条件一般需要key用户数量足够多,覆盖尽可能多样的用户行为。因此,对于key用户的选取就比较关键,会影响模型的表达能力与泛化能力。
实验结果
为了验证提出的方法,考虑在5个公开推荐benchmark数据集展开实验,分别是Douban,Movielens-100K,Movielens-1M,Amazon-Beauty和Amazon-Books。前三个数据集包含用户对电影的评分,属于explicit feedback,采用随机划分的方式将所有评分分为训练集/验证集/测试集,然后统计测试集上的RMSE和NDCG作为评估指标;后两个数据集将用户对商品的反馈记录看作用户与商品的点击交互,可以视作implicit feedback,采用leave-last-out的方法将每个用户的最后10个交互作为测试集,其他为训练集,然后统计测试集上的NDCG和AUC作为评估指标。
对于每个数据集,我们将用户按照历史交互的物品数分为key用户和query用户。例如,对于Movielens-1M数据集,将评分记录数量大于30的归为key用户,其他的为query用户。为了更好的验证模型,考虑两种情形:
-
Interpolation for few-shot users:模型可以利用key和query用户的训练样本来训练,然后在query用户的测试样本上评估。这种场景主要用于评估模型处理少样本学习的能力。此时,本文提出的针对few-shot query用户的方法正好适用。
-
Extrapolation for zero-shot users:模型只能利用key用户的训练样本来训练,随后直接在query用户的测试样本上评估。这种场景主要用于评估模型处理测试阶段出现的新用户的能力。此时,可以使用本文提出的针对zero-shot query用户的方法。
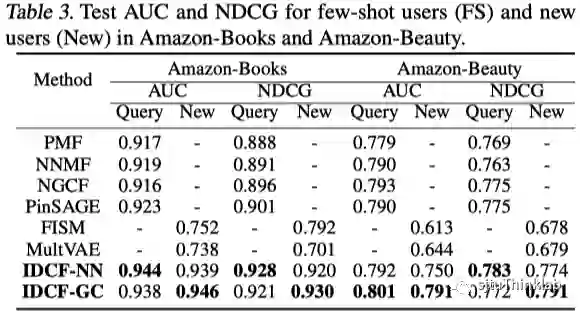
同时,对于本文提出的方法,考虑两种对 的实现方式,即多层感知器MLP和图卷积网络GCN,分别称为IDCF-NN和IDCF-GC。下面是在三个explicit feedback数据集上对few-shot user的评测结果。相比于其他inductive方法,本文提出的两种方法(IDCF-NN和IDCF-GC)在few-shot user上取得了最好的结果,并且十分接近transductive方法(理论上transductive方法性能都要好于inductive方法,因为他们不能处理新用户)。

以及在zero-shot user的评测结果,可以看到本文提出的两种方法显著超越了其他inductive方法(此时transductive方法将无法给出结果),取得了最佳的性能。
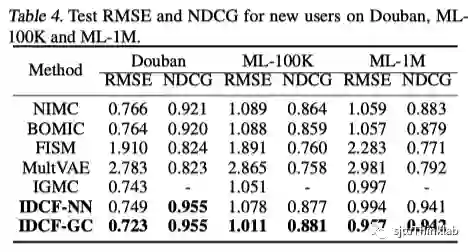
下表展示了在两个implicit feedback数据集的结果,本文的方法在few-shot和zero-shot用户上都取得了最优的效果。
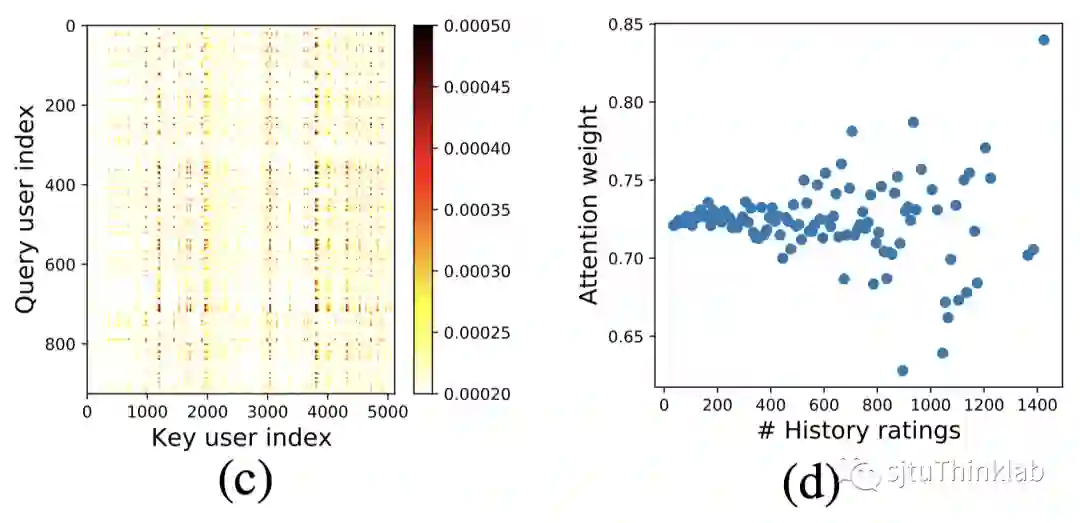
此外,本文还发现,在key用户中存在少部分非常重要的用户,他们贡献了绝大部分的注意力权重,如下图(c)所示。也就是说,大部分query用户的注意力权重都集中在这部分key用户上,这说明这些key用户的id embedding包含了丰富的信息,可以用来表示query用户。当我们绘制出key用户的注意力权重与历史点击数目的二元关系图后(如下图(d)所示),又可以发现随着历史点击数目增加,key用户获得的注意力权重的方差增大。也就是说,对于历史点击数目较多的用户,模型对他们的确信程度更大(更能判断出他们是否有贡献)。
结语
本文的核心思想是利用一部分用户的id embedding来计算另一部分用户的embedding [1],其中利用图结构学习来估计一个用户之间的隐含关系图,沿着图结构进行信息传递从而实现归纳式的表示学习。类似的思想也可以扩展到其他场景。例如,[2]把这种思想扩展到了有属性特征的问题场景,利用训练集中观测到的特征embedding去外推计算测试阶段新出现的特征的embedding,从而解决特征空间扩张的问题。对于更一般的场景,可以利用一部分well-trained的实体表征来计算另一部分few-shot/zero-shot实体的表征,比如拓展类似的思想到其他信息检索场景(如搜索[3]),或处理长尾分布下的词向量或实体表示[4]。
参考文献
[1] Qitian Wu, Hengrui Zhang, Xiaofeng Gao, Junchi Yan, Hongyuan Zha, Towards Open-World Recommendation: An Inductive Model-Based Collaborative Filtering Approach. International Conference on Machine Learning (ICML’21).
[2] Qitian Wu, Chenxiao Yang, Junchi Yan, Towards Open-World Feature Extrapolation: An Inductive Graph Learning Approach, Advances in Neural Information Processing Systems (NeurIPS’21).
[3] T. Wu, E. K. I. Chio, H. Cheng, Y. Du, S. Rendle, D. Kuzmin, R. Agarwal, L. Zhang, J. R. Anderson, S. Singh, T. Chandra, E. H. Chi, W. Li, A. Kumar, X. Ma, A. Soares, N. Jindal, and P. Cao. Zero-shot heterogeneous transfer learning from recommender systems to cold-start search retrieval. In ACM International Conference on Information and Knowledge Management (CIKM'20).
[4] L. Logeswaran, M. Chang, K. Lee, K. Toutanova, J. Devlin, and H. Lee. Zero-shot entity linking by reading entity descriptions. In A. Korhonen, D. R. Traum, and L. Màrquez, editors, Conference of the Association for Computational Linguistics (ACL'19).
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“IDCF” 就可以获取《ICML'21:一种计算用户嵌入表示的新型协同过滤方法》专知下载链接