CVPR 2022 | 快手、北邮提出基于特征组合的域泛化性活体检测算法,多项SOTA
机器之心专栏
作者:快手MMU
在这篇文章中,该研究提出了一个新的网络结构 SSAN,用以实现具有域泛化性的活体检测算法。与过去的方法直接在图像完全表征上提升域泛化性的思路不同,该研究基于内容特征和风格特征在统计特性上的差异,对他们实施不同的处理。该论文已被 CVPR2022 接收。
一:背景和动机
随着各种呈现攻击的不断出现,活体检测算法(Face anti-spoofing)[1] 越来越受到人们的关注。现有的大多数算法都是基于图像的完全表示来实现域泛化性(Domain generalization)[2] 。但是,不同的图像统计信息可能对活体检测任务具有其独特的性质。
具体而言,基于 BN 的结构通常总结图像的全局统计特性,比如语义特征和物理属性等。基于 IN 的结构聚焦于图像具体特性的提取,如活体相关的纹理信息和数据域相关的外部因素。在本文中基于 BN 结构提取的特征称为内容特征,基于 IN 结构提取的特征称为风格特征。利用风格转化的方式,该研究可以在特征层面对不同的内容信息和风格信息进行组合,如图一所示。
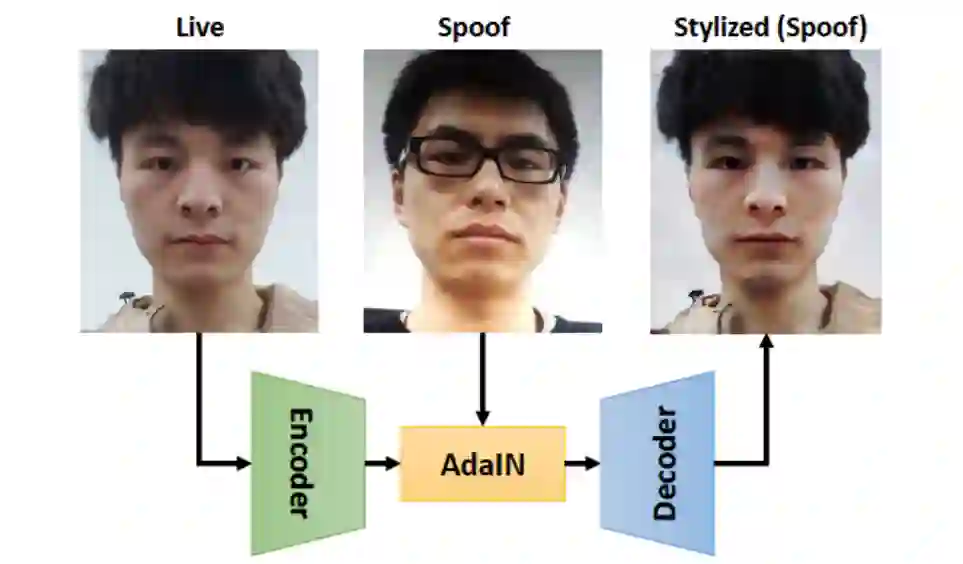
图一:基于方法 [3] 的风格转换示意图,其中该研究将真实人脸作为内容输入,虚假人脸作为风格输入。
在这项工作中,该研究将图像的完全表示分离成内容特征和风格特征,同时提出了 SSAN 网络结构,用于提取不用的内容信息和风格信息。对于内容信息,他们主要记录了一些全局的语义信息和物理属性,因此本文可以使用对抗生成的思想从来自多个域的数据中获得一个共享的内容特征空间。对于风格信息,他们保留了一些具有个体特性的信息,这些信息有利于增强活体与非活体图像之间的差异。不同于方法 [3] 提出的图到图的风格转换方法,本文堆砌了连续的重组风格汇聚层以组合不同的内容和风格特征,以构建出一个重组后的特征空间。然后,为了获得具有泛化性的特征表示,该研究对重组后的特征实施对比学习,用以强调与活体信息相关的风格部分,同时抑制与域信息相关的风格部分。最后,在预测阶段,该研究使用正确的重组特征来区分真实人脸与攻击图像。
另一方面,尽管目前的活体检测算法已经达到了很好的性能,但是由于数据量和数据分布之间的差异,学术届与工业界的评估标准仍存在着很多不同。因此,该研究建立了一个大规模评估协议,提出了单边 TPR@FPR 的评估标准,用以进一步评估算法在现实场景下的性能。该论文已被 CVPR2022 接收。

论文地址:https://arxiv.org/abs/2203.05340
二:方法梗概
本文方法的整体框架如图二所示。首先,本文使用一个双流网络来对图像的内容信息和风格信息进行提取。第二步,一种风格重组的方法被提出,以使不同的内容特征和风格特征进行组合。然后,为了抑制域相关的风格信息,同时增强活体相关的风格信息,本文在重组后的特征空间上使用了对比学习的策略。最后,总的损失函数用来训练所提出的网络。
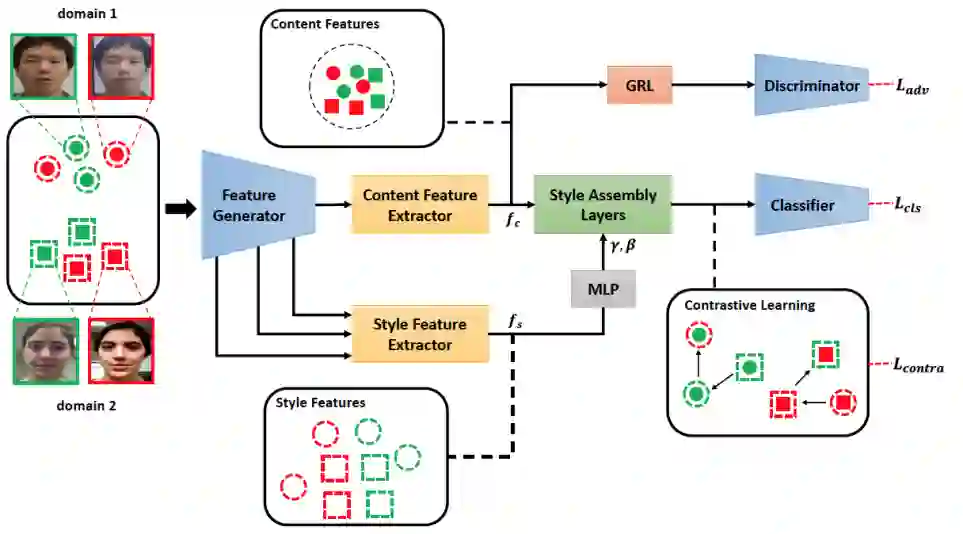
图二:整体网络框架
a) 内容信息和风格信息的聚合
对于内容信息的汇聚,本文基于以下的事实判断他们在不同的数据域中存在着较小的分布差异:1)考虑到来自不用数据域中的样本,他们都包含了人脸的面部区域,因此往往共享一个面部语义空间;2)无论是真实人脸还是攻击图像,他们的物理属性(如形状和大小)通常是相似的,因此本文采用对抗生成式学习,使得汇聚的内容特征不具有域差异。具体而言,内容特征生成器的参数通过最大化对抗损失进行优化,而域鉴别器的参数则通过 GRL [9] 模块以相反的方向进行优化。因此,这一过程可表述如下:
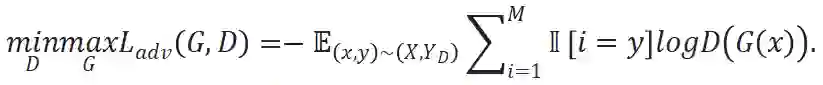
对于风格信息聚合,由于风格信息的范围不同,本文汇集了特征生成器中的多层生成特征,用以捕获更加全面的风格信息。比如,拍摄背景的亮度主要与大范围特征有关,而材料纹理信息则通常集中表现于较小范围的局部区域内。
b) 重组特征操作
在本文的方法中,为了组合内容特征f_c和风格特征f_s,本文利用 AdaIN 层和卷积层建立了特征重组层 SAL,公式描述如下:

其中,

如果输入的 batch 长度为N,x_i表示输入的实例,其中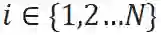
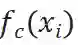
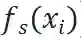
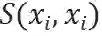
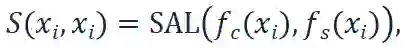
这个公式代表了对从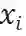
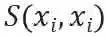
进一步地,为了探究活体相关的风格特征,本文还合成了一个辅助特征空间,通过随机打乱原先的配对关系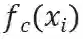
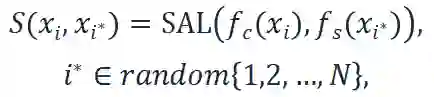
其中random表示随机重新排列,因此
c) 重组特征空间中的对比学习
从风格转换的角度出发,在跨域场景中的一个主要的障碍在于,域相关的风格特征可能会掩盖活体相关的风格特征,这可能会在判决阶段造成错误。为了解决这个问题,本文提出了对比学习的策略来强化活体相关的风格特征,同时抑制域相关的风格特征。
如图三所示,自组合特征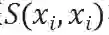
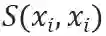
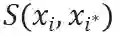
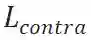
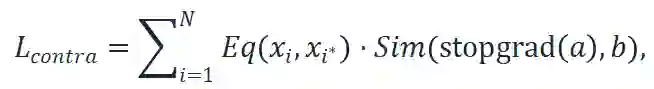
其中,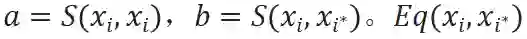
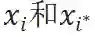
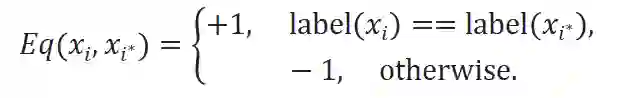
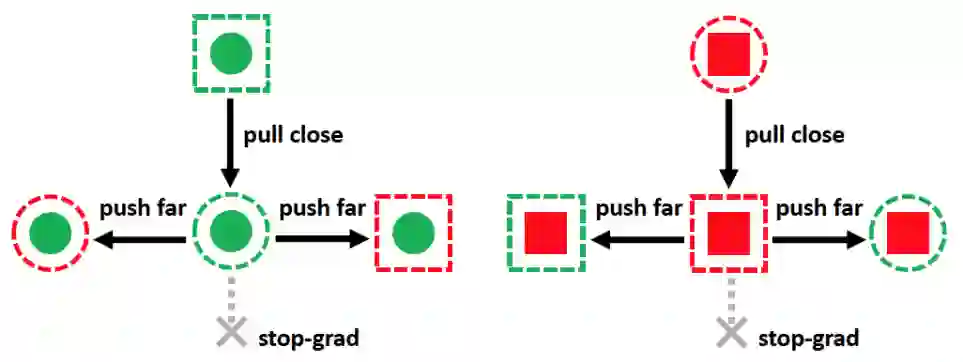
图三:重组特征空间的对比学习
三:活体检测大规模测试协议
目前学术界和工业界存在着一些差异,主要可以总结成如下两个方面。
数据量。与真实场景相比,学术界的数据量仍然太小,这可能会导致模型的过拟合,从而限制了算法的发展。为了克服这个问题,本文合并了十二个公开数据集,然后在此基础上设计了相应的库内和库间测试协议,以进一步评估本文的算法性能。
数据分布和评测指标。在真实场景下的数据分布,真实人脸往往会占有更大的比例,然而,大多数现有的评估协议都会收集数量近似相等的活体与攻击图像来计算平均错误率,用以作为算法评估的结果,这显然与实际的数据分布存在着差异。除此之外,现实场景中的数据通常由不同分布的多个数据域组成,然而,在学术场景中,通常只包含了少量的数据域。为了减小上述的不一致性,在本文提出的协议中,多个数据集聚合在一起作为训练集,多个数据集聚合在一起作为测试集。具体而言,在训练阶段,所有的训练数据被用以优化本文的模型。在测试阶段,由于不同域中真实人脸图像分布的相似性 [2],本文收集了所有数据集中的真实图像作为负样本,将当前进行测量的数据集中的攻击图像作为正样本,然后计算他们在特定 FPR 下的 TPR。最后计算在各个数据集上测试结果的均值和方差作为最后的评价指标。
本文的大规模测试协议使用了十二个公开数据集,他们对应的编号如表一中所示,对应的测试协议设置如下:
协议一:这个协议是库内测试协议。具体而言,所有的数据集都作为训练集和测试集。
协议二:这个协议是跨域测试协议,首先本文将十二个数据集划分成两类,记为 P1 和 P2。具体而言,P1: {D3, D4, D5, D10, D11, D12}, P2: {D1, D2, D6, D7, D8, D9}。因此,该协议也包含着两个子协议,分别是协议 2_1 和协议 2_2。具体而言,协议 2_1 是指用 P1 训练,用 P2 测试。协议 2_2 是指用 P2 训练,用 P1 测试。值得注意的是,跨域测试协议显然更具有挑战性,由于测试集中包含了未知攻击和未知数据域,这与真实世界中的测试场景更为接近。
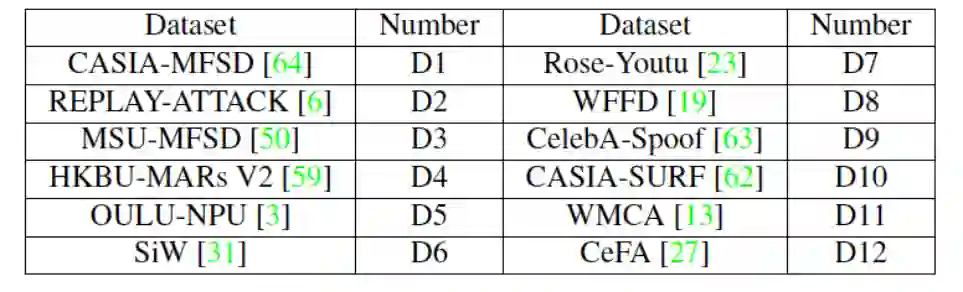
表一:活体检测大协议涉及的数据集及其对应编号
四:实验结果
为了实现全面的评测,本文使用 Leave-One-Out(LOO)的策略在 OULU-NPU、CASIA-MFSD、Replay-Attack 和 MSU-MFSD 数据集上实施跨域测试。具体而言,在这四个数据集中随机选择三个数据集用于训练,并在最后剩下的数据集上进行测试。本文同时将所提出方法的测试结果与目前最佳的 SOTA 方法结果进行对比,如表二所示。观察表中数据可以看出,本文的 SSAN-M 模型在 O&C&I to M, O&M&I to C 和 O&C&M to I 协议上取得了最佳性能,同时在 I&C&M to O 协议上取得了极具竞争力的表现。这些结果证明了本文方法的域泛化性能力。此外,当本文像 SSAN-R 方法那样,使用 ResNet18 作为特征提取器,记为 SSAN-R 模型。可以看出 SSAN-R 模型的性能得到了进一步地提升,并在各个协议上均超过了 SSAN-R 模型。上述的实验结果证明了本文的方法在跨域场景下的有效性。
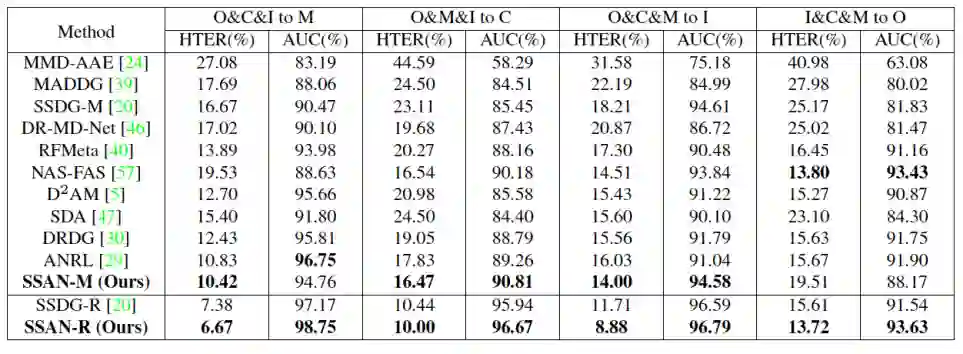
表二:在协议 OCIM 上与其他 SOTA 方法的对比
为了进一步地评估本文的方法在现实场景下的性能表现,本文在提出的大规模活体检测协议上实施所提出的方法,测定各个协议上的实验结果,如表三所示。此外,为了更好地与其他方法进行对比,本文还测定了不同的网络结构(如:CNN [5] 和 Transformer [6])和最近的 SOTA 方法(如:CDCN [7] 和 SSDG [2])在该协议上的表现。从表中的测试结果可以看出,本文的方法展现了最佳的性能,超过了其他的对比方法,这证明了本文的 SSAN 方法在现实场景下的有效性。值得注意的是,虽然有些方法在过去的测试协议(如 OCIM)上取得了很好的性能,但是在这个大规模协议上表现却不及预期。这种现象进一步揭示了,在当下的活体检测问题中,工业界与学术界存在着的差异与分歧。

表三:在活体检测大协议上与其他方法的对比
为了验证本文提出的 SSAN 网络的性能和各个子模块的有效性,本文采用控制变量的方法建立了多个局部模型。所有的结果均在相同的条件下进行测定,结果如表四所示。实验结果证实了本文所提出的各个模块的有效性。
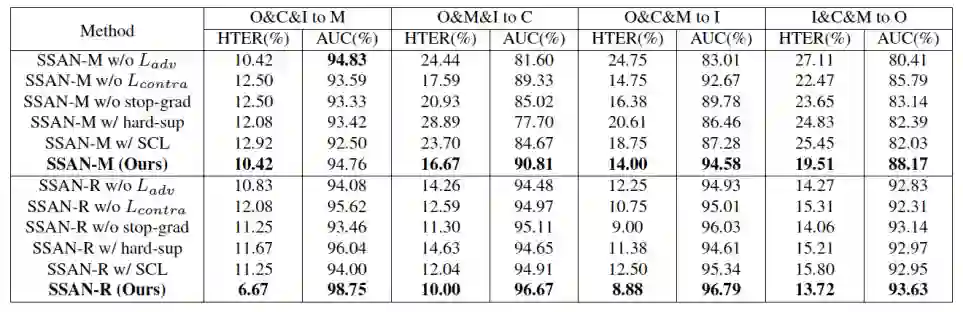
表四:在协议 OCIM 上的消融实验
特征可视化。为了分析本文的 SSAN 方法学到的特征空间,本文使用 t-SNE 算法 [8] 可视化了不同的特征分布,如图四所示。对于内容特征,可以看出他们的分布更加的集中且紧密,虽然他们可能属于不同的数据集或者来自不同的拍摄者。对于风格特征,本文可以看到活体与非活体的例子之间存在着粗糙的分界线,尽管本文没有对他们施加直接的监督。这种现象表明,本文对重组特征空间的对比学习策略能够有效地强化活体相关的风格特征,同时抑制其他不相干的部分,如域相关的风格特征。对于重组后的特征,为了最终活体与非活体之间的分类,本文组合了内容和风格信息。可视化的结果显示了,即使遭遇了未知的数据,本文的方法仍然可以在目标域上展现良好的泛化性。
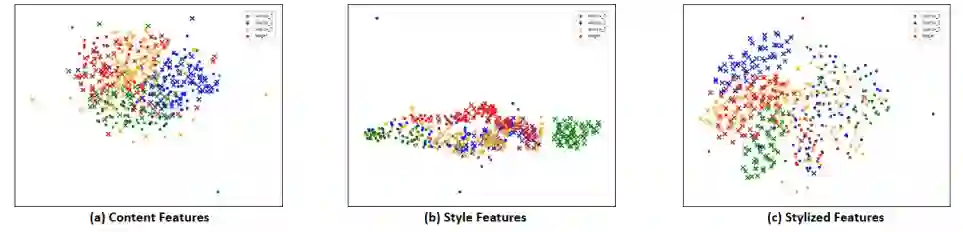
图四:不同特征的分布可视化
五:总结
在这篇文章中,该研究提出了一个新的网络结构 SSAN,用以实现具有域泛化性的活体检测算法。与过去的方法直接在图像完全表征上提升域泛化性的思路不同,该研究基于内容特征和风格特征在统计特性上的差异,对他们实施不同的处理。具体而言,对于内容特征,本文采用了对抗学习的方式,使得网络无法对他们进行数据域层面的区分。对于风格特征,本文使用了对比学习的策略,来强化与活体相关的风格信息,同时抑制域信息相关的部分。然后,本文对配对的内容和风格特征进行组合,构成完全特征表示,并用以最后的分类。
此外,为了弥合学术界与工业界之间的差异,本文通过合并现有的公开数据集,建立了大规模活体检测测试协议。在现有的协议和本文所提出的协议上,所提出的 SSAN 算法均取得了最佳的表现。
参考文献:
[1] Yu Z, Qin Y, Li X, et al. Deep learning for face anti-spoofing: A survey[J]. arXiv preprint arXiv:2106.14948, 2021.
[2] Jia Y, Zhang J, Shan S, et al. Single-side domain generalization for face anti-spoofing[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 8484-8493.
[3] Huang X, Belongie S. Arbitrary style transfer in real-time with adaptive instance normalization[C]//Proceedings of the IEEE international conference on computer vision. 2017: 1501-1510.
[4] Chen X, He K. Exploring simple siamese representation learning[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 15750-15758.
[5] Chen X, He K. Exploring simple siamese representation learning[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 15750-15758.
[6] Touvron H, Cord M, Douze M, et al. Training data-efficient image transformers & distillation through attention[C]//International Conference on Machine Learning. PMLR, 2021: 10347-10357.
[7] Yu Z, Zhao C, Wang Z, et al. Searching central difference convolutional networks for face anti-spoofing[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 5295-5305.
[8] Van der Maaten L, Hinton G. Visualizing data using t-SNE[J]. Journal of machine learning research, 2008, 9(11).
[9] Ganin Y, Lempitsky V. Unsupervised domain adaptation by backpropagation[C]//International conference on machine learning. PMLR, 2015: 1180-1189.
快手 MMU 介绍
快手 MMU(Multimedia understanding) 部门负责快手全站海量音视频、直播的内容理解,在多个技术领域广泛布局,比如视觉方向,在视频、直播、图像的分析和理解、视觉检索、视频生成等技术上有成熟应用和投入;音频方向,在语音识别 & 合成、音乐理解与生成、音频前端与分类等技术上达到行业先进水平,同时也有知识图谱、NLP、智能创作、内容商业价值理解等多种能力,为实现跨模态内容理解奠定坚实基础。

MMU 为快手生态提供 500 + 智能服务,应用在搜索、推荐、生态分析、风险控制等诸多场景。团队拥有业内最顶尖的算法工程师和应用工程师,持续招募相关领域技术人才,博士占比 15%,硕士及以上占比 95%,拥有人工智能领域专利 394 件,每年发表论文数十篇。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com

