众筹超算直播训练1760亿参数AI大模型,九百工程师搞开源

来源:机器之心
本文为约2693字,建议阅读5分钟
本文介绍
了BigScience 模型相关观点。
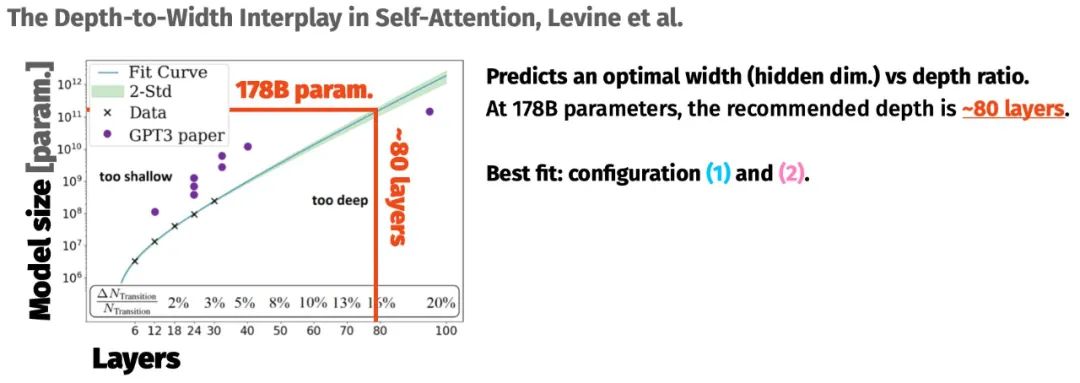
如果你有 100 万个 GPU hour,你会训练什么样的语言模型?

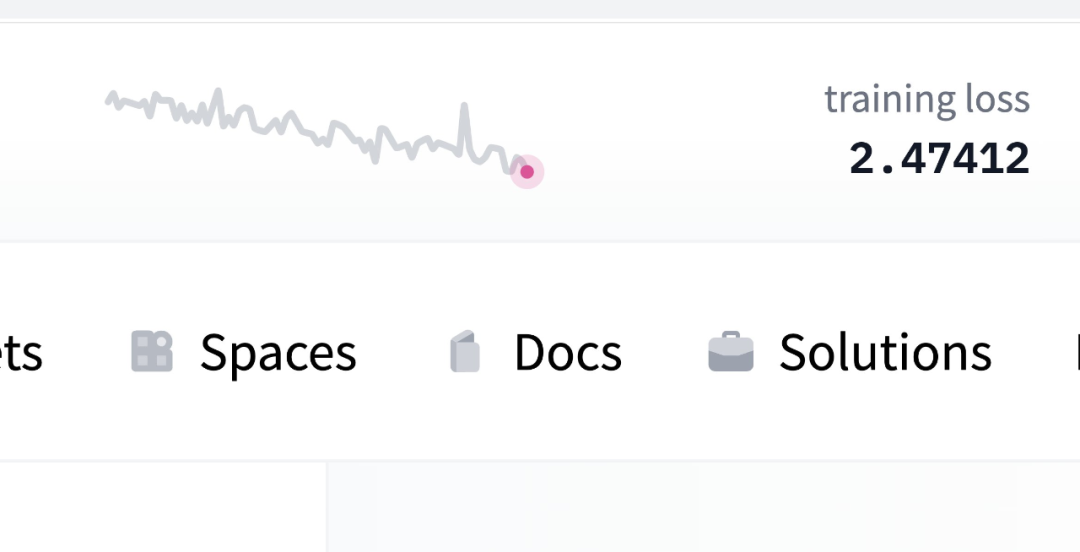
与 GPT 类似,它是一个只包含解码器(decoder-only)的架构,参数量达到了 1760 亿;
70 层的神经网络,每层 112 个注意力头 - 隐藏维度为 14336 - 2048 个 token 序列长度;
ALiBi 位置嵌入 - GeLU 激活函数。


数据治理小组帮助定义了指导数据工作的具体价值,并提出了一个新的国际数据治理结构,包括一些支持性的技术和法律工具;
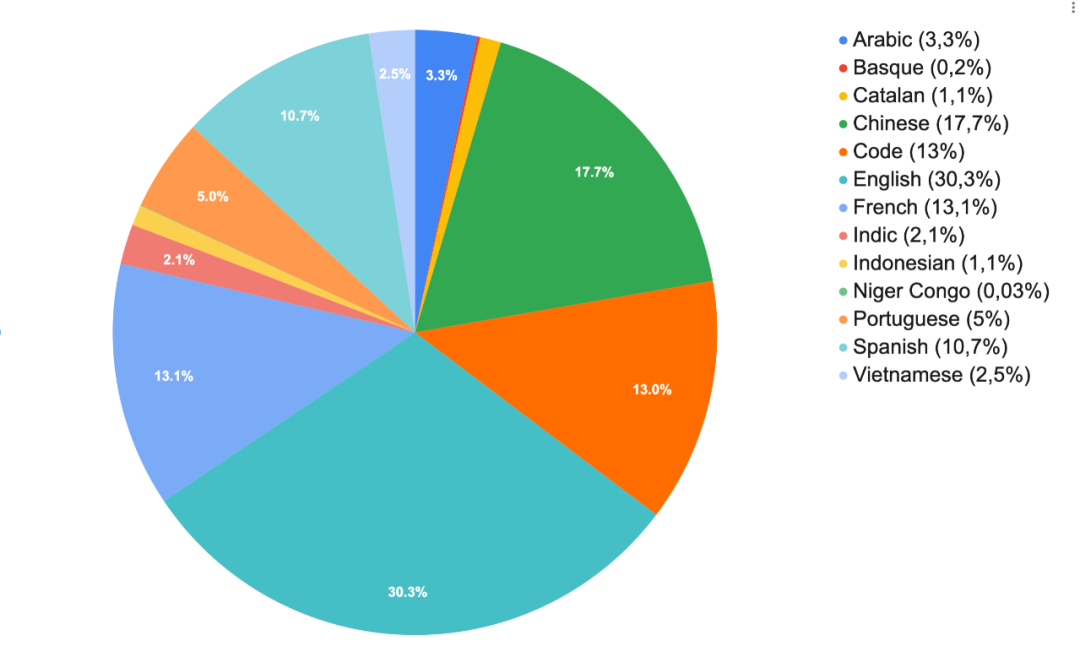
数据来源小组在全球范围内组织黑客松,帮助参与者利用当地专业知识建立了 246 种语言资源目录,并准备了 605 个相关网站的列表;
隐私工作小组致力于分类和策略,以降低隐私风险;
法律学术小组开发了一套涵盖九个司法管辖区的法律手册,其中包含不同的隐私和数据保护法规,以帮助 ML 从业者了解他们工作的法律背景。

登录查看更多
相关内容

专知会员服务
24+阅读 · 2022年3月19日
专知会员服务
54+阅读 · 2020年2月4日
Arxiv
0+阅读 · 2022年4月15日




相关VIP内容
专知会员服务
24+阅读 · 2022年3月19日
专知会员服务
54+阅读 · 2020年2月4日
相关资讯
相关论文
Arxiv
0+阅读 · 2022年4月15日