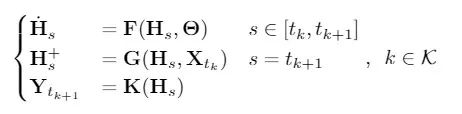瑞利-贝纳德对流(Rayleigh–Bénard Convection)。利用有限元方法将空间上连续的问题离散化,将复杂的关系归纳偏差显示为实体集合。
图源:https://www.youtube.com/watch?v=OM0l2YPVMf8&t=74s.
多智能体系统被广泛应用于各种不同的科学领域:从物理学到机器人学、博弈论、金融学和分子生物学等等。通常来说,预测或决策任务依赖于具有噪声且无规则采样的的观测,因此封闭形式的分析公式对此是无效的。
这类系统对关系归纳偏差提供了生动形象的样例。在样本统计或机器学习过程中引入归纳误差,是一种普遍用于提高样本有效性和泛化性的方式。从目标函数的选择到适合某项具体问题的自组织深度学习的框架设计,设定偏差也是非常常见且有效的方式。
关系归纳偏差[1]代表一类特殊的偏差,涉及实体之间的关系。无论是图形模型、概率模型还是其他模型,都是一类专门对实体施加先验结构形式的关系偏差的传统模型。这些图形结构能够在不同领域中发挥作用,它可以通过引入条件独立性假设来降低计算复杂度,也可以通过将先验知识编码为图的形式来增强样本的有效性。
图神经网络(GNN)是图模型对应的深度学习网络。GNN 通常会在这两种情况中使用:一是当目标问题结构可以编码为图的形式;二是输入实体间关系的先验知识本身可以被描述为一张图。
GNN 在许多应用领域都展示了显著的效果,例如:节点分类[2]、图分类、预测[3][4]以及生成任务[5]。
一、深度学习中的常微分方程
一种类型不同但重要性相等的归纳偏差与收集到数据所使用系统的类别相关。尽管从传统上看,深度学习一直由离散模型主导,但在最近的研究提出了一种将神经网络视为具有连续层的模型[6]的处理方法。
这一观点将前向传播过程,重定义为常微分方程(ODE)中初值求解的问题。在这个假设下,可以直接对常微分方程进行建模,并可以提高神经网络在涉及连续时间序列任务上的性能。
《Graph Neural Ordinary Differential Equations》这项工作旨在缩小几何深度学习和连续模型之间的差距。图神经常微分方程(Graph Neural Ordinary Differential Equations ,GDE)将图结构数据上的一般性任务映射到一个系统理论框架中。我们将常见的图结构数据放入系统理论框架中,比如将数据结构化到系统中:
无论 GDE 模型的结构是固定还是随时间变化的,它都可以通过为模型配备连续的 GNN 图层来对定义在图上的向量场建模。
GDE 模型由于结构由连续的 GNN 层定义,具备良好的灵活性,可以适应不规则序列样本数据。
GDE 模型的主要目的是,提供一种数据驱动的方法为结构化系统建模,特别是当这个动态过程是非线性时,更是难以用经典的分析方法进行建模。
下面是对GDE的介绍。关于更多细节和推导,请参阅原论文,论文相关链接如下:
-
https://arxiv.org/abs/1911.07532
目前我们正在开发一个用于介绍GDE模型的 Github Repository(仓库),其中包含使用 Jupyter notebook 且带有注释的相关示例,Github 相关地址如下:
-
https://github.com/Zymrael/gde
据悉,我们正计划将它最终部署成具有不同功能的设置(包括预测、控制…),其中包括所有主要图形神经网络(GNN)架构下不同 GDE 变体的工作示例。
二、GDE 要了解的两点基本知识
GDE 和 GNN 一样,都是在图上进行操作。关于符号和基本定义更详细的介绍,我们参阅了关于 GNN 的优秀的相关综合研究(相关研究链接为:
https://arxiv.org/abs/1901.00596
)以及原论文中的背景部分。
下面,我们将对 GDE 进行简要的介绍,不过实际上,只有下面两点关于图的基本知识是我们即将需要了解到的:
-
1、图是由边连接的互连节点(实体)的集合。深度学习模型通常处理用一组特征(通常以一组向量或张量)描述节点的属性图。对于 n 个节点的图,每个节点都可以用 d 个特征描述,最后我们将这 n x d 个节点嵌入矩阵表示为 H。
-
2、图的结构由其邻接矩阵 A 捕获。节点之间的连通结构表现出标准深度学习模型和GNN模型之间的主要区别[1],因为GNN直接以各种方式利用它对节点嵌入进行操作。
三、图神经常微分方程
其中,H 是节点特征矩阵。上式中定义了函数 F 参数化的 H 的向量场,其中函数 F 可以是任意已知的图神经网络(GNN)层。
换句话说,F 利用图 G 节点的连接信息及其节点特征来描述 H 在 S 中的变化过程。其中,S 是模型的深度域;不同于 GNN 由自然数的子集来指定的深度域,S 是连续的,它表示由函数 F 定义的常微分方程的积分域。
GDE 可以通过多种方式进行训练,这一点很像标准的神经常微分方程[6]。原论文中也对系统的适定性进行了详细阐释和讨论。
一般的 GDE 公式带有几种含义。在一般神经常微分方程中,观察到选择离散化方案可以对 ResNets(残差网络)已知的先前离散多步骤变量进行描述[7]。因此,深度学习中连续动态系统的观点不仅局限于微分方程的建模,而且可以利用丰富的数值方法相关文献来指导发现新的通用模型。
与 ResNets 相比,GNN 作为一个模型类别来说算是相对年轻的。因此,关于多步骤的复杂变体以及类似分形残差连接的相关文献发展得并没有那么完善;而我们可以发现一些新的 GNN 变体是通过应用GDE的各种离散化方案来指导的,而不是完全从头开始。
通过在 Cora、Pubmed 和 Citeseer 上进行一系列半监督节点分类实验,证明 GDE 可以作为高性能的通用模型。这些数据集包含静态图,其中邻接矩阵 A 保持不变,从而使其远离运用GDE的动态系统设置。我们评估图卷积常微分方程(GCDE)的性能,定义为:
GCDE模型。在我们的论文中包含了一个更加详细的版本,以及一些GNN流行的GDE变体版本。
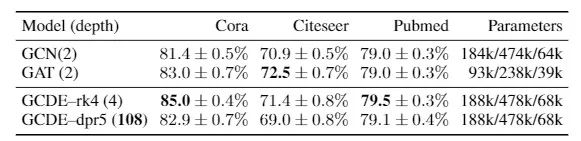
它们的完全离散的形式对应图卷积网络(GCN)[8]。我们参考了包括著名的图注意力网络(GAT)[9]在内的文献作为参考:
节点分类任务的准确性。上表取值为100次运行的平均值和标准偏差。
GCDE 被证明可以媲美最先进的模型,并且优于它们的离散模型。我们评估了如下两种 GCDE的版本:
-
一种是离散的固定步长的方案,采用 Runge-Kutta4(GCDE-rk4);
-
另一种是自适应步长方案,采用 Dormand-Prince(GDDE-dpr5)。
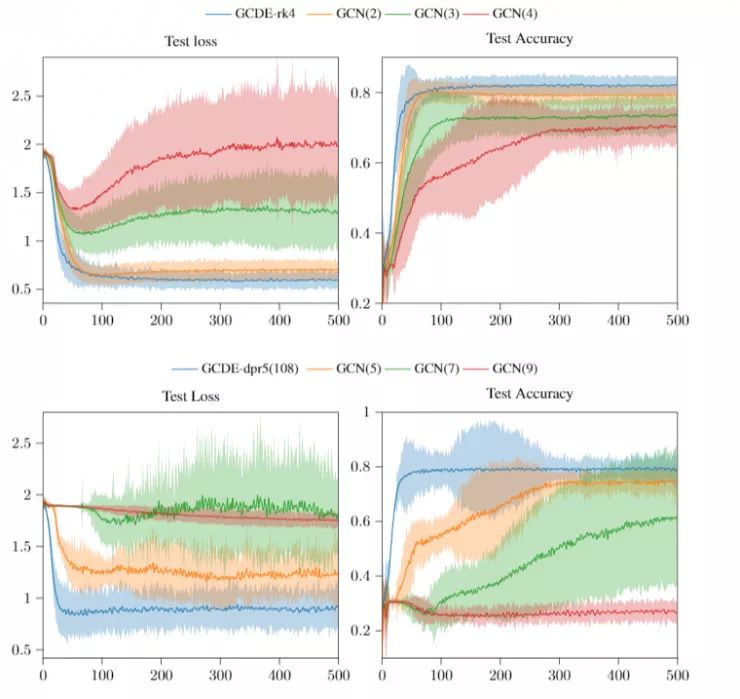
固定步长的离散方案并不能保证 ODE 近似仍然接近解析解;在这种情况下,求解一个适当的 ODE 是不必要的,GCDE—rk4能够提供一个计算效率高的类子结构的FractalNet(比如GCN模型的结构)来提高准确率。
如图为Cora的训练损失和准确率,其中阴影区域是95%置信区间
另一方面,使用自适应步长解算器训练 GCDE 自然会比使用 vanilla GCN 模型的深度更深,后者网络层的深度使该网络性能大大降低。
实验中我们成功地训练了GCDE-dpr5,它有多达200个ODE函数评估(NFE),这使得它对图中的计算量明显高于vanilla GCN(由于层数太深使得性能大幅度降低)。应该注意的是,由于GDE在求解函数中会对参数重利用,它比对应的离散项需要更少的参数。
有趣的是,自适应步长GDE似乎不受节点特征过度平滑的影响。过度平滑问题[10]阻碍了深层GNN在各个领域的有效使用,特别是在多智能体强化学习(MARL)中,我们目前正在积极探索GDE这一特性,并能够很快进行更为详细的分析。
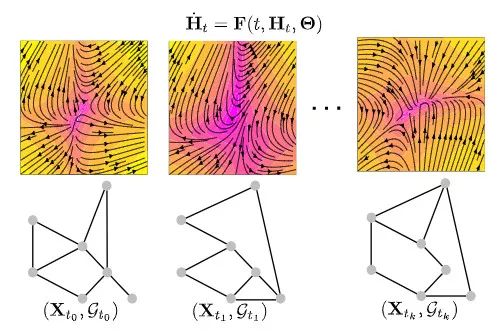
四、时空 GDE
GDE 中一项关键的设定涉及到时空图数据信息。在处理图的序列信息时,需要用到 GNN 的递归版本 [11][12]。
然而, 与常规的递归神经网络(RNN)及其变体一样,在固定的离散度的情况下不允许其对不规则的样本数据进行操作。这一事实进一步推动了基于到达次数之间的变动的先验假设下 RNN 形式的发展,比如 RNN 的 ODE 版本 [14] 。
在涉及时间分量的场景中,GDE 中 S 的深度域与时间域一致,并且可以根据需求进行调整。例如,给定时间窗口 Δt,使用 GDE 进行预测的公式形式如下:
尽管拥有特殊的结构,GDE 代表了一类图序列的自回归模型,以混合动态系统的形式自然地通往扩展的经典时空结构,比如:以时间连续和时间离散的动力学相互作用为特征的系统。
它的核心思想是,让一个 GDE 在两种时间点之间平滑地控制潜在的节点特征,然后应用一些离散算子,让节点特征 H 快速移动,接着由输出层来处理这些节点特征 H 。
给定一系列的时间常数
![]() 以及一种数据的状态——图数据信息流
以及一种数据的状态——图数据信息流
![]() ,自回归 GDE 的一般公式为:
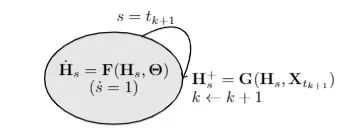
如图为自回归GDE。拥有已知连续变量的时空GNN模型可以通过从这个系统中通过选择合适的F,G,K参数来获得。
其中,参数 F,G,K 是类似于 GNN 的操作或者一般的神经网络层,H+表示经过离散变换后的 H 值。该系统的转变过程可以通过混合自动机进行可视化处理:
与只具有离散跳跃的标准递归模型相比,自回归 GDE 在跳跃间包含了一个潜在特征节点的连续流 H。自回归 GDE 的这一特性使它们能够从不规则的观测结果中来跟踪动态系统。
F,G,K 的不同组合可以产生最常见的时空 GNN 模型的连续变量。
为了评估自回归 GDE 模型对预测任务的有效性,我们在建立的 PeMS 流量数据集上进行了一系列实验。我们遵循文献[15]的实验预设参数,并且附加了一个预处理步骤:对时间序列进行欠采样,为了模拟在具有不规则时间戳或有缺失值等具有挑战性的环境,这里将每个输入以 0.7 的概率进行删除。
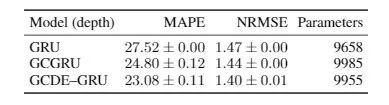
为了在由连续时间系统生成的数据设置中测量 GDE 获得的性能提升,我们使用 GCDE-GRU 及其对应的离散 GCGRU[12],并将结果置于 vanilla GRU 度量标准中进行测量。
对于所考虑的每个模型,我们收集了标准化 RMSE(NRMSE)和平均绝对百分比误差(MAPE)结果。关于所选指标和数据的更多细节请参见原论文。
由于在训练和测试过程中平均的预测时间范围会发生急剧变化,这种时间戳之间的非恒定差异导致单个模型的预测任务更加具有挑战性。为更加公平的对模型进行比较,我们将增量时间戳信息作为 GCGN 和 GRU 的附加节点特征。
不规则数据预测任务的结果。此处取5次训练的平均值和标准差。
由于 GCDE-GRU 和 GCGRU 的设计在结构和参数数量上是匹配的,我们可以在 NRSME 中测量到 3% 的性能增长,在MAPE中测量到7%的性能增长。
对具有连续动态和不规则数据集的其他应用领域采用 GDE 作为建模工具,也将同样使其拥有优势,例如在医学、金融或分布式控制系统等领域。我们正在这些领域进行另外的一些相关实验,欢迎提出任何要求、想法或合作意见。
,自回归 GDE 的一般公式为:
如图为自回归GDE。拥有已知连续变量的时空GNN模型可以通过从这个系统中通过选择合适的F,G,K参数来获得。
其中,参数 F,G,K 是类似于 GNN 的操作或者一般的神经网络层,H+表示经过离散变换后的 H 值。该系统的转变过程可以通过混合自动机进行可视化处理:
与只具有离散跳跃的标准递归模型相比,自回归 GDE 在跳跃间包含了一个潜在特征节点的连续流 H。自回归 GDE 的这一特性使它们能够从不规则的观测结果中来跟踪动态系统。
F,G,K 的不同组合可以产生最常见的时空 GNN 模型的连续变量。
为了评估自回归 GDE 模型对预测任务的有效性,我们在建立的 PeMS 流量数据集上进行了一系列实验。我们遵循文献[15]的实验预设参数,并且附加了一个预处理步骤:对时间序列进行欠采样,为了模拟在具有不规则时间戳或有缺失值等具有挑战性的环境,这里将每个输入以 0.7 的概率进行删除。
为了在由连续时间系统生成的数据设置中测量 GDE 获得的性能提升,我们使用 GCDE-GRU 及其对应的离散 GCGRU[12],并将结果置于 vanilla GRU 度量标准中进行测量。
对于所考虑的每个模型,我们收集了标准化 RMSE(NRMSE)和平均绝对百分比误差(MAPE)结果。关于所选指标和数据的更多细节请参见原论文。
由于在训练和测试过程中平均的预测时间范围会发生急剧变化,这种时间戳之间的非恒定差异导致单个模型的预测任务更加具有挑战性。为更加公平的对模型进行比较,我们将增量时间戳信息作为 GCGN 和 GRU 的附加节点特征。
不规则数据预测任务的结果。此处取5次训练的平均值和标准差。
由于 GCDE-GRU 和 GCGRU 的设计在结构和参数数量上是匹配的,我们可以在 NRSME 中测量到 3% 的性能增长,在MAPE中测量到7%的性能增长。
对具有连续动态和不规则数据集的其他应用领域采用 GDE 作为建模工具,也将同样使其拥有优势,例如在医学、金融或分布式控制系统等领域。我们正在这些领域进行另外的一些相关实验,欢迎提出任何要求、想法或合作意见。
五、结论
如上所述,我们目前正在开发一个Github 库,其中包含一系列针对 GDE 模型不同类型的示例和应用程序。
我们鼓励大家对GDE的其他应用程序在Github中进行请求/建议操作:我们计划它最终可以包括所有主流图神经网络(GNN)架构的GDE变体的相关工作示例,部署在各种设置(预测、控制…)之中。
我们的论文可以在arXiv上作为预印本:如果您觉得我们的工作有用,请考虑引用我们的论文。
参考文献
[1] P. W. Battaglia et al. Relational inductive biases, deep learning, and graph networks. arXiv preprint arXiv:1806.01261, 2018.
[2] J. Atwood and D. Towsley. Diffusion-convolutional neural networks. In Advances in Neural Information Processing Systems, pages 1993–2001, 2016.
[3] Z. Cui, K. Henrickson, R. Ke, and Y. Wang. Traffic graph convolutional recurrent neural network: A deep learning framework for network-scale traffic learning and forecasting. arXiv preprint arXiv:1802.07007, 2018
[4] J. Park and J. Park. Physics-induced graph neural network: An application to wind-farm power estimation.Energy, 187:115883, 2019.
[5] Li, O. Vinyals, C. Dyer, R. Pascanu, and P. Battaglia. Learning deep generative models of graphs. arXiv preprint arXiv:1803.03324, 2018.
[6] T. Q. Chen, Y. Rubanova, J. Bettencourt, and D. K. Duvenaud. Neural ordinary differential equations. In Advances in neural information processing systems, pages 6571–6583, 2018.
[7] Y. Lu, A. Zhong, Q. Li, and B. Dong. Beyond finite layer neural networks: Bridging deep architectures and numerical differential equations. arXiv preprint arXiv:1710.10121, 2017.
[8] T. N. Kipf and M. Welling. Semi-supervised classification with graph convolutional networks. arXiv preprint arXiv:1609.02907, 2016.
[9] P. Velickovic, G. Cucurull, A. Casanova, A. Romero, P. Lio, and Y. Bengio. Graph attention networks. arXiv preprint arXiv:1710.10903, 2017.
[10] Chen, Deli, et al. “Measuring and Relieving the Over-smoothing Problem for Graph Neural Networks from the Topological View.” arXiv preprint arXiv:1909.03211 (2019).
[11] Y. Li, R. Yu, C. Shahabi, and Y. Liu. Diffusion convolutional recurrent neural network: Data-driven traffic forecasting. arXiv preprint arXiv:1707.01926, 2017
[12] X. Zhao, F. Chen, and J.-H. Cho. Deep learning for predicting dynamic uncertain opinions in network data. In 2018 IEEE International Conference on Big Data (Big Data), pages 1150–1155. IEEE, 2018.
[13] Z. Che, S. Purushotham, K. Cho, D. Sontag, and Y. Liu. Recurrent neural networks for multi-variate time series with missing values.Scientific reports, 8(1):6085, 2018.
[14] Rubanova, R. T. Chen, and D. Duvenaud. Latent odes for irregularly-sampled time series. arXiv preprint arXiv:1907.03907, 2019.
[15] B. Yu, H. Yin, and Z. Zhu. Spatio-temporal graph convolutional networks: A deep learning framework for traffic forecasting. In Proceedings of the 27th International Joint Conference on Artificial Intelligence (IJCAI), 2018.
via
https://towardsdatascience.com/graph-neural-ordinary-differential-equations-a5e44ac2b6ec
![]()
![]()
AI 科技评论希望能够招聘 科技编辑/记者 一名
办公地点:北京
职务:以参与学术顶会报道、人物专访为主
工作内容:
1、参加各种人工智能学术会议,并做会议内容报道;
2、采访人工智能领域学者或研发人员;
3、关注学术领域热点事件,并及时跟踪报道。
要求:
1、热爱人工智能学术研究内容,擅长与学者或企业工程人员打交道;
2、有一定的理工科背景,对人工智能技术有所了解者更佳;
3、英语能力强(工作内容涉及大量英文资料);
4、学习能力强,对人工智能前沿技术有一定的了解,并能够逐渐形成自己的观点。
感兴趣者,可将简历发送到邮箱:jiawei@leiphone.com
![]()
![]() 点击“阅读原文” 观看 AAAI 2020 论文预讲直播视频
点击“阅读原文” 观看 AAAI 2020 论文预讲直播视频

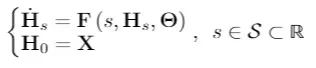
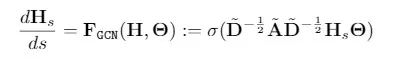
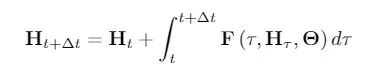
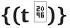 以及一种数据的状态——图数据信息流
以及一种数据的状态——图数据信息流
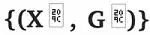 ,自回归 GDE 的一般公式为:
,自回归 GDE 的一般公式为: