RTX 3090 AI性能实测:FP32训练速度提升50%,张量核心缩水
晓查 发自 凹非寺
量子位 报道 | 公众号 QbitAI
NVIDIA最近发布了备受期待的RTX 30系列显卡。
其中,性能最强大的RTX 3090具有24GB显存和10496个CUDA核心。而2018年推出的旗舰显卡Titan RTX同样具有24GB显存。
Titan RTX |
RTX 3090 |
|
架构 |
图灵TU102 |
安培GA102 |
CUDA核心 |
4609 |
10496 |
张量核心 |
576 |
328 |
显存 |
24GB |
24GB |
显存带宽 |
672GB/s |
936GB/s |
TDP |
285W |
350W |
RTX 3090在深度学习训练任务中,性能表现究竟如何,它能否取代Titan RTX成为最强消费级AI训练卡?现在已经有了答案。
国外两位AI从业者在拿到这款显卡后,第一时间测试了其在TensorFlow上的AI训练性能。

由于RTX 3090现阶段不能很好地支持TensorFlow 2,因此先在TensorFlow 1.15上进行测试。
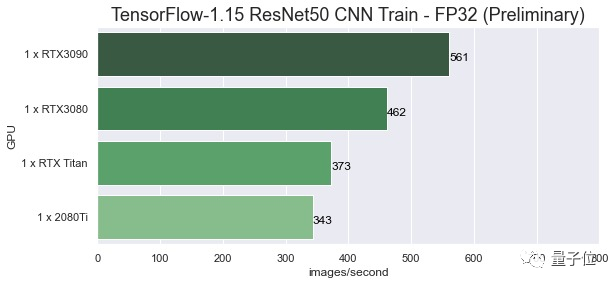
话不多说,先看数据。在FP32任务上,RTX 3090每秒可处理561张图片,Titan RTX每秒可处理373张图片,性能提升50.4%!
而在FP16任务上,RTX 3090每秒可处理1163张图片,Titan RTX每秒可处理1082张图片,性能仅提升7.5%。
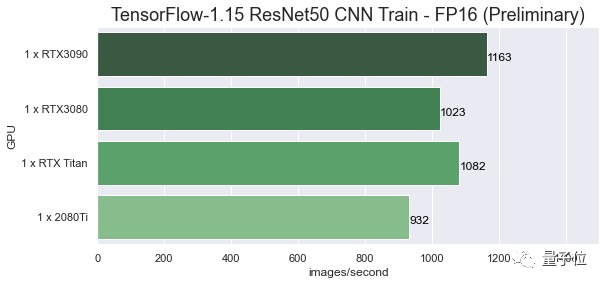
为何在FP32任务上的性能提升比在FP16上更明显,主要是因为RTX 3090大大提高了CUDA核心的数量。但是用于处理FP16的张量核心数量明显减少,这可能会影响FP16性能。
即便如此,张量核心更少的RTX 3090在很多FP16任务上,性能依然有小幅提升。
随后,英伟达官方提供了支持RTX 3090的CUDA 11.1,谷歌官方在TensorFlow nightly版中提供了对最新显卡的支持。
又有用户再次测试了两款显卡的性能对比。
FP16 |
FP32 |
|||
Titan RTX |
RTX 3090 |
Titan RTX |
RTX 3090 |
|
AlexNet |
6634 |
8255 |
4448 |
6493 |
Inception3 |
656.1 |
616.3 |
223 |
337.3 |
Inception4 |
298.1 |
132.7 |
99.74 |
143.7 |
ResNet152 |
423.9 |
484 |
134.5 |
203.6 |
ResNet150 |
966.8 |
1260 |
336 |
525.9 |
VGG16 |
339.7 |
442.5 |
212.1 |
325.6 |
△ 训练性能:每秒处理的图片数量
可以看出,使用FP32进行的所有模型训练,RTX 3090都能实现40%~60%的训练提升。而大多数模型的FP16训练速度几乎不变,最多提升20%,甚至在Inception模型上还有所下降。
只能说RTX 3090在张量核心上的“刀法”颇为精准,如果你对FP16训练性能有较高要求,也许可以等待今后的升级版。
不过RTX 3090上市价格仅1499美元,比Titan RTX便宜1000美元,仍不失为“性价比”之选。
参考链接:
https://www.pugetsystems.com/labs/hpc/RTX3090-TensorFlow-NAMD-and-HPCG-Performance-on-Linux-Preliminary-1902/
https://www.evolution.ai/post/benchmarking-deep-learning-workloads-with-tensorflow-on-the-nvidia-geforce-rtx-3090
— 完 —
本文系网易新闻•网易号特色内容激励计划签约账号【量子位】原创内容,未经账号授权,禁止随意转载。
榜单征集!7大奖项锁定AI TOP企业


量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
一键三连「分享」、「点赞」和「在看」
科技前沿进展日日相见~



