首个Titan RTX深度学习评测结果出炉:2019年你该选择哪款GPU?
选自 Lambda
作者:Michael Balaban
机器之心编译
参与:李亚洲、李泽南
英伟达的新一代 GPU 旗舰 Titan RTX 用来跑深度学习速度如何?近日,AI 硬件供应商 Lambda Labs 对 Titan RTX,以及 RTX 2080 Ti 等常见 GPU 在各种深度学习训练任务上的训练速度进行了测试。
结果喜人,由于新一代的英伟达 GPU 使用了 12 纳米制程的图灵架构和 Tensor Core,在深度学习图像识别的训练上至少能比同级上代产品提升 30% 的性能,如果是半精度训练的话最多能到两倍。看起来,如果用来做深度学习训练的话,目前性价比最高的是 RTX 2080Ti 显卡(除非你必须要 11G 以上的显存)。
Lambda 借助 TensorFlow 对以下 GPU 进行了测试:
Titan RTX
RTX 2080 Ti
Tesla V100 (32 GB)
GTX 1080 Ti
Titan Xp
Titan V
注意,作者只对单 GPU 对常见神经网络的训练速度进行了测试。
结果总结
我们测试了在训练神经网络 ResNet50、ResNet152、Inception3、Inception4、VGG16、AlexNet 和 SSD 时,以下每个 GPU 每秒处理的图像数量。
在 FP 32 单精度训练上,Titan RTX 平均:
比 RTX 2080Ti 快 8%;
比 GTX 1080Ti 快 46.8%;
比 Titan Xp 快 31.4%;
比 Titan V 快 4%;
比 Tesla V100(32 GB)慢 13.7%。
在 FP 16 半精度训练上,Titan RTX 平均:
比 RTX 2080 Ti 快 21.4%;
比 GTX 1080 Ti 快 209.7%;
比 Titan Xp 快 192.1%;
比 Titan V 慢 1.6%;t
和 v100(32 GB)的对比还有待调整。
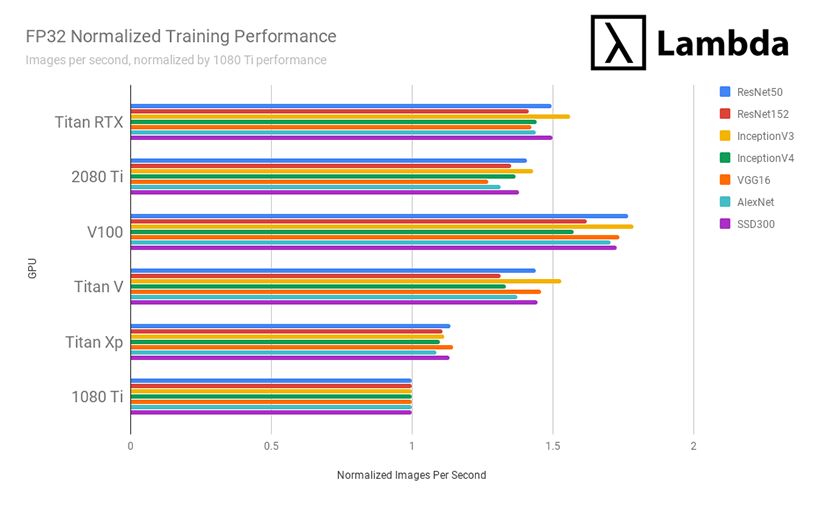
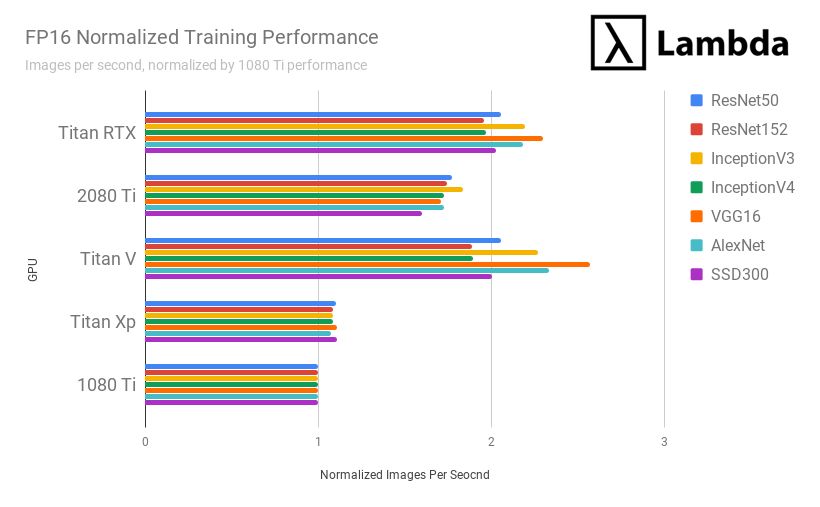
结论:2019 年最合适深度学习/机器学习的 GPU 是?
如果 11 GB 的 GPU 内存足够满足你的训练需求(能满足大部分人),RTX 2080 Ti 是最适合做机器学习/深度学习的 GPU。因为相比于 Titan RTX、Tesla V100、Titan V、GTX 1080 Ti 和 Titan Xp,2080Ti 有最高的性价比。
如果 11GB 的 GPU 内存满足不了你的训练需求,Titan RTX 是最适合做机器学习/深度学习的 GPU。但是,在下结论之前,试试在半精度(16 bit) 上的训练速度。损失一定的训练准确率,能有效地把 GPU 内存翻倍。如果在 FP16 半精度和 11GB 上的训练还是不够,那就选择 Titan RTX,否则就选择 RTX 2080 Ti。在半精度上,Titan RTX 能提供 48GB 的 GPU 内存。
如果不在乎价钱且需要用到 GPU 的所有内存,或者如果产品开发时间对你很重要,Tesla V100 是最适合做机器学习/深度学习的 GPU。
方法
所有模型都是在一个综合数据集上训练的,从而把 GPU 的表现与 CPU 预处理的表现隔离开,且降低伪 I/O 瓶颈的影响。
作者对每个 GPU/模型对进行了 10 组训练实验,然后取平均值。
每个 GPU 的「归一化训练表现」均为在特定模型上每秒处理图像数量的表现与 1080Ti 在同样模型上每秒处理图像数量表现的比值。
Titan RTX、2080Ti、Titan V 和 V100 基准测试用到了 Tensor Cores。
硬件平台
测试中采用的硬件平台为 Lambda Dual 双 Titan RTX 桌面平台,包含英特尔 Core i9-7920X 处理器,64G 内存,看起来已经是最强台式电脑配置了。在测试时,Lambda 仅更换 GPU 配置。
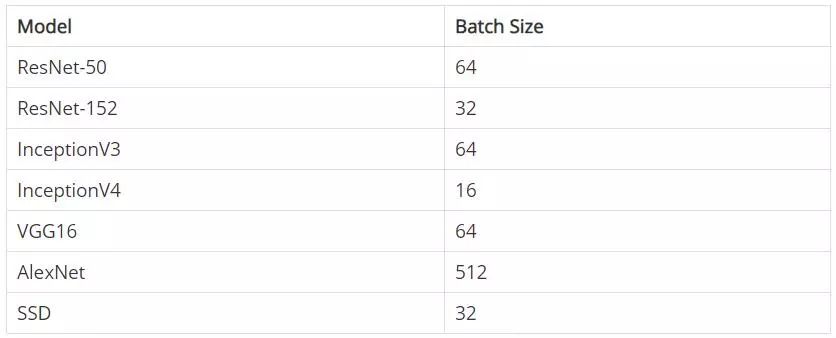
Batch-sizes
系统软件环境
Ubuntu 18.04
TensorFlow: v1.11.0
CUDA: 10.0.130
cuDNN: 7.4.1
NVIDIA Driver: 415.25
初始结果
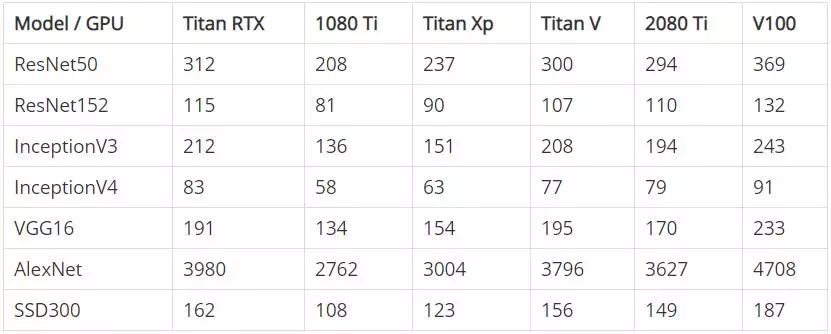
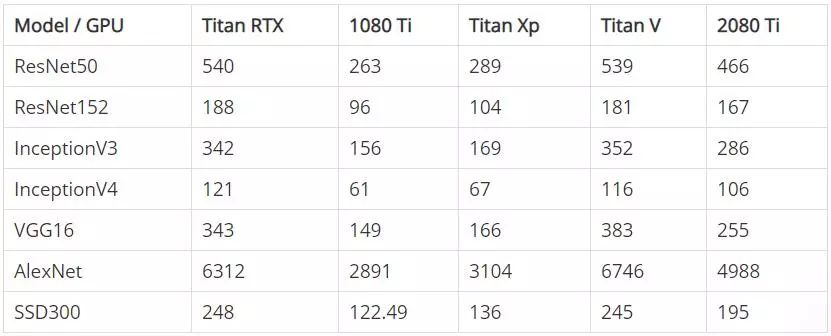
下表显示了在 FP32 模式(单精度)和 FP16 模式(半精度)下训练时每个 GPU 的初始性能。注意,数字表示的是每秒处理的图片数量,对数量进行了四舍五入。
FP32 - 每秒钟处理的图像数量
FP16 - 每秒钟处理的图像数量
自己运行基准测试
目前,Lambda Lab 的 GitHub 库中已经提供了所有基准测试的代码,你可以测试自己的机器了。
第一步:克隆基准测试的 Repo
git clone https://github.com/lambdal/lambda-tensorflow-benchmark.git --recursive
第二步:运行基准测试
输入正确的 gpu_index (default 0) 和 num_iterations (default 10)
cd lambda-tensorflow-benchmark
./benchmark.sh gpu_index num_iterations
第三步:报告结果
选择<cpu>-<gpu>.logs(generated by benchmark.sh) 目录;
使用同样的 num_iterations 进行跑分和记录。
./report.sh <cpu>-<gpu>.logs num_iterations
原文链接:https://lambdalabs.com/blog/titan-rtx-tensorflow-benchmarks/
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com



