如何改进YOLOv3使其更好应用到小目标检测(比YOLO V4高出4%)

极市导读
针对微小目标的特征分散和层间语义差异的问题,本文提出了一种结合上下文增强和特征细化的特征金字塔复合神经网络结构。该网络在VOC数据集上的目标平均精度达到16.9%,比YOLOV4高3.9%,比CenterNet高7.7%,比RefineDet高5.3%。>>加入极市CV技术交流群,走在计算机视觉的最前沿

提出了一种结合增强上下文和细化特征的特征金字塔网络。将多尺度扩张卷积得到的特征自上至下融合注入特征金字塔网络,补充上下文信息。引入通道和空间特征细化机制,抑制多尺度特征融合中的冲突形成,防止微小目标被淹没在冲突信息中。此外,提出了一种Copy-reduce-Paste的数据增强方法,该方法可以增加微小对象在训练过程中对损失的贡献,确保训练更加均衡。
实验结果表明,该网络在VOC数据集上的目标平均精度达到16.9% (IOU=0.5:0.95),比YOLOV4高3.9%,比CenterNet高7.7%,比RefineDet高5.3%。
1 简介
小目标由于分辨率低、体积小,很难被检测到。而小目标检测性能差主要是由于网络模型的局限性和训练数据集的不平衡所造成的。
为了获得可靠的语义信息,很多目标检测器试图叠加越来越多的池化和降采样操作,使得在前向传播中逐渐丢失像素数较少的微小目标特征,因此降低了微小目标的检测性能。
FPN 通过水平融合低分辨率特征图和高分辨率特征图,在一定程度上缓解了信息扩散问题。但是,直接融合不同密度的信息会引起语义冲突,限制了多尺度特征的表达,使微小目标容易淹没在冲突信息中。
同时,在目前的经典公共数据集中,微小目标的标注数量远远少于较大目标的标注数量。因此,在训练过程中,网络的收敛方向不断向较大目标倾斜,导致微小目标性能较差。
因此,作者认为从以上2个方面来提高微小目标的检测性能是可行的。
针对微小目标的特征分散和层间语义差异的问题,本文提出了一种结合上下文增强和特征细化的特征金字塔复合神经网络结构。提出的算法框架如图1所示。
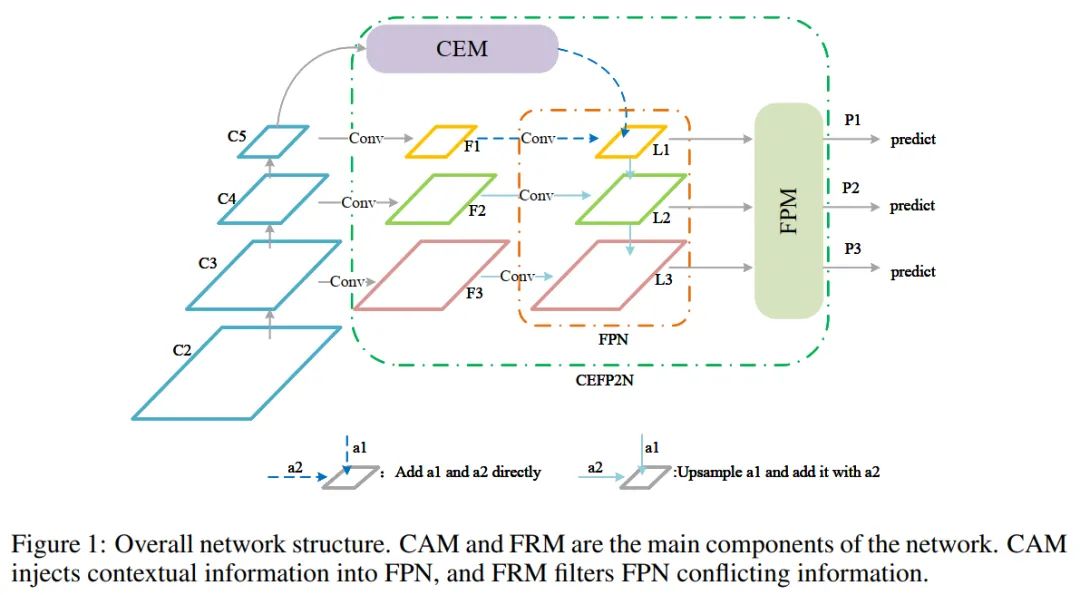
它与上下文增强模块(CAM)和特征细化模块(FRM)相结合。CAM融合多尺度扩张卷积特征,获取丰富的上下文信息进行特征增强。FRM在通道和空间维度上引入特征细化机制来抑制冲突信息,防止微小目标淹没在冲突语义信息中。同时,为了保证网络在训练过程中不会向较大目标倾斜,提出了一种Copy-Reduction-Paste的方法来增加训练中微小目标丢失的比例。
2 相关工作
2.1 经典方法
大家都知道目标检测是一项基础的计算机视觉任务,它包含分类和定位2个部分,而定位则可以看作是一个回归问题。
在早期,手工设计的特征被广泛应用于目标检测。但是,手工设计的特征是一种浅层特征,其也在基于深度学习的特征出现后逐渐被取代。
-
R-CNN作为两阶段算法的先驱,利用不同大小的先验框对不同大小的目标进行匹配,然后通过CNN选择候选区域; -
为了减少训练时间,Fast R-CNN提取整个图像的特征图,然后利用空间金字塔池化和RoI池化生成区域特征并筛选候选区域; -
为了进一步提高小目标的精度,E-FPN提出了一种超分辨率特征金字塔结构来放大小目标特征。与两阶段网络相比,单阶段网络速度较快,但精度相对较低; -
SSD在图像上密集放置Anchor以获取Bounding Box,同时充分利用不同尺度的特征来检测更小的目标。 -
YOLOV3基于特征金字塔有3个输出分别选择大、中、微小物体进行检测,大大提高了微小物体的检测性能。 -
还有一些学者在FPN中引入了高分辨率Attention机制,以挖掘微小目标中最有用信息。本文就是YOLOV3作为Baseline,并在此基础上进行改进。 -
RefineDet引入了新的损失函数,解决了简单样本和困难样本之间的不平衡问题。
近年来,基于Anchor-Free架构的检测器越来越受欢迎。虽然目标检测算法在不断发展和替换,但在微小目标检测领域并没有大的突破,小目标的检测精度依旧很低。
2.2 多尺度特征融合
利用多尺度特征融合是提高小目标检测精度的有效方法。SSD是首次尝试用多尺度特征来预测目标的位置和类别。
FPN从上到下融合不同粒度的相邻特征也极大地提高了特征的表达能力。大量类似FPN的变异结构如下:
-
PANet在FPN的基础上增加了额外的自下向上连接,更有效地将信息从底层传输到上层。 -
NAS-FPN通过神经结构搜索技术搜索出一种新的连接方法。 -
Bi-FPN改进了PANet的连接方式,提高了PANet的效率,并在连接点引入了简单的Attention机制。
上述结构虽然大大提高了网络的多尺度表达能力,但忽略了不同尺度特征之间冲突信息的存在,缺乏上下文信息可能会阻碍性能的进一步提高,特别是对于微小目标很容易被冲突信息淹没。
本文充分考虑了冲突信息和上下文信息对检测精度的影响。
2.3 数据增强
训练集的预处理一直是深度学习中不可缺少的一部分,如 Rotation、deformation、Random Erasure、Random Occlusion、Illumination Distortion以及MixUp 等。
近年来,人们提出了几种针对微小目标的数据增强方法。将4幅图像按相同尺寸拼接在一起,以提高反馈引导下的微小目标检测性能。
还有人试图通过Copy-Paste小目标到原始图像来实现小目标的数据增强。该方法只能增加微小目标的数量,而不能增加包含微小目标的训练图像的数量。也会在一定程度上造成训练的不平衡。由于大目标广泛分布在训练中,而本文保证了小目标对训练损失的贡献,使训练更加均衡。
3 本文方法
如图1所示,输入图像经过4、8、16、32次下采样后,C2、C3、C4、C5分别代表不同level的特征。将F1、F2、F3是对应C3、C4、C5的特征通过一层卷积所生成的(C2因噪声混乱而丢弃)。L1、L2、L3表示FPN生成的特征与CEM的结果融合后输出的对应特征,P1、P2、P3表示FRM生成的特征。
CAM的灵感来自于人类识别物体的模式。例如,在非常高的天空中,人类很难分辨出一只鸟,但在将天空作为上下文信息时,人类就很容易分辨出来。因此,作者认为上下文信息有助于微小目标的检测。
CAM采用不同扩张率的扩张卷积获取不同感受野的上下文信息,并从上到下注入FPN以丰富上下文信息。但由于FPN不同层次之间的语义差异,在共享信息时,会引入冗余信息和冲突信息。
因此,FRM被用来过滤冲突信息,减少语义差异。通过自适应融合不同层间的特征,消除层间的冲突信息,防止微小目标特征淹没在冲突信息中。
同时,针对微小目标产生的正样本数量少、对微小目标丢失的贡献有限的问题,作者提出了一种Copy-Reduce-Paste的数据增强方法。具体来说,复制训练集中较大的目标,然后缩小目标,再然后paste回原始图像。在粘贴过程中,必须保证paste的目标不与现有目标重叠。
3.1 具有上下文增强和特征的特征金字塔网络细化
1、上下文增强模块
通过前面的描述可以知道微小目标的检测需要上下文信息。作者提出使用不同扩张率的扩张卷积来获取不同感受野的上下文信息来丰富FPN的上下文信息。结构如图2所示。
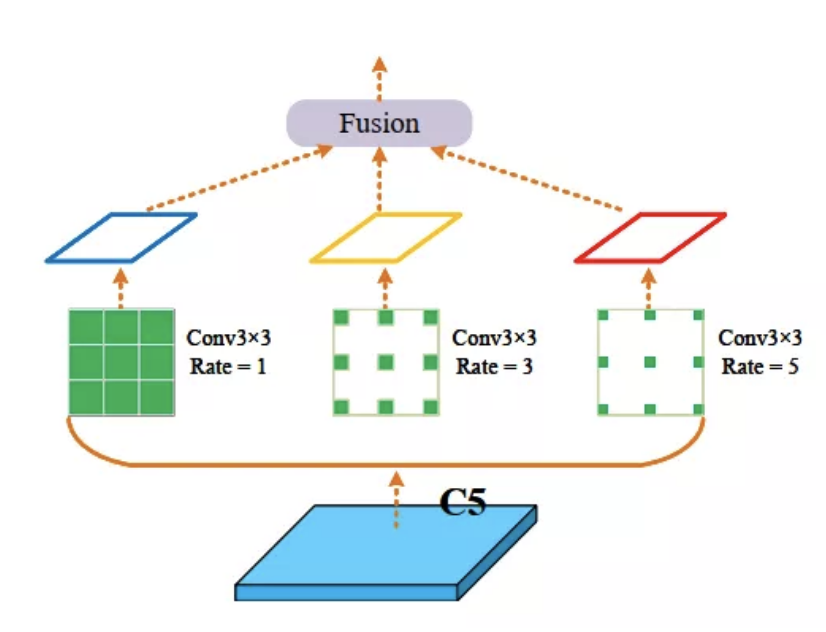
图2为CAM的结构。在C5上以不同的扩张率空洞卷积进行卷积以获得不同感受野的语义信息。核大小为3×3,扩张率为1、3、5。可能的融合方式如图3 (a)、(b)和(c)所示。
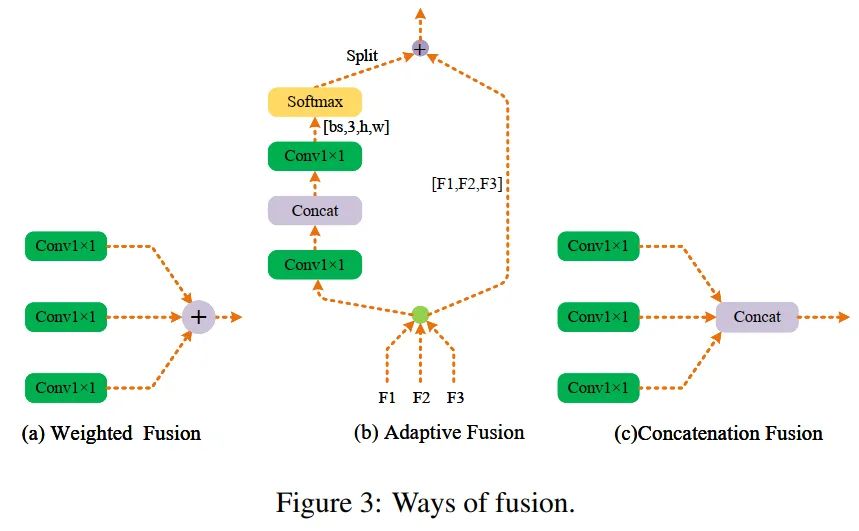
-
方法(a):是 Add融合方法; -
方法(b):是 自适应融合方法; -
方法(b):是 Concat融合方法;
具体来说,假设输入的大小可以表示为(bs, C, H, W),可以通过卷积级联和Softmax操作得到(bs, 3, H, W)的空间自适应权值。3个通道一一对应3个输入,通过计算加权和,可以将上下文信息聚合到输出。
作者通过消融实验验证了每种融合方法的有效性, 结果如下表1所示。 和 被定义为小、中、大目标的精度。其中 和 分别表示对小、中、大目标的召回率。
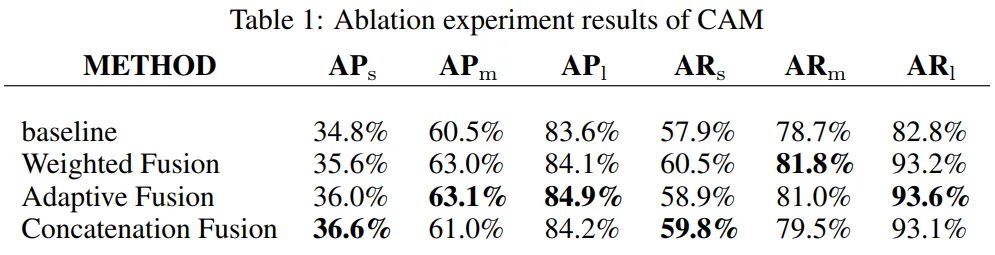
由表1可以看出,方法(c)对于微小目标所获得的增益最大,AP和AR都增加了1.8%。方法(b)对中、大型目标改进最大。方法(a)带来的改进基本上是介于两者之间。
2、特征细化模块
FPN被提出用于融合不同尺度的特征。但是,不同尺度的特征具有不可忽视的语义差异。直接融合不同尺度的特征会带来大量的冗余信息和冲突信息,降低多尺度表达的能力。因此,FRM被用来过滤冲突信息,防止微小的目标特征被淹没在冲突信息中。FRM的总体结构如图4所示。
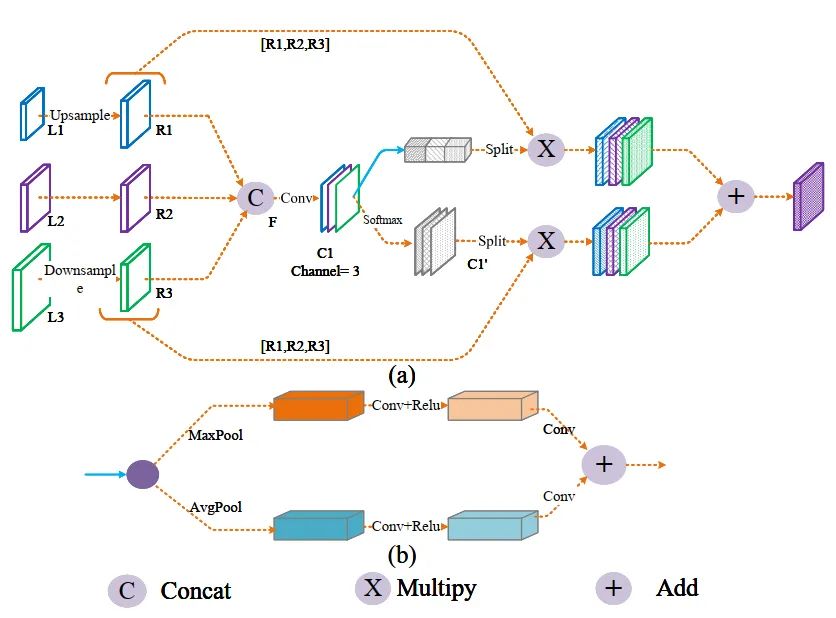
从图4可以看出,FRM主要由2个并行分支组成,即通道净化模块和空间净化模块。在空间维度和通道维度上生成自适应权值,引导特征向更关键的方向学习。
通道净化模块结构如图4(b)所示。将输入的特征图压缩到空间维度,聚合能代表图像全局特征的空间信息,得到通道注意力图。将自适应平均池化和自适应最大池化相结合,获得更精细的全局特征。
被定义为FRM的第m 层的输入。 定义为从第 层调整到第 层 的结果。 定义为第k个通道 位置的第 个特征图的值。因此,上分支的输 出是:
式中 表示第 层在 位置的输出向量。 为通道自适应权值,其大小为 c定义为:
F是由Concat操作生成的特性,如图4所示。σ表示Sigmoid。AP和MP分别为平均池化和最大池化,然后将这两个权值在空间维度上相加,在Sigmoid后生成基于通道的自适应权值。
空间净化模块 通过softmax生成各位置相对于通道的相对权重,下分支的输出如式3所示:
式3中, 为特征图的空间位置, 为输入特征图的通道。 为位置 处的输 出特征向量。 和 为相对于MTH层的空间注意权重,其中c为通道。
上式中F的含义是使用softmax对特征映射在通道方向上进行归一化,得到同一位置不同通道的相对权重。
因此,该模块的总输出可以表示为:
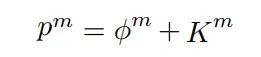
这样,FPN各层的特征在自适应权值的指导下融合在一起,p1、p2、p3作为整个网络的最终输出。
为了证明FRM的有效性,作者可视化了一些特征图。微小目标的检测主要由FPN的底层主导,因此仅对底层特征进行可视化。将特征图缩放到相同的尺寸。如图所示,最左边的一列是待检测的输入图像。F3、L3、P3为中对应标签的特征图可视化结果。
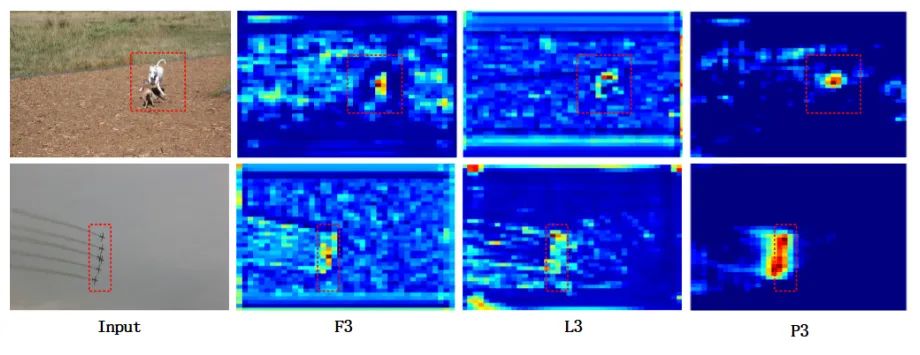
从图5中可以看出,F3可以大致定位目标位置,但背景噪声较大。
在FPN之后,在L3中引入了大量的高级语义信息。这些特征可以滤除大部分背景噪声,但由于特征粒度的不同,也引入了冲突信息,使目标区域的响应变弱。
以P3为例,目标特征增强,背景区域被抑制,目标与背景的边界更加明显,有助于检测器区分正样本和负样本,便于定位和分类。从可视化分析可以看出,本文提出的FRM可以大大减少冲突信息,提高微小目标的检测精度。
3.2 Copy-Reduce-Paste数据增强
在目前主流的公共数据集中,小目标产生的正样本数量和小目标对损失的贡献都远远小于大目标,使得收敛方向倾向于大目标。为了缓解这个问题,作者在训练过程中对图像中的目标Copy-Reduce-Paste。
通过增加图像中微小物体的数量和包含微小物体的图像数量,增加了对微小物体损失的贡献,使训练更加均衡。下图为每个目标在不同位置粘贴一次的结果。



通过这种方式,大大丰富了微小物体的数量和上下文信息。在这一部分中,作者研究了粘贴次数对微小物体检测的影响。消融实验结果见下表。
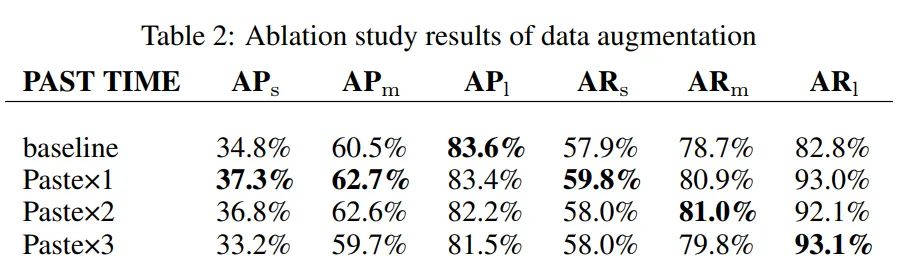
从上表可以看出,随着粘贴次数的增加,微小物目标的检测性能逐渐下降,甚至可能低于baseline。这可能是因为随着粘贴次数的增加,数据集的分布逐渐被破坏,使得测试集的性能变差。实验结果表明,一次粘贴效果最好。与baseline相比,提高了2.5%,提高了1.9%,对大中型目标的检测性能也略有提高。
3.3 消融实验
作者设计了消融实验来验证各模块的有效性和贡献率。
实验结果如表所示:
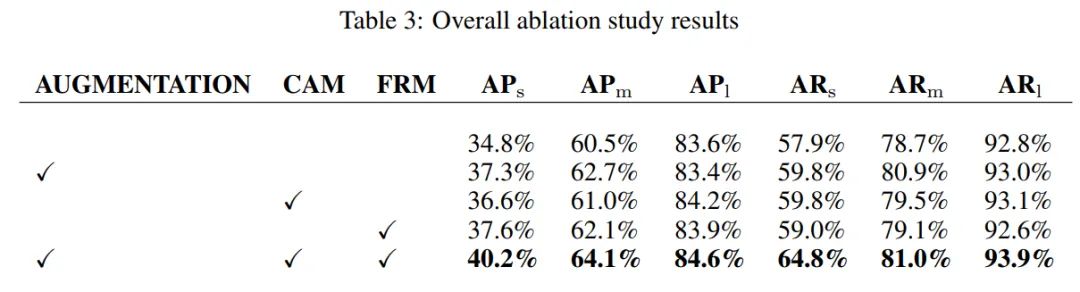
总体而言,本文提出的模块可以显著提高目标检测性能,特别是对于微小目标和中等目标,这也符合设计的初衣。如表所示, 增加了5.4%。AP 增加 , 增加1.0%。同时,不同尺度目标的召回率也有不同程度的提高。具体而言, 增加 增加 增加 。
-
Copy-Reduce-Paste数据增强方法:使 增加了, 增加 , 但 略有 下降。 -
CAM: CAM模块可以对 和 都有提升, 特别是对 其查准率 和查全率分别提高了1.8%和1.9%。 -
FRM: 增加 增加 基本不变。
4 实验
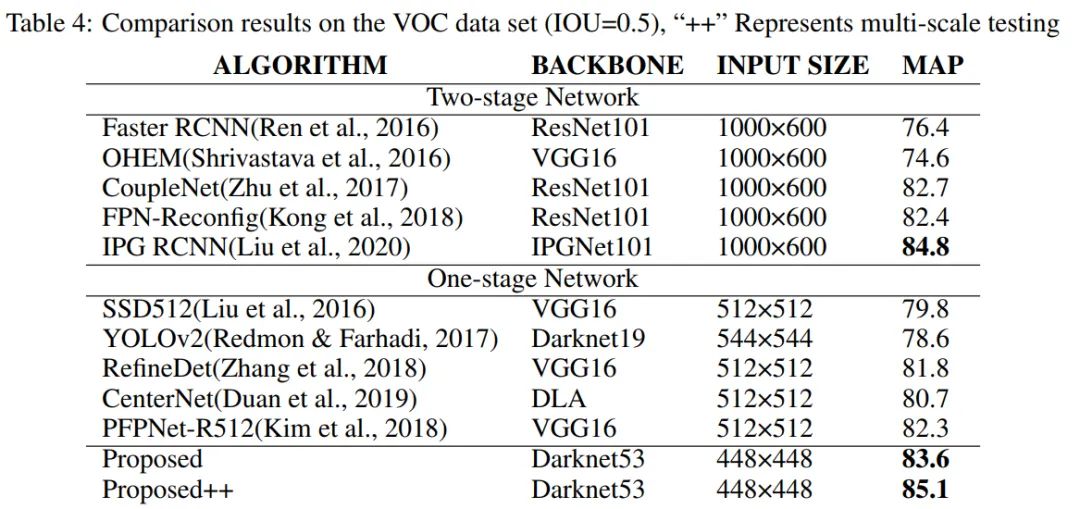
从上表可以看出,本文提出的算法在VOC数据集上的mAP值高于近年来大多数算法。比 PFPNet-R512 高1.3%。但比IPG-RCNN低1.2% 。这主要是由于Backbone较差,图像尺寸较小,使得检测性能略低于IPG-RCNN。如果用多尺度方法测试算法,VOC数据集上的mAP可以达到85.1%,高于所有参与对比的算法。
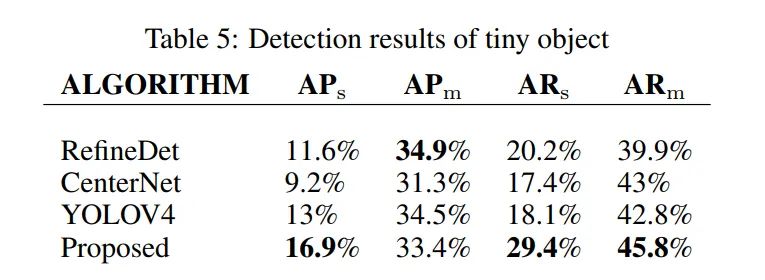
从上表可以看出,本文提出的算法在微小目标的AP和AR方面具有绝对优势。
本文算法比YOLOV4算法提高3.9% (16.9%vs.13%),在比较算法中最高。与RefineDet相比在上高9.2%(29.4% vs. 20.2%),而在上低1.5%。
同时,本文提出的算法对中等目标的AR值最高,对中等目标具有较强的检测能力。
通过以上可以看到,本文提出的算法在微小目标检测方面有很大的优势。微小目标的AP和AR算法都有较好的性能,优于大多数目标检测算法。
参考
[1].CONTEXT AUGMENTATION AND FEATURE REFINEMENT NETWORK FOR TINY OBJECT DETECTION
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“CVPR21检测”获取CVPR2021目标检测论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~




