又改YOLO | 项目如何改进YOLOv5?这篇告诉你如何修改让检测更快、更稳!!

极市导读
本文提出了一种改进的特征金字塔模型AF-FPN,该模型利用自适应注意模块(adaptive attention module, AAM)和特征增强模块(feature enhancement module, FEM)来减少特征图生成过程中的信息丢失,进而提高特征金字塔的表示能力。此外,提出了一种新的自动学习数据增强方法,以丰富数据集,提高模型的鲁棒性,使其更适合于实际场景。大量实验结果表明本文方法的有效性和优越性得到了验证。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

交通标志检测对于无人驾驶系统来说是一项具有挑战性的任务,尤其是多尺度目标检测和检测的实时性问题。在交通标志检测过程中,目标的规模变化很大,会对检测精度产生一定的影响。特征金字塔是解决这一问题的常用方法,但它可能会破坏交通标志在不同尺度上的特征一致性。而且,在实际应用中,普通方法难以在保证实时检测的同时提高多尺度交通标志的检测精度。
本文提出了一种改进的特征金字塔模型AF-FPN,该模型利用自适应注意模块(adaptive attention module, AAM)和特征增强模块(feature enhancement module, FEM)来减少特征图生成过程中的信息丢失,进而提高特征金字塔的表示能力。将YOLOv5中原有的特征金字塔网络替换为AF-FPN,在保证实时检测的前提下,提高了YOLOv5网络对多尺度目标的检测性能。
此外,提出了一种新的自动学习数据增强方法,以丰富数据集,提高模型的鲁棒性,使其更适合于实际场景。在100K (TT100K)数据集上的大量实验结果表明,与几种先进方法相比,本文方法的有效性和优越性得到了验证。
1 介绍
交通标志识别系统是ITS和无人驾驶系统的重要组成部分。如何提高交通标志检测与识别技术的准确性和实时性,是该技术走向实际应用时需要解决的关键问题。近年来,大多数先进的目标检测算法,如Faster R-CNN、R-FCN、SSD和YOLO,都使用了卷积神经网络,并在目标检测任务中取得了丰硕的成果。然而,将这些方法简单地应用到交通标志识别中很难取得满意的效果。车载移动终端的目标识别和检测对不同尺度的目标要求较高的精度,对识别速度要求较高,这意味着要满足准确性和实时性两个要求。传统的CNN通常需要大量的参数和浮点运算(FLOPs)来达到令人满意的精度,例如ResNet-50有大约25.6万个参数,需要41亿个浮点运算来处理224×224大小的图像。然而,内存和计算资源有限的移动设备(如智能手机和自动驾驶汽车)无法用于更大网络的部署和推理。YOLOv5作为一种One-stage检测器,具有计算量小、识别速度快等优点。本文提出了一种改进的YOLOv5网络,既保证模型尺寸满足部署在车辆侧的要求,又提高了多尺度目标的能力,满足实时性要求。工作的主要贡献如下:
-
提出了一种新的特征金字塔网络。通过自适应特征融合和感受野增强,在特征传递过程中很大程度上保留通道信息,并自适应学习每个特征图中的不同感受野,增强特征金字塔的表示,有效地提高了多尺度目标识别的精度; -
提出了一种新的自动学习数据增强策略。受AutoAugment的启发,添加了最新的数据增强操作。改进的数据增强方法有效地提高了模型训练效果和训练模型的鲁棒性,具有更大的现实意义; -
与现有的YOLOv5网络不同,对当前版本进行了改进,以减少尺度不变性的影响。同时,它可以部署在车辆的移动终端上,对交通标志进行实时检测和识别。
2 相关工作
2.1 基于CNN的交通标识检测
目前,卷积神经网络在视觉目标检测方面取得了很大的成功。根据是否需要提出区域建议,基于深度学习的目标检测可分为两类:单阶段检测和两阶段检测。Shao等人提出了一种区域建议算法来简化Gabor小波,提高Faster R-CNN用于交通标志检测。Zhang等人提出了一种改进的基于YOLOv2的交通标志检测器,修改了经典YOLOv2网络的卷积层数,使其适合中国交通标志数据集。Li等人开发了一种新的感知生成对抗网络,该网络通过生成小交通标志的超分辨率表示来提高检测性能。SADANet结合域自适应网络和多尺度预测网络来解决尺度变化问题。上述网络大多采用单尺度的深度特征,难以提高复杂场景下的检测和识别性能。大型和小型交通标志具有完全不同的视觉特征,因此规模变化问题是交通标志检测与识别中的一个难题。对于目标检测,学习尺度不变表示对于识别和定位目标至关重要。目前的工作主要从两个方面来解决这一挑战,即网络架构和数据扩充。目前,多尺度特征被广泛应用于高层目标识别中,以提高多尺度目标的识别性能。特征金字塔网络(Feature Pyramid Network, FPN)是一种常用的多层特征融合方法,利用其多尺度表达能力衍生出许多检测精度较高的网络,如Mask R-CNN和RetinaNet。值得注意的是,由于功能通道的减少,特征图会出现信息丢失,并且在其他level的特征图中只包含一些不太相关的上下文信息。此外,使用FPN会导致网络过分注重Low-level特征的优化,有时会导致对大规模目标的检测精度降低。针对这一问题,提出了一种简单而有效的方法,即感受野金字塔(RFP),以增强特征金字塔的表示能力,并驱动网络学习最优的特征融合模式。
2.2 数据增强
数据增强已被广泛应用于网络优化,并被证明有利于视觉任务,可以提高CNN的性能,防止过拟合,且易于实现。数据增强方法大致可以分为颜色操作(如亮度、对比度和颜色投射)和几何操作(如缩放、翻转、平移和缩放)。这些增强操作通过数据扭曲或过采样人为地扩大了训练数据集的大小。Lv等人提出了五种针对人脸图像的数据增强方法,包括landmark抖动和四种合成方法(发型、眼镜、姿势、照明)。Nair等人对训练数据应用了两种形式的数据增强。一种是随机裁剪和水平反射,另一种是通过在颜色空间上应用PCA来改变RGB通道的强度。这些常用的方法只是做简单的转换,不能满足复杂情况的需求。Dwibedi等人通过cut-paste策略提高了检测性能。此外,InstaBoost使用带注释的实例mask和位置概率图来增强训练图像。YOLOv4和Stitcher引入了包含重新缩放子图像的Mosaic输入,这也在YOLOv5中使用。然而,这些数据增强实现是手工设计的,最佳的增强策略是特定于数据集的。为了避免数据增强的数据特定性质,最近的工作集中在直接从数据本身学习数据增强策略。Tran等人使用贝叶斯方法根据从训练集中学习到的分布生成增广数据。Cubuk等人提出了一种名为AutoAugment的数据增强新方法,用于自动搜索改进的数据增强策略。
3 本文方法
3.1 Improved YOLOv5s架构
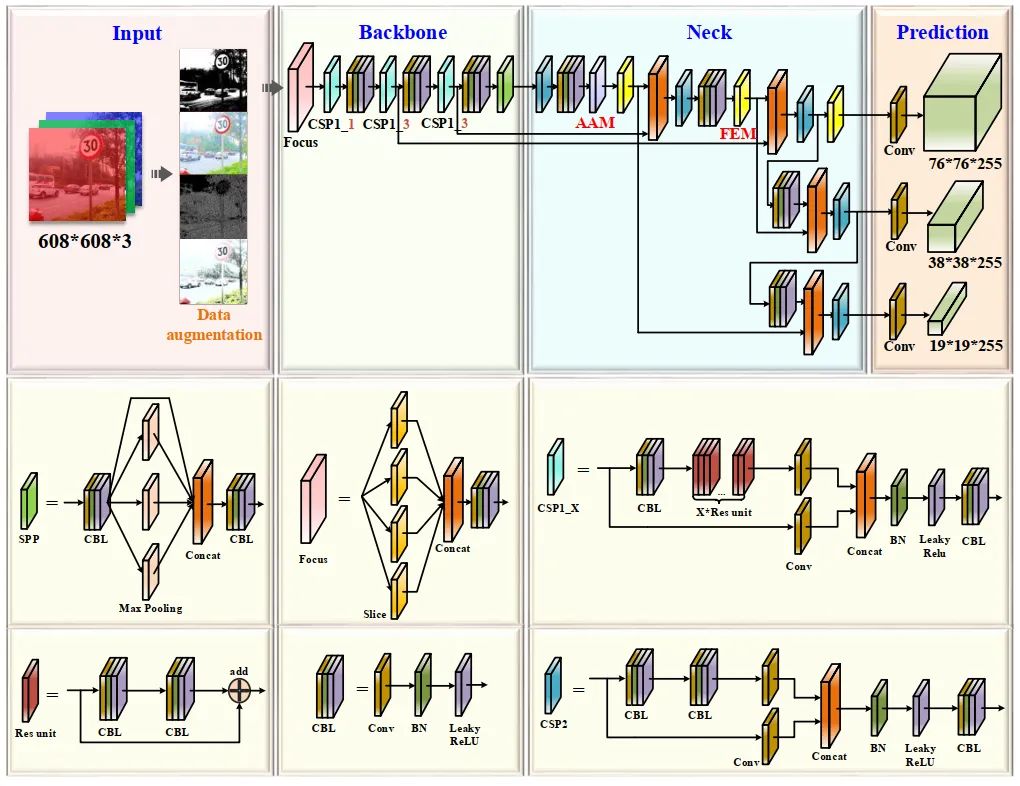
作为目前YOLO系列的最新版本,YOLOv5优越的灵活性使得它可以方便地快速部署在车辆硬件侧。YOLOv5包含YOLOv5s、YOLOv5m、YOLOv5l, YOLOv5x。YOLOv5s是YOLO系列中最小的版本,由于其内存大小为14.10M,更适合部署在车载移动硬件平台上,但其识别精度不能满足准确高效识别的要求,尤其是对小目标的识别。YOLOv5的基本框架可以分为4个部分:Input、Backbone、Neck和Prediction。
-
Input部分通过拼接数据增强来丰富数据集,对硬件设备要求低,计算成本低。但是,这会导致数据集中原有的小目标变小,导致模型的泛化性能下降。 -
Backbone部分主要由CSP模块组成,通过CSPDarknet53进行特征提取。 -
在Neck中使用FPN和路径聚合网络(PANet)来聚合该阶段的图像特征。 -
最后,网络进行目标预测并通过预测输出。
本文引入AF-FPN和自动学习数据增强,解决模型大小与识别精度不兼容的问题,进一步提高模型的识别性能。用AF-FPN代替原来的FPN结构,提高了多尺度目标识别能力,在识别速度和精度之间进行了有效的权衡。此外,去除原网络中的Mosaic增强,根据自动学习数据增强策略使用最佳的数据增强方法来丰富数据集,提高训练效果。改进后的YOLOv5s网络结构如图1所示。
在预测中,使用Generalized IoU (GIoU) Loss作为BBox的损失函数,使用加权的非最大抑制(NMS)方法NMS。损失函数如下:
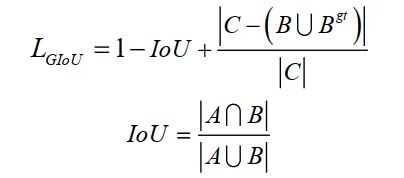
其中是覆盖和的最小方框。为ground-truth box,为predicted box。但是,当预测框在ground-truth 框内且预测框大小相同时,预测框与ground-truth框的相对位置无法区分。本文用Complete IoU(CIoU) Loss代替GIoU Loss。CIoU损失在考虑GIoU损失的基础上,考虑了BBox的重叠面积、中心点距离以及BBox长宽比的一致性。损失函数可以定义为:
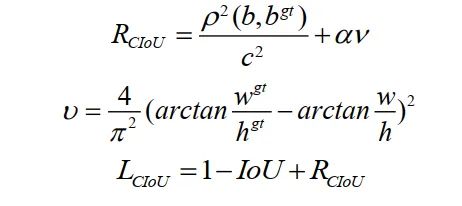
其中是惩罚项,通过最小化两个BBox中心点之间的归一化距离来定义。和表示和的中心点,为欧几里得距离,c为覆盖两个方框的最小封闭方框的对角线长度。是一个正的权衡参数,衡量纵横比的一致性。权衡参数定义为:
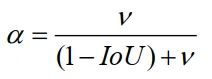
其中重叠面积因子在回归中具有较高的优先级,特别是在非重叠情况下。
3.2 架构改进
3.2.1 AF-FPN
AF-FPN在传统特征金字塔网络的基础上,增加了自适应注意力模块(AAM)和特征增强模块(FEM)。前者减少了特征通道,减少了高层特征图中上下文信息的丢失。后一部分增强了特征金字塔的表示,提高了推理速度,同时实现了最先进的性能。AF-FPN结构如图2所示。
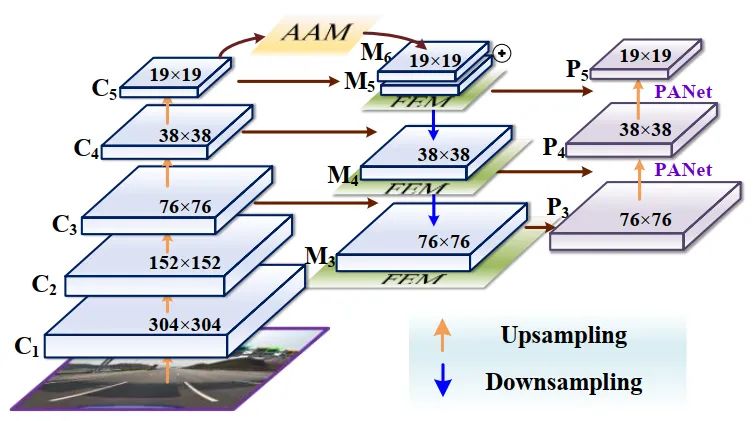
输入图像通过多个卷积生成特征映射{C1, C2, C3, C4, C5}。C5通过AAM生成特征映射M6。M6与M5求和并通过自上而下的途径传播与较低层次的其他特征融合,通过扩展感受域每次融合后的有限元分析。PANet缩短了底层与顶层特征之间的信息路径。自适应注意模块的操作可以分为2个步骤:
-
首先,通过自适应平均池化层获得不同尺度的多个上下文特征。池化系数为[0.1,0.5],根据数据集的目标大小自适应变化。
-
其次,通过空间注意力机制,为每个特征图生成空间权值图。通过权重图融合上下文特征,生成包含多尺度上下文信息的新特征图。
3.2.2 AAM
AAM的具体结构如图3所示。
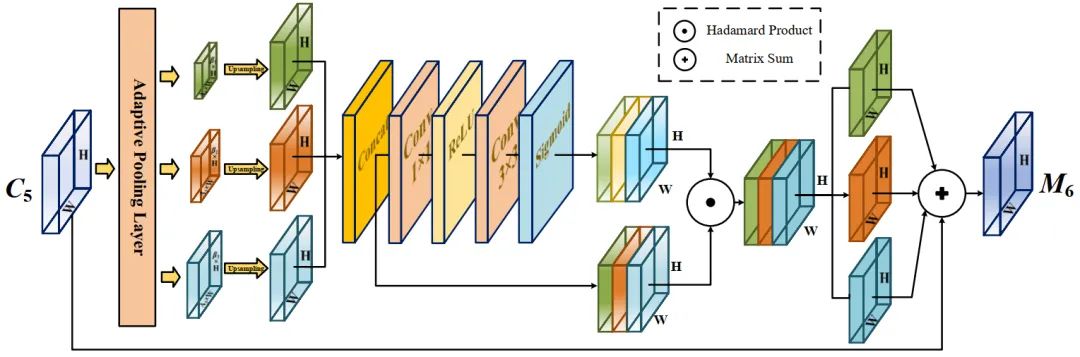
作为自适应注意力模块的输入,C5的大小为S=h×w,
-
首先通过自适应池化层获得不同尺度的语义特征。
-
然后,每个上下文特征进行1×1卷积,以获得相同的通道维数256。利用双线性插值将它们上采样到S尺度,进行后续融合。空间注意力机制通过Concat层将3个上下文特征的通道进行合并;
-
然后特征图依次经过1×1卷积层、ReLU激活层、3×3卷积层和sigmoid激活层,为每个特征图生成相应的空间权值。生成的权值映射和合并通道后的特征映射经过Hadamard乘积操作,将其分离并添加到输入特征映射M5中,将上下文特征聚合为M6。
-
最终得到的特征图具有丰富的多尺度上下文信息,在一定程度上缓解了由于通道数量减少而造成的信息丢失。
3.2.3 FEM
FEM主要是根据检测到的交通标志尺度的不同,利用扩张卷积自适应地学习每个特征图中的不同感受野,从而提高多尺度目标检测识别的准确性。
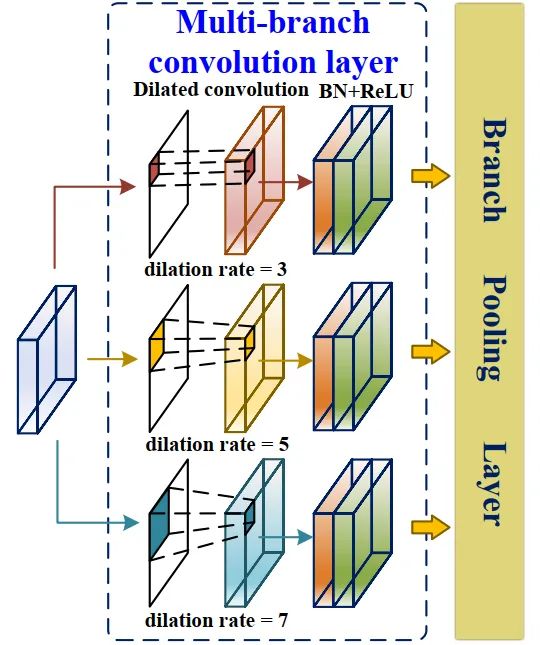
如图4所示,它可以分为两部分:
-
多分支卷积层 -
分支池化层
多分支卷积层通过扩张卷积为输入特征图提供不同大小的感受野。利用平均池化层融合来自三个支路感受野的交通信息,提高多尺度精度预测。多分支卷积层包括扩张卷积、BN层和ReLU激活层。三个平行分支中的扩张卷积具有相同的内核大小,但扩张速率不同。具体来说,每个扩张卷积的核为3×3,不同分支的扩张速率d分别为1、3、5。扩展卷积支持指数扩展的感受野,而不损失分辨率。而在扩张卷积的卷积运算中,卷积核的元素是间隔的,空间的大小取决于膨胀率,这与标准卷积运算中卷积核的元素都是相邻的不同。卷积核由3×3更改为7×7,该层的感受野为7×7。扩张卷积的感受野公式为:
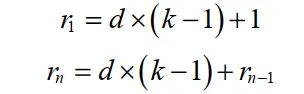
其中k和分别表示kernel-size和膨胀率。d表示卷积的stride。分支池化层用于融合来自不同并行分支的信息,避免引入额外参数。在训练过程中,利用平均操作来平衡不同平行分支的表示,使单个分支在测试过程中实现推理。表达式如下:
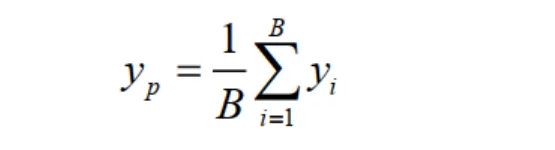
其中表示分支池化层的输出。B表示并行分支的数量,这里设B = 3。
3.3 数据增强
扩展策略由搜索空间和搜索算法两部分组成。在搜索空间中,有S=5个子策略,每个子策略由两个图像操作组成,依次应用。随机选择一个子策略并应用于当前图像。此外,每个操作还与两个超参数相关:应用操作的概率和操作的大小。在实验中使用的操作包括最新的数据增强方法,如Mosaic、SnapMix、Earsing、CutMix、Mixup和Translate X/Y。在搜索空间中总共有15个操作。每个操作也有一个默认的幅度范围。将幅度的范围离散为D=11等间距值,以便可以使用离散搜索算法来找到它们。类似地,还将对P=10个值(均匀间距)进行操作的概率离散化。在个可能性的空间中找到每个子策略成为一个搜索问题。因此,包含5个子策略的搜索空间大约有可能性,需要一个高效的搜索算法来导航该空间。图5显示了搜索空间中包含5个子策略的策略。

通过搜索空间,将搜索学习到的增广策略问题转化为离散优化问题。采用强化学习作为搜索算法,它包含两个部分:控制器RNN和训练算法。控制器RNN为递归神经网络,训练算法为近端策略优化(PPO),学习率为0.00035。控制器RNN在每一步预测softmax产生的决策,然后将预测作为搜索空间的嵌入,送入下一步。控制器总共有30个softmax预测来预测5个子策略,每个子策略有2个操作,每个操作需要操作类型、大小和概率。将自动学习数据增强方法应用于TT100K数据集,然后使用通过训练获得的最佳数据增强策略。
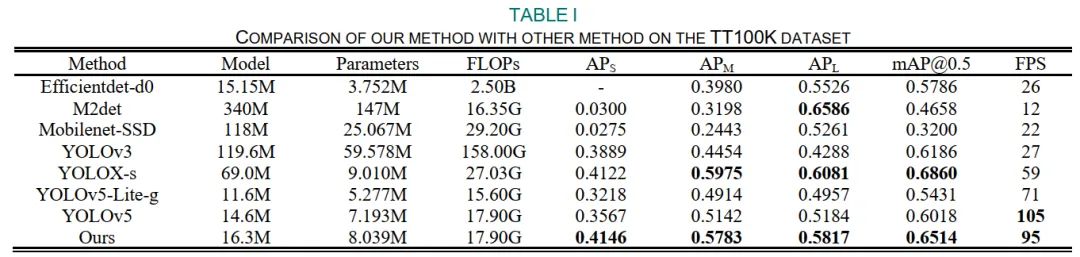
4 实验

5 参考
Improved YOLOv5 network for real-time multi-scale traffic sign detection
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“transformer”获取最新Transformer综述论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~



