ICLR2020 | 基于图神经网络的归纳矩阵补全
Inductive Matrix Completion Based on Graph Neural Networks
Inductive Matrix Completion Based on Graph Neural Networks - ICLR 2020
〇、相关工作
1、Graph Neural Network
图神经网络(GNNs)是一种用于在图形上学习的新型神经网络。主要分为两种类型:Node Level GNNs和Graph Level GNNs。Node level GNNs使用消息传递层在每个节点与其邻居之间迭代传递消息,以便为编码其局部子结构的每个节点提取特征向量。Graph level GNNs另外使用诸如求和之类的池化层,其将节点特征向量聚集到图表示中以实现诸如图分类/回归之类的图级任务。由于其优越的图表示学习能力,GNNs在半监督节点分类、网络嵌入、图分类和链路预测中取得了最佳性能。
2、GNN for Matrix Completion
Monti等人(2017)开发了一个Multi-Graph CNN(MGCNN)模型,从各自的最近邻网络中提取用户和项目的潜在特征。Berg等人(2017)提出了图卷积矩阵补全(GC-MC),它直接将GNN应用于用户-项目二部图,利用GNN提取用户和项目的潜在特征。郑等人(2018年)的SpectralCF模型使用二部图上的Spectral-GNN来学习节点嵌入。虽然使用GNN补全矩阵,但所有这些模型仍然是转导的。MGCNN和SpectralCF需要不推广到新图的图拉普拉斯,而GC-MC使用节点ID的一次性编码作为初始节点特征,因此不能推广到未知的用户/项。最近的基于归纳图形的推荐系统PinSage(Ying等人,2018a)使用节点内容作为初始节点特征(而不是GC-MC中的一次性编码),并成功地用于推荐Pinterest中的相关pins。尽管PinSage具有诱导性,但它严重依赖于与Pins相关的丰富视觉和文本内容,而这些内容在其他推荐任务中通常是无法访问的。
另一个相关的先前工作是(Hartford等人,2018年),它定义了可交换矩阵层,以对矩阵执行置换等变运算,从而在不使用内容的情况下实现归纳矩阵完成。具体地说,该操作通过其自身、其行的条目、其列的条目以及矩阵的所有其他条目的加权和来更新每个矩阵条目,其中四个分量中的每一个的参数在所有条目之间共享。也可以将其视为GNN,例外情况是1)消息传递是在边上执行的(最终的边缘特征被汇集成节点特征),以及2)所有边(包括那些未连接到中心边缘的边)在每一轮中将消息传递到中心边缘。(Hartford等人,2018年)的一个限制是它将整个评级矩阵作为输入,这可能会引起对大型矩阵的担忧。
3、Link prediction based on graph patterns
学习有监督的启发式算法(图模式)已被用于简单图中的链接预测。Zhang和Chen(2017)提出了Weisfeler-Lehman神经机(WLNM),它使用子图邻接矩阵上的全连通神经网络来学习图的结构特征。后来,他们通过用GNN取代完全连接的神经网络来改进这项工作,并获得了最先进的链接预测结果。我们的工作将这一研究方向从简单图中的链路值预测推广到二部图中的链路值预测(即矩阵补全)。在(Chen等人,2005;周等人,2007)中,传统的链接预测启发式算法适用于二部图,对于推荐系统显示出良好的性能。我们的工作的不同之处在于,我们不使用任何预定义的启发式方法,而是使用GNN学习一般的图结构特征。另一个与我们类似的工作是(Li&Chen,2013),其中图核被用来学习图结构特征。然而,图核需要二次时间和空间复杂度来计算和存储核矩阵,因此不适合现代推荐系统。
一、动机
-
用于矩阵补全的矩阵分解方法本质上是转导性的(transductive)。当矩阵发生改变时,通常需要再次进行训练才能得到新的嵌入。
①为什么矩阵分解可以用于矩阵补全任务?
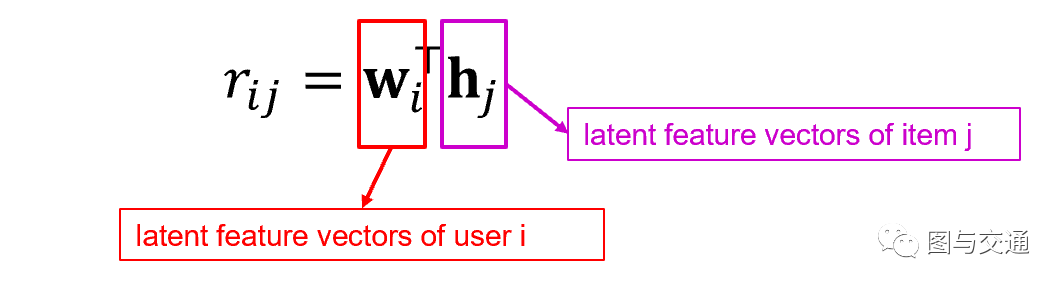
图1 - 传统矩阵分解在评分矩阵上的应用 矩阵分解(Matrix Factorization)是指用 M’= A×B 来近似矩阵M,那么 A×B 的元素就可以用于估计M中对应不可见位置的元素值,而A×B可以看做是M的分解,所以称作矩阵分解。
矩阵补全(Matrix Completion)目的是为了估计矩阵中缺失的部分(不可观察的部分),可以看做是用矩阵X近似矩阵M,然后用X中的元素作为矩阵M中不可观察部分的元素的估计。
用M'=A×B来近似M,再用M'上的元素值来填充M上的缺失值,达到预测效果进而补全矩阵。
②Transductive Learning(传导性学习)和Inductive Learning(归纳性学习)的区别?
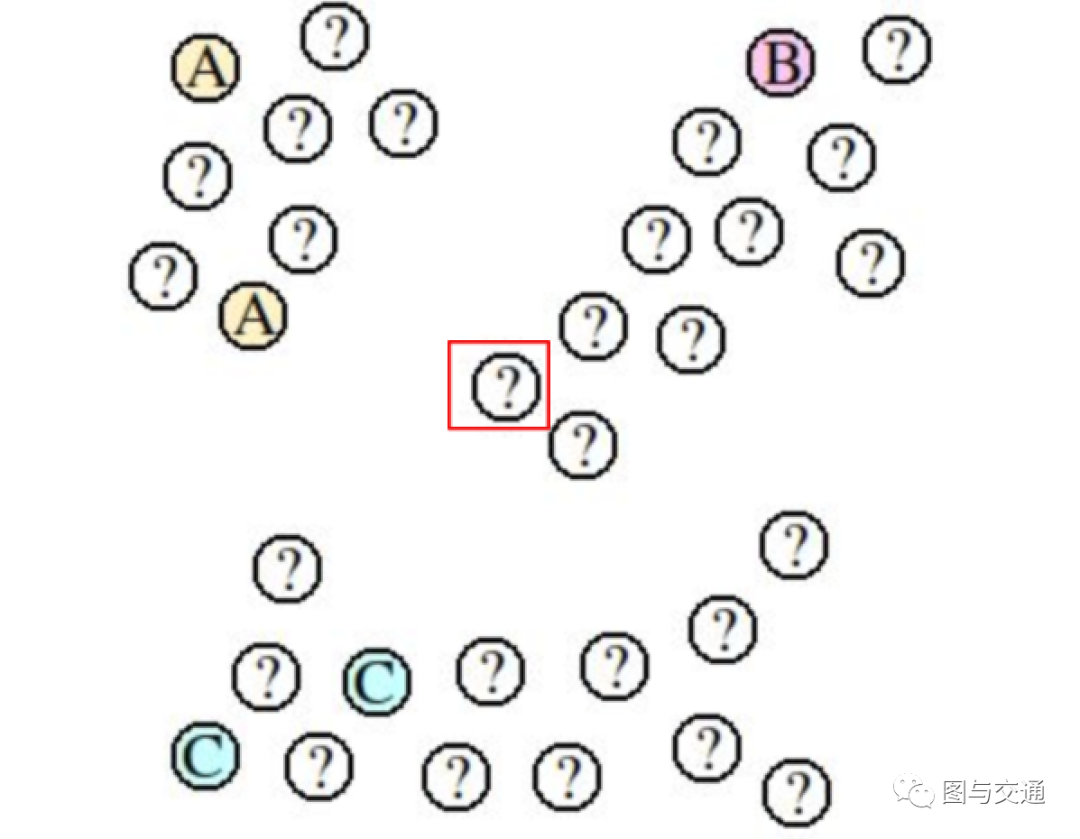
图2 - 节点类别预测 现有如图2所示的问题规模,任务是预测 '?' 节点的类别。
Transductive Learning使用所有节点的信息,直接用某种算法观察出数据的分布。在这里节点为分为三个簇,红框中的节点由于非常接近B所在的簇,所以会被标记为B。由此可见,即使只有少量可用的被标注数据,这种方法仍然可以预测节点的类型。但是,这种方法没有建立预测模型。这意味着,当新节点加入数据集时,需要再次运行算法以达到预测效果,因此计算量与数据量呈正比。此外,当向数据集中加入新节点时,可能会致使旧节点类别发生改变。
Inductive Learning只需要根据现有数据来训练一个监督学习模型来预测节点类别。红框中节点更接近A和C,采用KNN距离算法,其更有可能被标记为A或C。即使再向数据集中添加新的节点,这种方法仍然只利用原有的5个已知类别的节点进行预测。
-
当内容或辅助信息(content or side information-通常是节点属性等)质量低甚至不可获取时,传统的归纳性矩阵补全(Inductive Matrix Completion)无法准确预测缺失项。
为了使矩阵补全是具有归纳性的(inductive),2013的文章《Speedup matrix completion with side information: Application to multi-label learning》提出了Inductive Matrix Completion(IMC)。如图3所示,在IMC中,评分矩阵中的一个评分以 形式分解, 分别表示用户i和项目j的内容特征向量,Q是描述特征交互的可学习矩阵。为了准确预测丢失的条目,IMC方法需要借助高质量的内容信息。
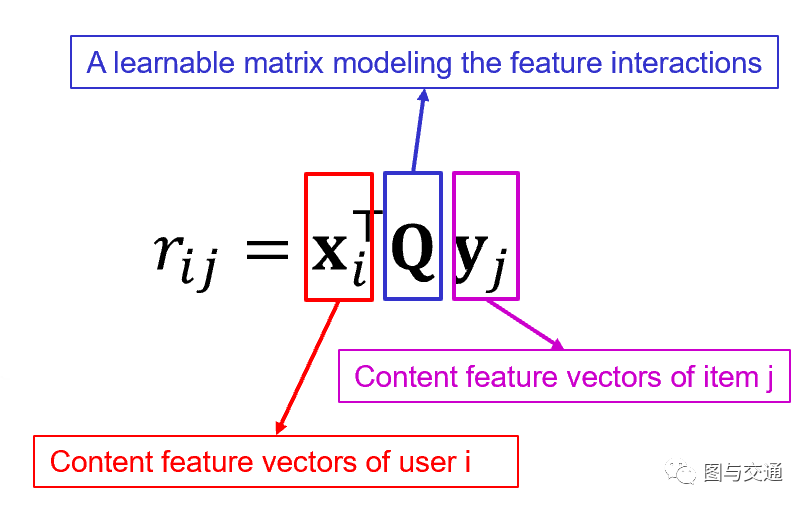
图3 - IMC中的矩阵分解形式 尽管IMC是具有归纳性的,但是其非常依赖于内容或辅助信息。比如,在推荐系统中,其非常依赖于用户和商品的属性信息。因此,在辅助信息的质量不高甚至无法获得时,IMC方法的性能可能会比较差。例如,在一个完全匿名的网站,IMC方法是无法实现的。
-
利用可交换矩阵层(Exchangeable Matrix Layers)实现矩阵补全的方法尽管是具有归纳性的,但是其会将整个矩阵作为输入并输出一个重构的矩阵。
为了减少对辅助信息的依赖,2018年的《Deep Model of Interactions Accorss Sets》提出了可交换矩阵层(Exchangeable Matrix Layers),它对评分矩阵应用置换等变运算来重建缺失条目,得到的模型是具有归纳性的,并且不依赖于辅助信息。然而,这些模型将整个评分矩阵R作为输入,输出另一个重构的矩阵,这对于扩展到具有数百万用户/项目的实际数据集中来说是非常困难的。
二、问题
-
在没有任何内容且不将整个评分矩阵作为输入的情况下,如何学习归纳性的矩阵补全?
问题的关键就在于局部图模式。对于评分矩阵上已存在的评分,在相应的用户和项目之间添加一条边,就可以从评分矩阵中建立一个二分图。
在推荐系统中,有一个非常重要的假设:如果用户 喜欢商品 ,我们经常可以看到 也会被与 有相似喜好的其他用户 喜欢。所谓相似喜好,是指 和 都喜欢其他的商品 。
这种假设在二分图上被实现为“like”路径,亦即),如果 和 之间有许多这样的路径,可以推断 很可能喜欢 。因此,可以将这类路径的数量,作为 喜欢 的可能性的指标。但是这些指标需要我们进行一些手动定义的工作,本文则采取不同的方式:从给定的二分图中自动学习合适的启发式算法。
为此,先为每个训练用户-项目对 提取一个h跳封闭子图。这个h跳封闭子图被定义为由h跳内的节点 及其邻居从二部图中导出的子图。这样的局部子图包含关于 可以给予 的评分的丰富的图形模式信息。
例如,所有)路径都包含在围绕 的1跳封闭子图中。通过将这些封闭的子图提供给GNNs,可以训练出一个图回归模型,该模型将每个子图映射到中心用户对中心项目的评分。
三、贡献
-
本文提出一个具有归纳性(即它可以泛化到训练过程中看不到的用户/项目)的算法IGMC(基于归纳图的矩阵补全)。
-
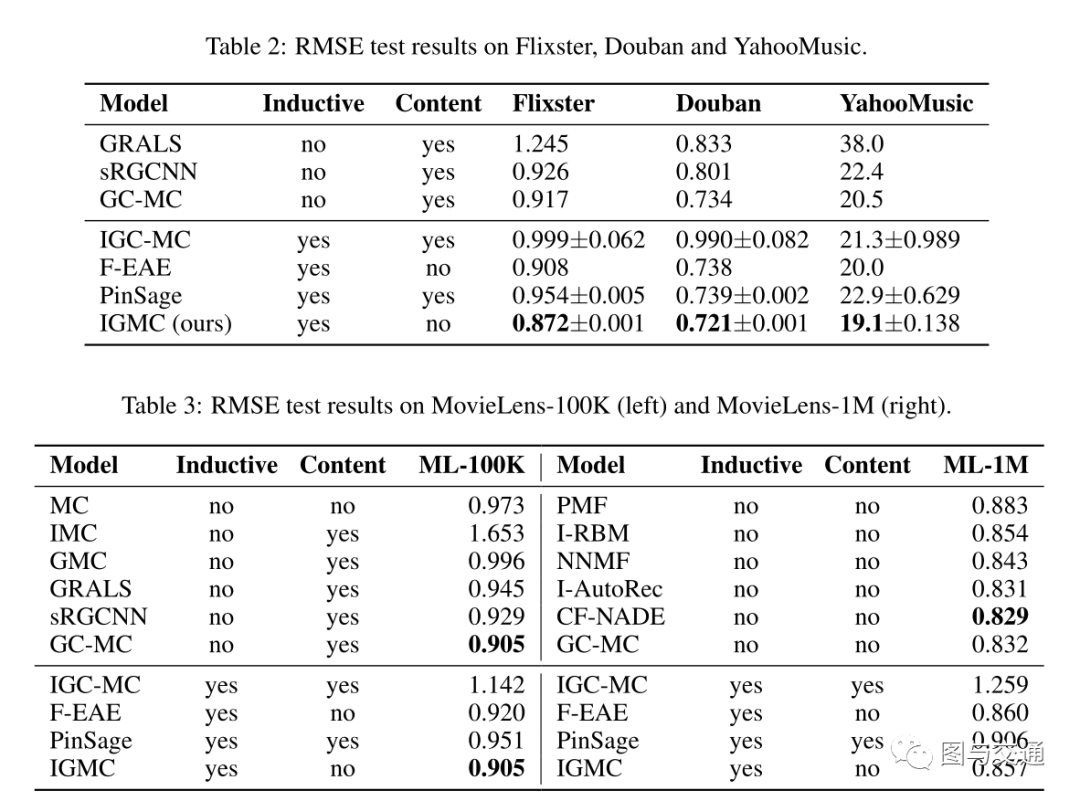
在五个基准数据集上比较了IGMC和最新的矩阵补全算法,在不使用任何内容的情况下,IGMC在其中四个上实现了最小的均方根误差,甚至超过了许多由边信息增强的转换性矩阵补全算法。
-
利用可视化证实了局部封闭子图的确是评分的强预测因子。
四、定义
:评分矩阵。其中行表示用户,列表示项目。元素用户给项目的评分。
:所有可能评分的集合。如 。
:由给定评分矩阵 构造出来的无向二分图。
:用户,对应评分矩阵 中的行。
:项目,对应评分矩阵 中的列。
:边 的值,对应用户 给予项目 的评分。
:节点 的邻居集,集合中的元素都是以边形式 与 相连的。
五、模型方法
1. 提取封闭子图
IGMC的第一部分是封闭子图提取。对于每个已有的评分 ,我们从 中提取围绕 的h跳封闭子图,并将这些封闭子图馈送到GNN,然后对它们的评分进行回归。对于每个测试对 ,我们再次从 中提取它的h跳封闭子图,并使用训练好的GNN模型来预测它的评分。注意,在提取 的封闭子图后,应将边 删除,因为这是模型的预测目标。
图4所示的算法描述了用于提取h跳封闭子图的广度优先搜索过程。

我对这个算法的理解大致如下(以提取一跳封闭子图为例):
如图5所示,先看红框中深绿色方块(需要进行预测的评分)所在行的左右两侧一跳。中心用户给左侧一跳项目打了4分:看给这4分项目打过分的一跳用户,其给这个4分项目打了3分,还给中心项目打了5分;中心用户给右侧一跳项目打了2分:看给这2分项目打过分的一跳用户,其给2分项目打了1分,同时给中心项目给了5分。从对项目的打分情况可见中心用户与其余两个用户喜好比较相似,又因为这两个用户给中心项目打了5分,所以中心用户对中心项目打5分的可能性非常高。同理,紫色方框中的提取过程与上述相似。从上述过程可以看出,封闭子图中包含了大量"like"路径。

图5 - 1跳封闭子图 GNN在学习图模式时,还会依赖更多的信息,如项目的平均得分、中心用户打分的平均值、相似用户打分的平均值等等,这些信息可以从边信息上直接获得,不需要依赖辅助信息。
2.节点标记
IGMC的第二部分是节点标记。在我们将一个封闭的子图提供给GNN之前,我们首先对子图中的每个节点添加一个整数标签。目的是使用不同的标签来标记子图中节点的不同角色。
首先将标签0和1分别赋予目标用户和目标项目。对于封闭子图中的其他节点,我们根据其在子图中的哪一跳来确定它们的标签,如果用户类型的节点包含在第i跳,我们将给它一个标签2i。如果项目类型的节点包括在第i跳,我们将给它2i+1。
这样的节点标记可以充分地区分:1)目标节点与“上下文”节点,2)来自项目的用户(用户总是具有偶数标签),以及3)到目标评分的不同距离的节点。否则,GNN不能在哪个用户和哪个项目之间预测评级,并且可能会丢失节点类型信息。
我对这个标记过程的理解大致如下(以一跳封闭子图为例):
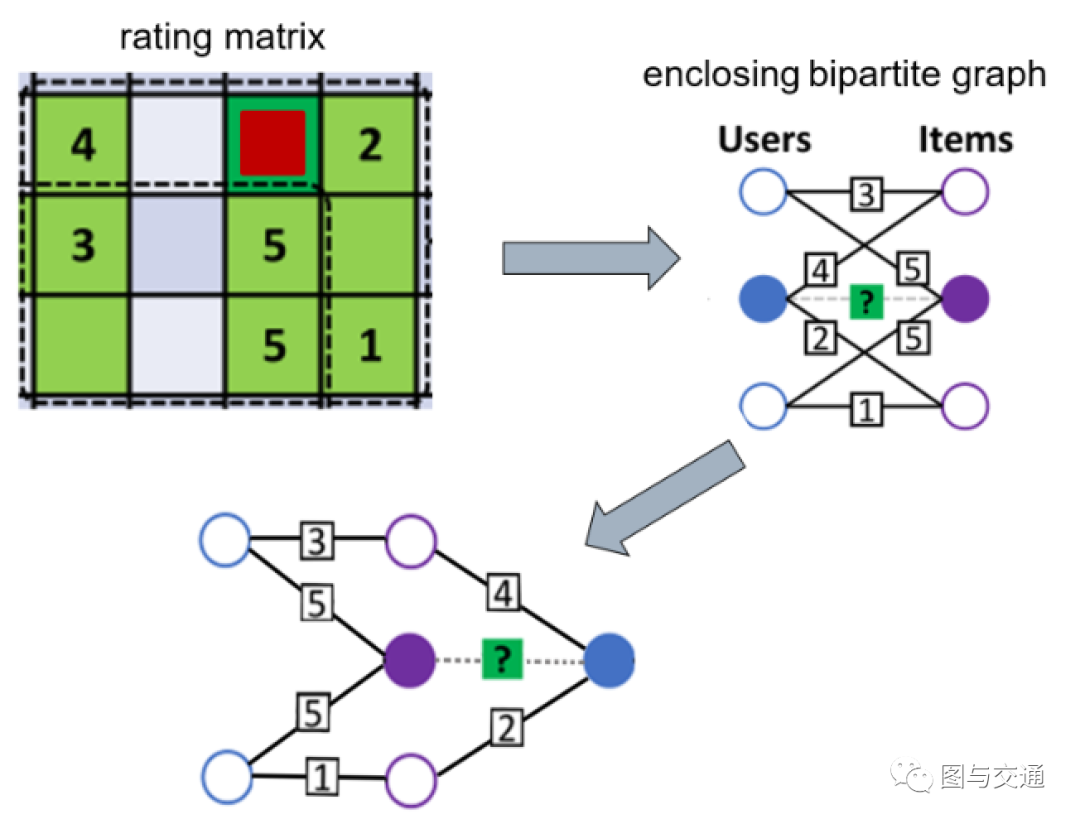
图6 - 展开的1跳封闭子图 评分矩阵局部对应的封闭子图展开如图6下部所示,标记过程如图7所示。首先将目标用户(蓝色)和目标项目(紫色)分别标记为0和1,然后将 user-item pair 视为一个整体。因为两个项目在user-item pair的1跳上,故标记为2×1+1=3;两个用户也在1跳上,故标记为2×1=2。
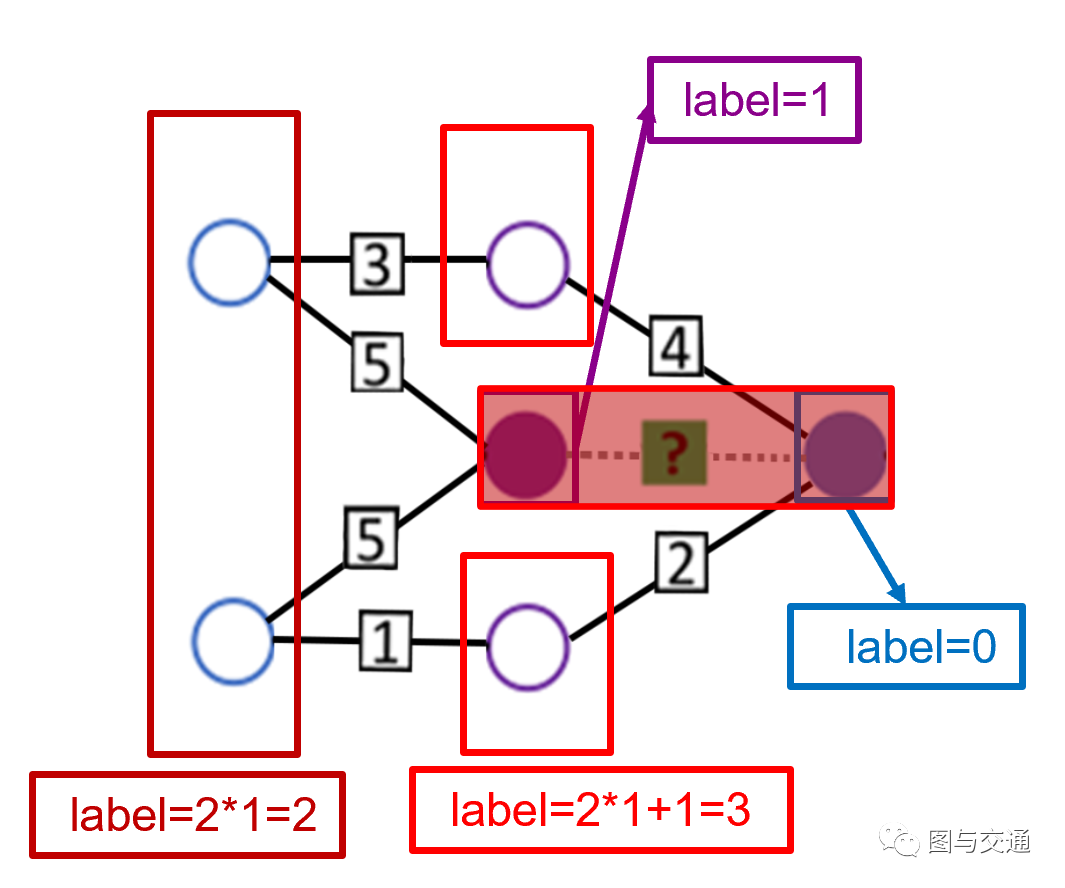
图7 - 节点标记过程 当将数据馈送到GNN时,这些节点标签的one-hot编码将被视为子图的初始节点特征 。
3.GNN结构
IGMC的第三部分是训练一个从包含的子图中预测评分的图神经网络(GNN)模型。
以前的基于节点的方法中,节点级GNN被应用于整个二部图来提取节点嵌入。然后,将u和v的节点嵌入输入到内积或双线性算子,以重构 上的评分。相反,IGMC将图形级GNN应用于 周围的封闭子图,并将该子图映射到评级。
IGMC的GNN中有两个组件:1)信息传递层,用于为子图中的每个节点提取特征向量;2)池化层,用于从节点特征中概括子图表示。
(1)信息传递层
为学习到由不同边类型引出来的丰富图模式,IGMC采用R-GCN作为消息传递层。
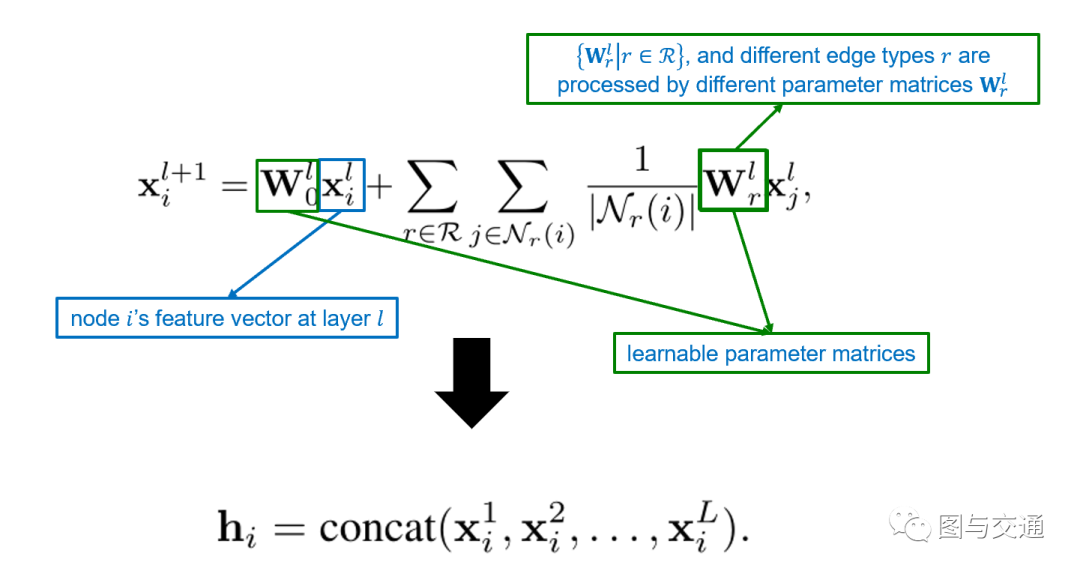
是节点 在第 层的特征向量; 和 都是可学习参数矩阵。其中 用来处理不同边类型,因此模型能够学习边类型内的大量信息,诸如目标用户给予项目的平均评分、目标项目接收的平均评分以及通过哪些路径连接两个目标节点等。
在两层之间堆叠L个具有激活函数tanh的信息传递层,将来自不同层的节点 的特征向量连接起来作为其最终表示 。
通过公式其实可以看得出来, 这一部分学习目标节点在 层中的特征向量,公式后半部分学习相邻节点的特征向量。如果目标节点是用户,那么它的相邻节点一定是项目,因为用户和用户之间不可能存在边。反之,如果目标节点是项目,它的相邻节点必定是用户,因为项目与项目之间不可能存在边。将L层中节点 的特征向量连接起来后作为节点 的最终表示 。
R-GCN可以用于链路预测和实体分类问题中。最重要的是,其会考虑边的类型。对于不同的边,其会赋予不同的参数 。在输入层,根据边的顶点id和边类型,选择对应的权值,并将其作为第一层的输出。在隐藏层和输出层,将上一层顶点的输出乘以边的权值,作为本层的输出,相同类型的边则共享权值。
(2)池化层
为了将节点表示集中到图级向量中,我们使用一个池化层将目标用户和目标项目的最终表示作为图表示。之所以选择目标用户和目标项目,是因为它们比其余上下文节点具有更重要的意义。
在得到最终的图形表示后,我们使用最大似然算法输出预测评级:
其中 和 是参数,将图形表示 映射到标量评分 (因为最终评分是一个标量), 是激活函数(本文采用ReLU)。
4.模型训练
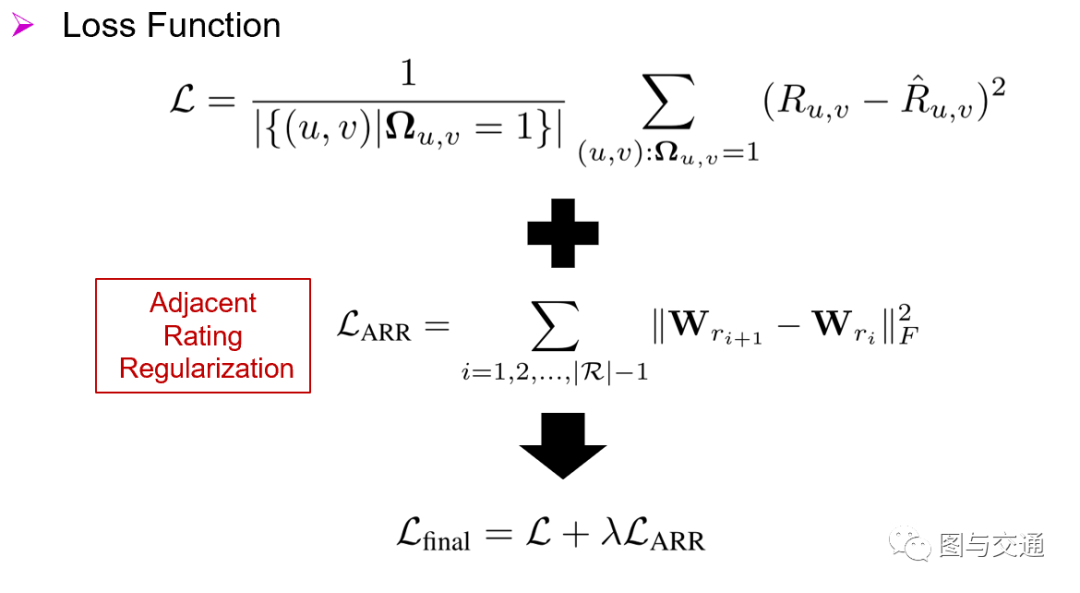
如图9所示,使预测和真实评分之间的均方误差最小化,损失函数为 。Ω为一个0/1标记矩阵,用来表明评分矩阵中存在的 对。
R-GCN层对于不同的评分类型具有不同的参数 。这里的一个缺点是,它没有考虑到评分的大小。例如,电影评价中的评分为4和评分为5都表示用户喜欢该电影,而评分为1表示用户不喜欢该电影。我们希望模型能够意识到,评分4比1更类似于5。但是,在R-GCN中,评分1、4和5仅被视为三种独立的边缘类型。这导致评分的大小和顺序信息完全丢失。
为了解决这一问题,我们提出了一种相邻评分假设正则化(ARR)技术,该技术鼓励彼此相邻的评分具有相似的参数矩阵。假设评分集R中的评分呈现一个指示用户对项目具有越来越高的偏好的排序 。
上述正则化方法抑制了相邻评分的参数矩阵有太大的差异,不仅考虑了评分的顺序,而且通过传递相邻评分的信息来帮助优化那些不常用的评分。
表示F-范数,用来衡量相邻评分的参数矩阵之间的差异。
用于权衡均方误差损失和ARR正则化的重要性。
六、实验
1.基准方法
(1)GRALS是一种图正则矩阵补全算法。
(2)GC-MC和sRGCNN是基于转导节点级GNN的矩阵补全方法。
(3)F-EAE使用可交换的矩阵层来执行感应矩阵补全,而不使用内容。
(4)PinSage是一个使用内容的基于节点级别GNN的归纳模型,最初用于预测相关pins,这里适用于预测评分。
(5)Inductive GC-MC(IGC-MC),是对GC-MC的一种更改,它用内容特征代替节点ID的one-hot编码。
(6)PMF、I-RBM、NNMF、I-AutoRec、CF-NADE、GC-MC都是一些转导性的方法。
2.实验结果
七、总结
1.所有以前的矩阵补全GNN都使用节点级GNN来学习节点的嵌入,而IGMC使用图级GNN来学习子图的表示。IGMC基于图神经网络归纳地学习与评级相关的局部图模式,而不是学习传导性潜在特征。相比于使用节点级GNN,使用图级的GNN优势在于其可以通过充足的的信息传递次数对节点之间的交互和对应关系进行建模并学习。(学习节点嵌入实质上是对两个节点周围的两棵根子树进行独立编码,这无法对两棵树的节点之间的交互和对应关系进行建模。)
2.与以前的归纳矩阵完成方法相比,IGMC不依赖于用户/项目的内容(辅助信息)。
3.与不使用内容的方法相比,IGMC只基于GNNs归纳学习局部图模式,减少了输入输出规模。
4.在没有大量训练数据的情况下,IGMC是比传导式方法更好的选择,特别适合于推荐系统的初始评分收集阶段。
关于本文的审稿意见,可参见https://openreview.net/forum?id=ByxxgCEYDS
推荐阅读



