AAAI 2018论文解读 | 基于置信度的知识图谱表示学习框架
作者丨谢若冰
单位丨腾讯微信搜索应用部
研究方向丨知识表示学习
知识图谱被广泛地用来描述世界上的实体和实体之间的关系,一般使用三元组(h,r,t)(head entity, relation, trail entity)的形式来存储知识,其中蕴含的知识数量巨大且时常更新。
目前,人工标注已经不能满足知识图谱更新和增长的速度,但自动化构建知识图谱的过程中往往容易引入一些噪声和冲突。
由于大多数传统知识表示学习(Knowledge, Representation Learning, KRL)方法都假设现有知识图谱中的知识是完全正确的,因此会带来潜在误差。
于是,如何从带有噪声或冲突的知识图谱中学习到更好的知识表示向量,同时又能够发现已有知识图谱中可能存在的错误,就成为了亟需解决的问题。
来自清华大学/腾讯的谢若冰研究员,清华大学的刘知远老师,腾讯的林芬研究员和林乐宇研究员,在即将发表于 AAAI 2018 的论文《Does William Shakespeare REALLY Write Hamlet? Knowledge Representation Learning with Confidence》中,提出了一种新的基于置信度的知识表示学习框架(confidence-aware KRL framework,CKRL),能够发现知识图谱中潜在的噪声或冲突,同时更好地从中学习知识表示。
作者在 CKRL 模型中主要参考了 TransE 的思路,使用了平移假设(translation-based assumption),并增加了三元组置信度(triple confidence)的概念。整体能量方程如下:
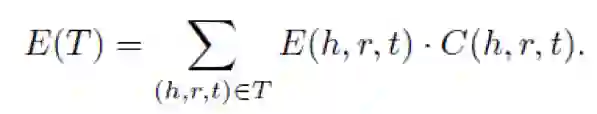
其中,基于平移假设,有:
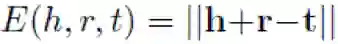
对于 triple confidence,作者设计了三种模式,分别是 Local Triple Confidence,Prior Path Confidence 以及 Adaptive Path Confidence,基于平移假设,使用三元组的实体、关系,以及实体之间的路径的向量信息,综合对三元组的置信度进行动态调整与学习。
具体地,对于使用 path 的置信度,作者假设如果 (h,r,t) 中 h,t 有越多包含较多信息流的路径,并且这些路径的向量表示与 r 越相似,那么 (h,r,t) 三元组的置信度越高。
整个训练过程中,知识表示和三元组的置信度在能量函数指导下相互影响并动态优化,最终得到考虑置信度的知识表示,并能基于此知识表示完成知识表示学习和知识图谱噪声探测等任务。
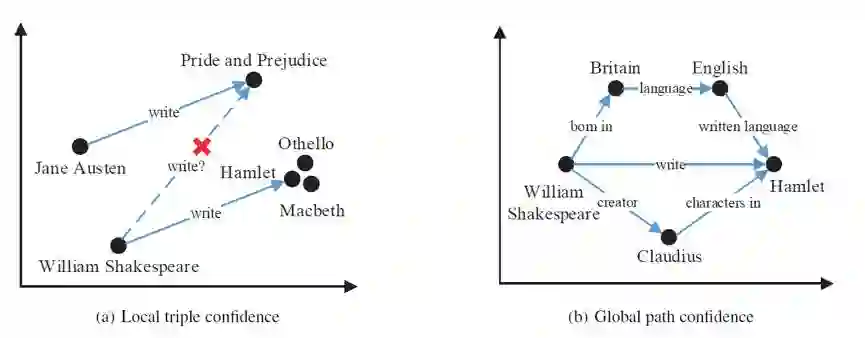
在学习的过程中,作者使用了 margin-base score function 进行学习,希望正例得分能够高于负例得分。需要注意的是,由于作者使用的是三元组的向量信息,所以三元组的置信度会在训练过程中发生动态变化。
低置信度的三元组在学习中会相应收到打压,最终使得带有噪声的知识图谱中的知识表示向量能够学得更好,同时减少噪声和错误带来的影响。
CKRL 模型在 noise detection、knowledge graph completion 和 triple classificaiton 三个任务上都取得了较好的结果,同时该模型的思想还可以直接扩展至知识构建环节中,在自动构建方法情境下,帮助建立更加精准的知识图谱。
作者的话
本文是作者在清华大学硕士期间以及在腾讯微信搜索应用部期间完成的工作,在知识表示学习框架中引入了基于结构信息的置信度的概念,能够同时提升知识表示学习和知识图谱噪声探测的效果。
作者之前的多篇工作致力于融合多源信息提升知识表示性能,但在知识驱动的实际任务中也存在很多诸如噪声等现实问题。本次工作即是在知识图谱置信度上的一次初步探索,相关思路也可以引入知识构建等知识工程其它环节。

点击以下标题查看相关内容:


2017年度最值得读的AI论文 | NLP篇 · 评选结果公布
2017年度最值得读的AI论文 | CV篇 · 评选结果公布
我是彩蛋
解锁新功能:热门职位推荐!
PaperWeekly小程序升级啦
今日arXiv√猜你喜欢√热门职位√
找全职找实习都不是问题
解锁方式
1. 识别下方二维码打开小程序
2. 用PaperWeekly社区账号进行登陆
3. 登陆后即可解锁所有功能
职位发布
请添加小助手微信(pwbot01)进行咨询
长按识别二维码,使用小程序
*点击阅读原文即可注册

关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 查看论文 & 源代码



