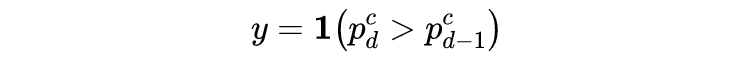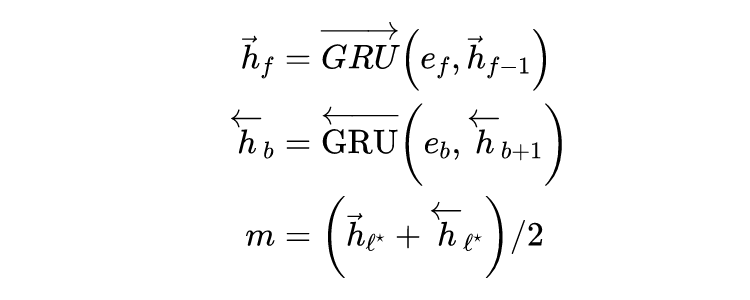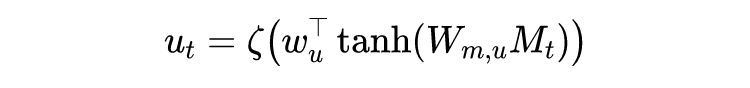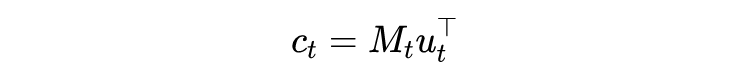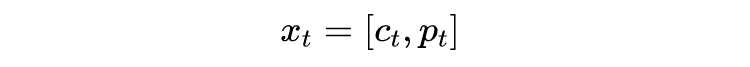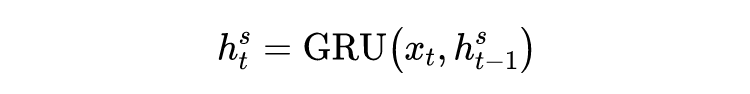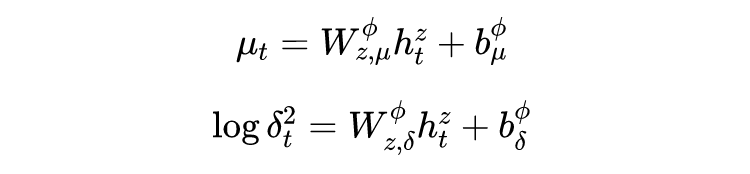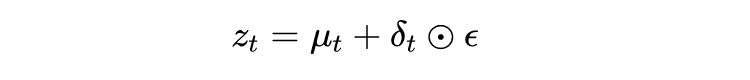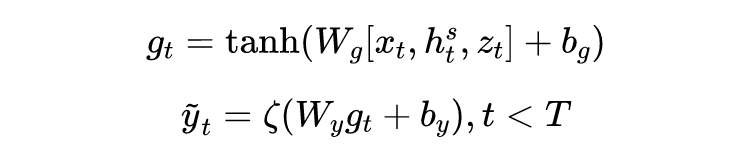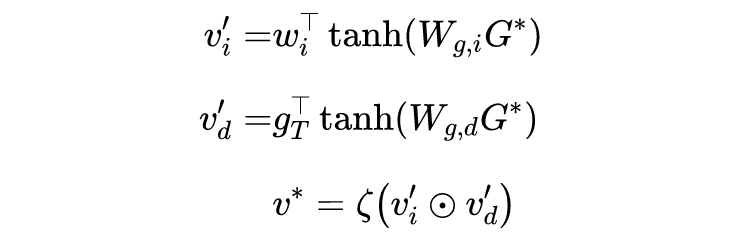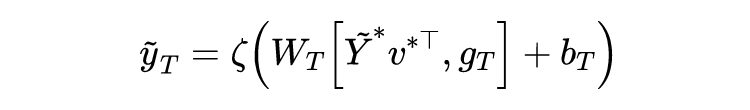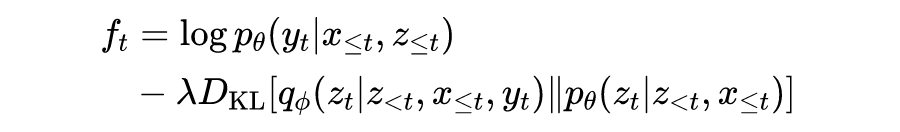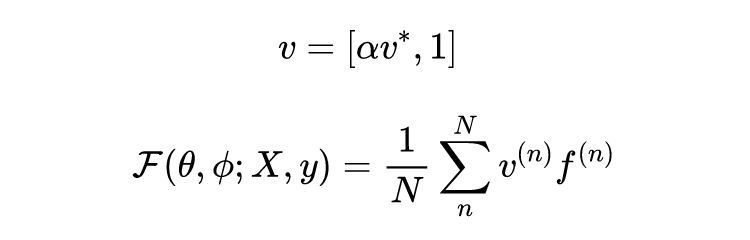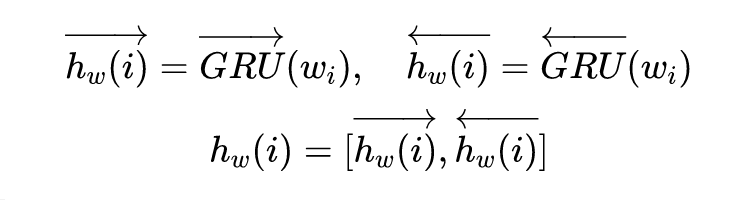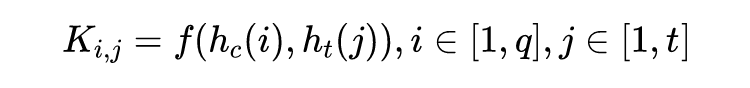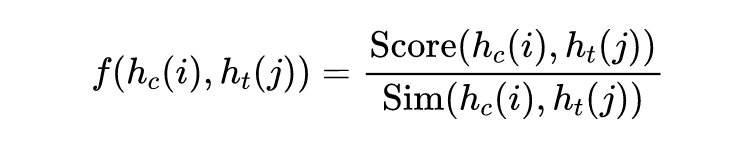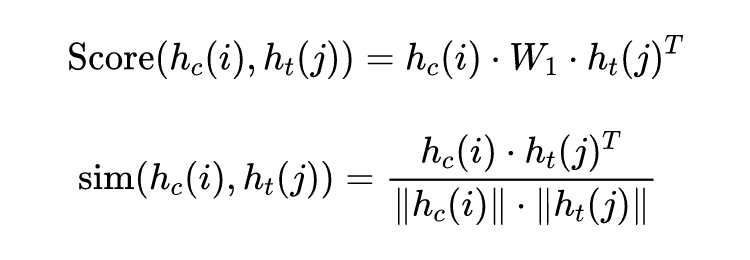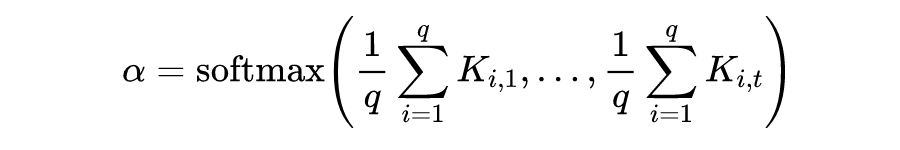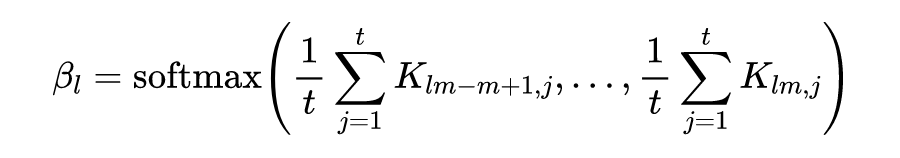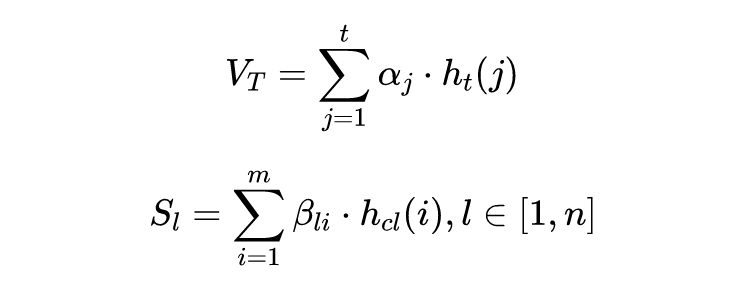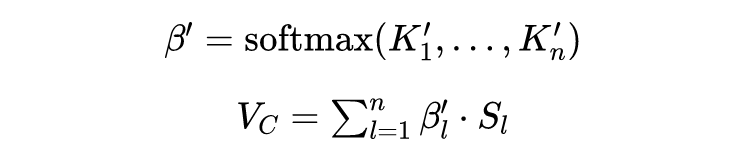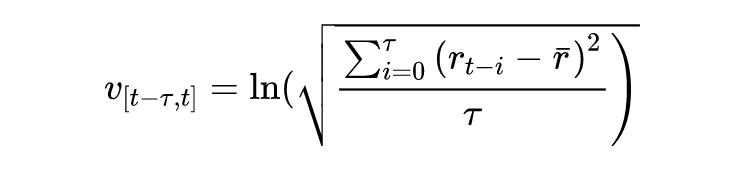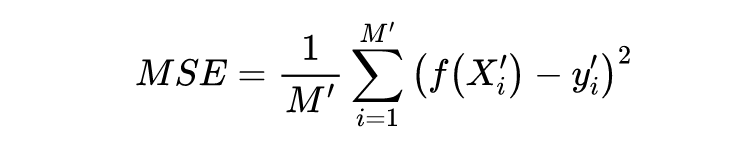©PaperWeekly 原创 · 作者|桑运鑫
单位|上海交通大学硕士生
研究方向|图神经网络在金融领域的应用
本文主要回顾三篇利用文本信息和音频信息进行量化交易的文章。
StockNet
论文标题: Stock Movement Prediction from Tweets and Historical Prices
论文来源: ACL 2018
论文链接: https://www.aclweb.org/anthology/P18-1183/
代码链接: https://github.com/yumoxu/stocknet-code
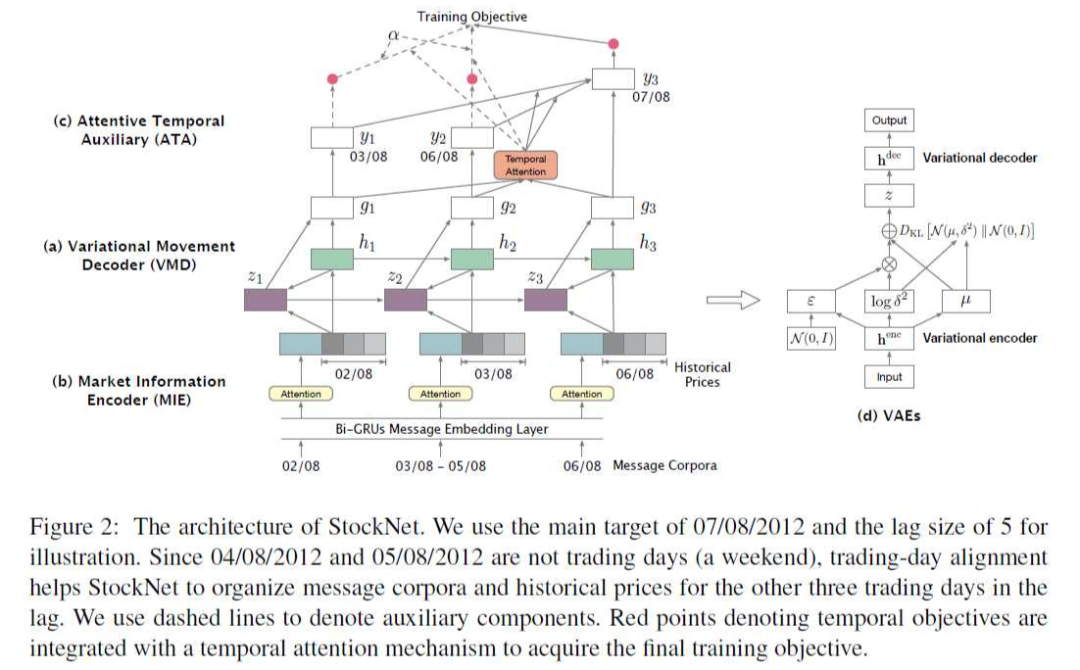
文章指出,股票市场具有高随机性(high market stochasticity),噪声信息(chaotic market information)和时序依赖预测(temporally-dependent prediction)三个特点,为此作者提出了称为 StockNet 的架构用于解决上述问题,并利用 tweet 信息来增强股票预测。
其中 MIE 直接从文本中提取信息,用于充分利用市场信息。VMD 用于融合随机因素。ATA 使用一个延迟窗口(lag window)来获取预测依赖。
一般来说股价比较小的波动我们不会将其标记为涨或跌,而是会作为 preserve 类,但本文直接设定了阈值,将波动幅度在 (-0.5%, 0.55%] 的数据丢弃。
对于 tweet 数据的建模,使用双向 GRU 获取其隐向量:
之后通过一个 Attention 机制将时刻
股票的全部信息聚合成矩阵
,利用一个 Attention 机制获取一个固定长度的向量:
这里的
是 softmax 函数。拼接股票的历史价格数据
作为 VMD 的输入
:
VMD 的思路来自变分自编码器(VAE,相关的介绍可以看变分自编码器介绍、推导及实现
[1]
),总的来说就是我们想要获得一个分布
,但这个分布因为先验
不知道所以不可解,这时候我们使用一个
来近似这个分布,利用优化算法不断缩小两个分布间的距离就可以近似获得
。
因为股票数据具有时序性,所以 VMD 使用 RNN 来获取序列表示:
利用神经网络获取近似分布
(我们默认它是正态分布)的均值与方差:
最终获取预测结果:
传统的 VAE 会将
视作标准正态分布
,但这里将这个分布的均值和方差同样使用神经网络进行了计算:
通过上述过程我们已经获得了一系列可用于辅助预测的历史数据
。历史数据对最终结果的影响可以通过 Attention 机制分成两部分:信息分数(information score)
和依赖分数(dependency score)
:
最终时刻
的预测结果由 VMD 的结果
和 ATA 两部分的结果融合给出:
时刻
的损失函数由两部分组成,似然函数部分和 KL 散度:
对于整体的预测损失,使用之前的
来做权重进行加总:
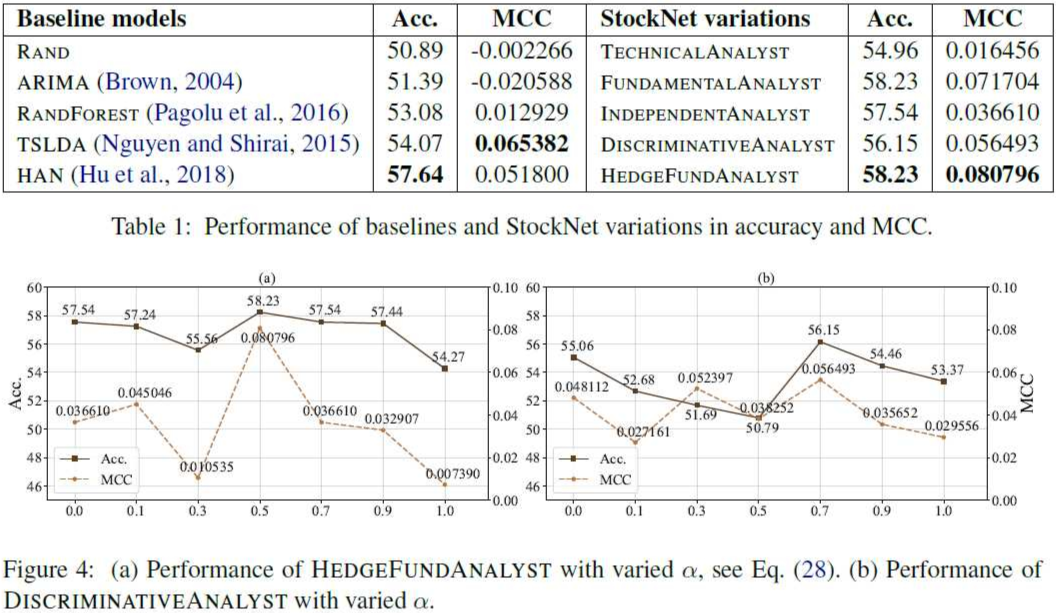
实验使用了 5 天的延迟窗口,并对 5 中 baseline 和 5 种变体:TECHNICALANALYST(只使用历史价格数据)、FUNDAMENTALANALYST(只使用 tweet 数据)、INDEPENDENTANALYST(不包括 TAT 模块)、DISCRIMINATIVEANALYST(在目标函数中去除 KL 散度)。结果证明了模型及各部分的有效性。
HCAN
论文标题: Hierarchical Complementary Attention Network for Predicting Stock Price Movements with News
论文来源: CIKM 2018
论文链接: https://dl.acm.org/doi/10.1145/3269206.3269286
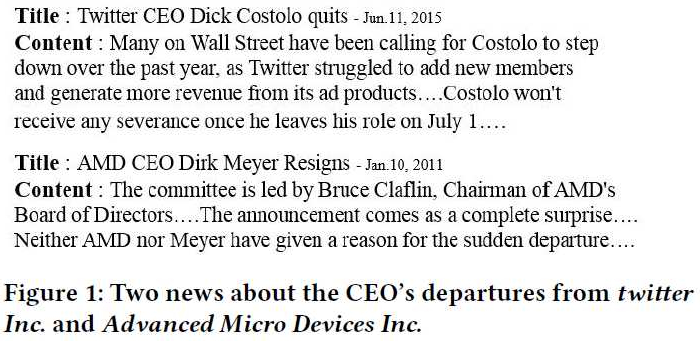
股价会收到新闻的影响,但是现在很多的研究只使用了新闻标题用于预测股价,因为新闻的内容可能包含无关内容影响预测准确率。但是在文章内容中也包含一定的信息,如下图所示,虽然都是 CEO 离职的信息,但对股价的影响是不同的。
因此这篇文章提出了一种称为 hierarchical complementary attention network (HCAN) 的框架,通过两层的 attention 机制来获取新闻标题和内容中的有价值信息。
对于新闻标题和内容中的每个词,首先通过 Bi-GRU 获取它的隐向量。
HCAN 的核心部分就是 Word-Level Attention 和 Sentence-Level Attention 两层注意力机制,分别对词和句子进行加权平均,获取有效信息。
在 word-level 上,使用一种 score-inverse similarity (S-IS) 来计算标题和内容中的词之间的注意力矩阵:
对于内容中的第
个词和标题中的第
个词,
计算如下:
这里的 score 衡量了内容和标题中不同词的相关关系,sim 测量了两个单词的相似程度:
之后可以利用 softmax 函数计算出对内容和标题进行加权的注意力权重
和
:
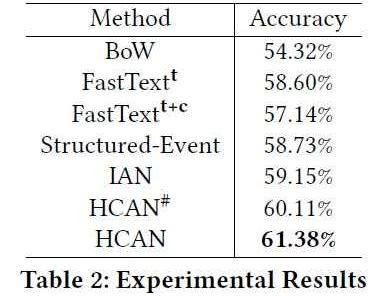
在实验方面设置了 BoW(词袋模型)、FastText(对标题、对标题和文本)、Structured-Event(提取结构化事件)、IAN(只使用 word-level attention,拼接进行预测),在 2007 年到 2012 年的 Returns 新闻和标准普尔 500 的股票涨跌预测上表现良好:
MDRM
论文标题: What You Say and How You Say It Matters: Predicting Financial Risk Using Verbal and Vocal Cues
论文来源: ACL 2019
论文链接: https://www.aclweb.org/anthology/P19-1038
这篇文章发在了 ACL 2019 上。预测金融市场的风险是金融从业人员关心的话题,而我们可以利用大量的公开信息来预测股价波动,其中 earning conference call 是一个重要的信息来源。
earning conference call 是公司向所有相关方(包括机构和个人投资者)以及买方和卖方分析师传递信息的一种方式。earning conference call 允许公司强调繁荣时期的成功,并在不利时期平息恐惧。
通常公司举行 earning conference call 的时间是在每个季度的财务报告发布之后(通常在每个季度末)之后。以往的研究主要集中在对于这个会议的文本信息研究上,但研究显示,音频信息也十分重要(文章给出一个例子,对冲基金雇佣前 CIA雇员解读公司管理层在公开场合的语音语调等线索,还有这种骚操作,我服了……)。
earning conference call 包括两部分:introduction 和 question-and-answer 部分。在 introduction 部分,CEO 或 CFO 会做一些陈述报告,解释在这个季度的财务表现。在 QA 环节,分析师可以提问题要求管理层解释某些问题或提供一些之前没有提到的问题.
earning conference call 经常会导致股价的明显波动。作者在文章中构建了一个数据集 S&P 500 Earnings Conference Calls dataset
[2]
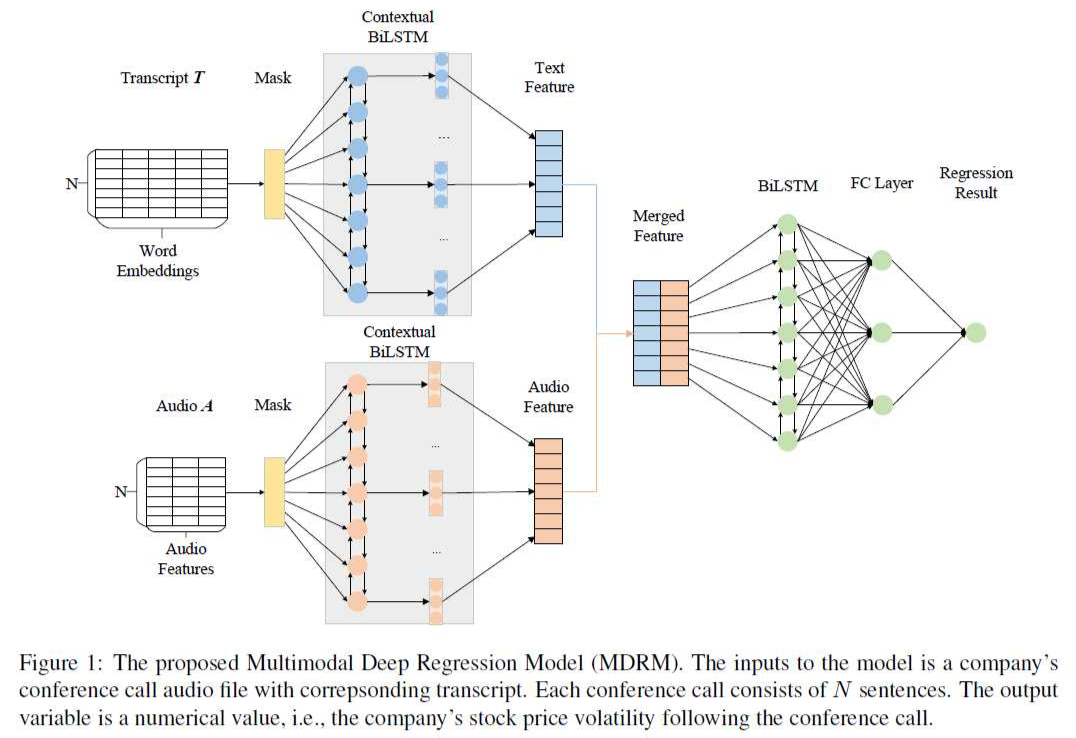
,收集了 2017 年 S&P 500 成分股的 earnings conference calls 中 CEO 的发言文本特征及音频特征。之后提出了一个称为 multimodal deep regression model (MDRM) 的模型,如下图所示。
这个模型比较简单,首先是利用 Contextual BiLSTM(BiLSTM+一层 NN+RELU激活)来获取每个句子的隐向量。之后拼接输入一个 BiLSTM 和两层 NN 完成预测。
其中
是第
天的收益率
,
是
时段的平均收益率,实验选择
来测试短期预测和长期预测的有效性。
使用均方误差作为损失函数:
所有的模态都是有用的,增加模态信息可以缓解过拟合问题
一些个人的音频特征是十分重要的。case study 中提到,在 AMD 2017 年 5 月 1 日的 earnings conference call 后,股价跌了 16.1%。在会议上,CEO 说的“Overall, from a performance standpoint, the product and the customer engagements are going as we would expect”时,尽管这句话在文本上看是积极的,但他声音的 mean pitch 比起平均提高了 20% 的,而根据之前的研究,这是不自信的表现(emmm...)
短期波动预测是困难的。模型对短期波动预测的 MSE 显著高于长期预测的 MSE
模型相对简单模型的边际收益随着时间的延长在逐渐消失。这符合有效市场假说。
总结
虽然公开信息(新闻、财报、会议等)对于股价的影响是显而易见的,但利用这一类信息对股价进行预测对信息的获取和处理速度要求比较高(上面的文章已经指出长期预测的边际收益在下降),更适合用于短期内的预测,而且存在过拟合、噪声等问题,对这个方向的研究还有很长的路要走。
因为相关的资料确实相当匮乏,我在 GitHub 上新建了一个 repo 用于收集、整理相关的研究论文、书籍、数据、网站等,欢迎 star。
https://github.com/sangyx/deep-stock
如果您对深度学习在量化交易中的应用感兴趣,欢迎加我微信一起学习探讨(请备注一下姓名, 机构或研究方向)。
[1] https://zhuanlan.zhihu.com/p/83865427
[ 2] https://github.com/GeminiLn/EarningsCall_Dataset
点击以下标题查看更多往期内容:
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读 ,也可以是学习心得 或技术干货 。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品 ,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱: hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」 也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」 订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」 ,小助手将把你带入 PaperWeekly 的交流群里。