分别基于SVM和ARIMA模型的股票预测 Python实现 附Github源码

大数据挖掘DT数据分析 公众号: datadw
本文代码上传Github
在公众号里回复关键字“股票预测”获取地址。
SVM 支持向量机
原理就不赘述了,相关文章可以看这里
SVM是一种十分优秀的分类算法,使用SVM也能给股票进行一定程度上的预测。
核心
因为是分类算法,因此不像ARIMA一样预测的是时序。分类就要有东西可分,因此将当日涨记为1,跌记为0,作为分类的依据。使用历史数据作为训练数据。
处理数据:
股票历史数据来源于yahoo_finance api,获取其中Open,Close,Low,High,Volume作为基础。因为除去Volume以外,其余数据都是Price,基于Price并不能很好的表达股票的特性,或者说并不太适用于SVM分类算法的特性。基于SVM算法的特性,股票并不是到达一个价格范围就有大概率涨或跌(不知道我这个表达大家能不能看懂)。
2.基于上述原因,我决定将Price转换成另一种形式的数据。例如:High-Low=全天最大价格差,Open-YesterdayOpen=当天Open价格变动,Open-YesterdayClose=开盘价格变动。(我也并不太懂经济学,仅仅是为了寻找另一种更好的方案)
3.单纯地基于历史数据是完全不够的,因此还使用了R语言和tm.plugin.sentiment包,进行语义分析,进行新闻正面负面的判定。这块不是我做的,了解的并不多。新闻并不是每天都有的,这样的话新闻数据就显得有些鸡肋,无法在分类算法中起到作用,但是我们能在多个站点中提取,或是直接将关键字定为Debt(判断大众反应)。
4.这里仅仅是进行了两个站点的新闻挖掘,然后可通过rpy2包在Python中运行R语言,或是R语言得到的数据导出成Json,Python再读取。至此,数据处理告一段落。
SVM算法:
股票数据不能完全基于历史数据,因此需要一定数量的历史数据推出预测数据,例如这边使用了70天的数据训练,来推出后一天的股票涨跌,而不是所有的历史数据。
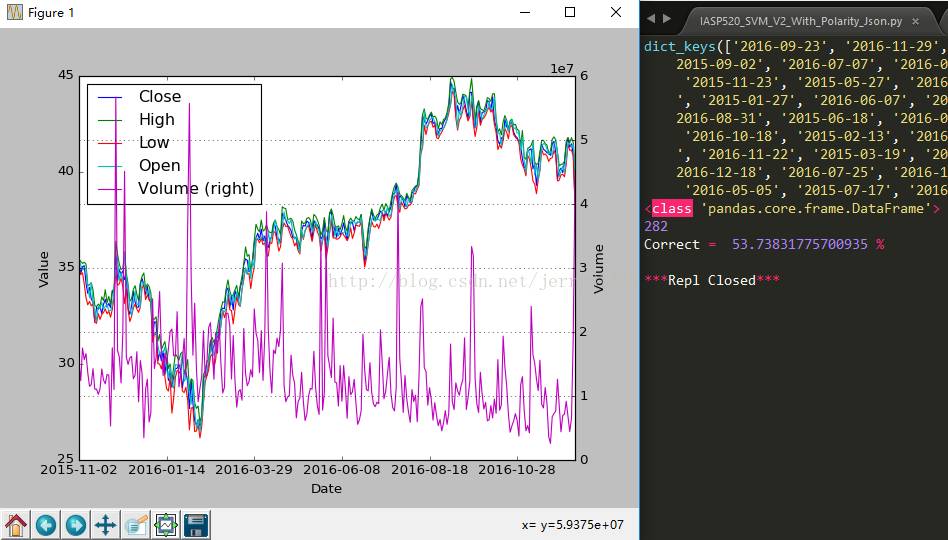
最后的成绩是53.74%的正确率,对于一个基本使用历史数据来预测股市的方法而言已经是个不错的结局了。
ARIMA
全称为自回归积分滑动平均模型(Autoregressive Integrated Moving Average Model,简记ARIMA)。核心函数是ARIMA(p,d,q)称为差分自回归移动平均模型,AR是自回归, p为自回归项; MA为移动平均,q为移动平均项数,d为时间序列成为平稳时所做的差分次数。所谓ARIMA模型,是指将非平稳时间序列转化为平稳时间序列,然后将因变量仅对它的滞后值以及随机误差项的现值和滞后值进行回归所建立的模型。
相关文章
时间序列ARIMA模型详解:python实现店铺一周销售量预测
核心
整个算法的核心,就是ARIMA中d差分将时序差分成平稳时序或是趋于平稳时序,然后基于PACF设置p自回归项,基于ACF设置q移动平均项数。
但因为包是基于statsmodels的,而其中的ARIMA(p,d,q),d不能>2,因此选用ARIMA(p,q)函数,d则使用pandas.diff()来实现。
步骤
本系统使用yahoo_finance,pandas,numpy,matplotlib,statsmodels,scipy,pywt这些包
1.从yahoo_finance包中获取股票信息,使用panda存储及处理数据,只提取其中Close属性,按照时间排序为时间序列。
2.对Close时序进行小波分解处理,选用DB4进行小波分解,消除噪音。
3.进行差分运算,使用panda包的diff()方法,并使用ADF检验进行平稳性检验,保证时间序列是平稳或趋于平稳的。
4.输出ACF,PACF图,确定p,q的值。
5.运用ARIMA模型对平稳序列进行预测,ARIMA(p,q)。
6.还原差分运算,得到股票预测时序。
输出图
本图顺序与步骤顺序无关,仅仅是作为一种直观的展示:
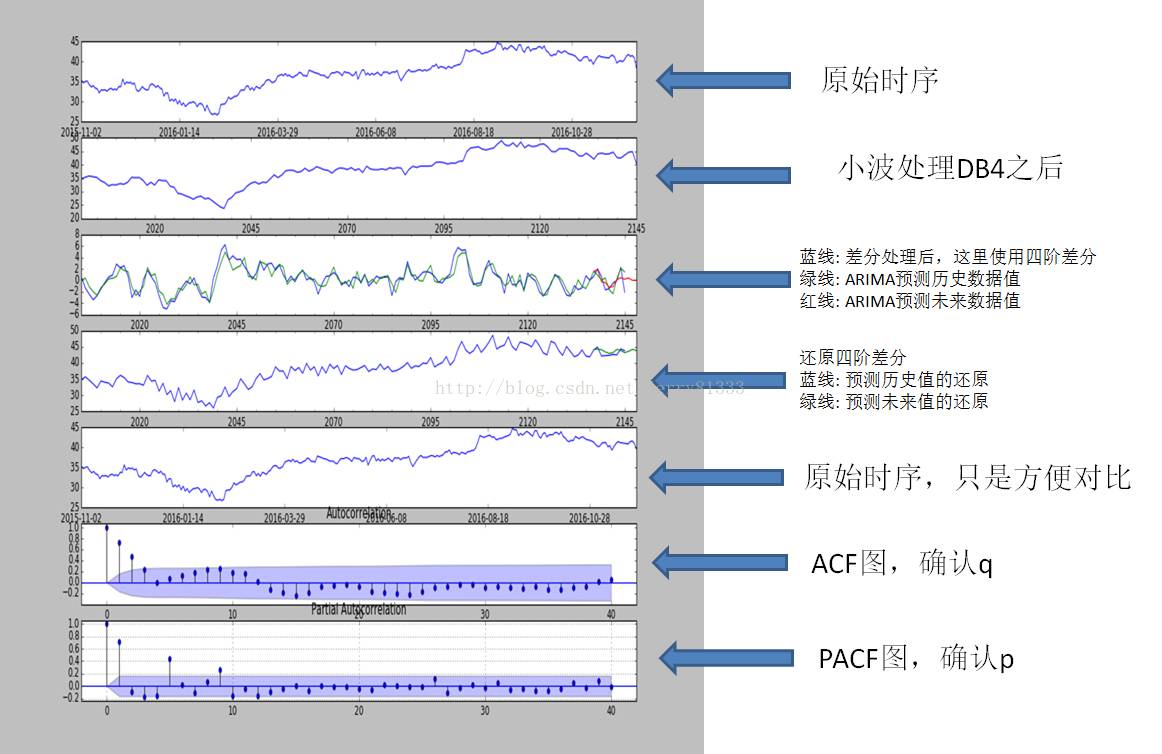
总结
ARIMA是一种处理时序的方法模型,可以作用于股票预测,但是效果只能说是一般,因为股市预测有一定的时序关系,却又不完全是基于时序关系,还有社会关系,公司运营,新闻,政策等影响,而且ARIMA使用的数据量仅仅只有一阶的Close属性。因此本模型可以作用在平稳发展,没有什么负面新闻和政策干扰的公司。
人工智能大数据与深度学习
搜索添加微信公众号:weic2c

长按图片,识别二维码,点关注
大数据挖掘DT数据分析
搜索添加微信公众号:datadw
教你机器学习,教你数据挖掘

长按图片,识别二维码,点关注


