制作一个展示网站发展的Gif

为了参加最近的StackExchange的“time”主题比赛,我制作了一个Gif来展示StackOverflow网站从2008年 到今天的发展历程:
这里是一张GIF图片,可以点击阅读原文查看。图片太大,无法插入公众号文章。
(点击图片重新播放)
第一步是为Internet Archive找到一个合适的API。它支持Memento,这是2013年RFC 7089中定义的基于http的协议。使用memento_client包装器,我们可以使用以下Python代码得到网站最接近给定日期的快照:
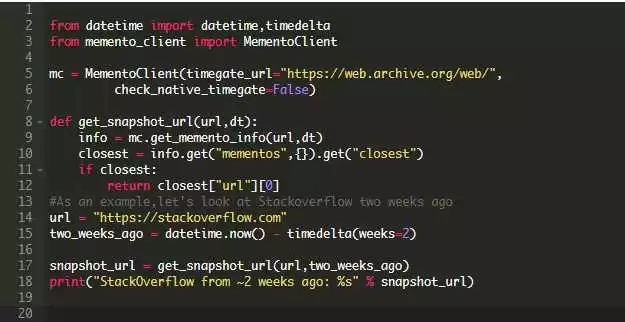
不要忘记安装memento_client 库哦:
pip install memento_client
请注意,此代码会给我们一个最接近的快照,所以不可能确切地是两周以前的。
通过使用一个持续增加的时间增量,我们可以循环此段代码来获取不同 时间的快照。但我们不只是想获取URL。我们还想对每一个网页都做一个截图。
以编程方式获取网页截图的最简单方法可能是使用Selenium。我用Chrome作为驱动程序;你可以从ChromeDriver网站下载,也可以在使用Homebrew包管理器的Mac电脑上运行以下命令:
brew install bfontaine /utils/ chromedriver
我们还需要为Python安装Selenium:
pip install selenium
代码很短:
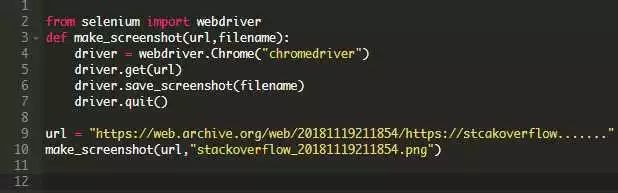
如果你运行上面的代码,你会看到一个Chrome窗口自动打开,并自动去访问URL,当页面全部加载后自动关闭。然后你就获得了一个该页面的截图,文件名是 stackoverflow_20181119211854.png!然而,很快你就会注意到这个截图中网站的最上面有Wayback Machine(一款网页备份工具)的页眉。

这在手动浏览快照时非常方便,但在从Python访问快照时就不那么方便了。
幸运的是,我们可以通过稍微修改URL来获得一个无页眉的URL:我们可以将 id _ 添加到日期的末尾,以便获得与机器爬取时完全相同的页面。当然,这意味着它会链接到可能不再存在的CSS和JS文件。通过用im_替代id_,我们也可以得到一个链接到经过稍微修改的存档页面的URL,用它来替换原始的存档页面。
带有页眉和重写链接的页面:
https://web.archive.org/web/20181119211854/...
原始页面,跟爬取的页面一样:
https://web.archive.org/web/20181119211854id_/...
重写链接后的原始页面:
https://web.archive.org/web/20181119211854im_/...
使用修改后的URL重新运行代码会得到正确的截图:

将这两段代码组合起来,我们可以在不同的时间间隔对URL进行截图。你可能想在截图完成时检查图片,并删除不一致的图片。例如,谷歌主页的存档快照并不是一直都是同一种语言。
一旦得到了所有的图片,我们就可以使用Imagemagick生成一个gif:
convert –delay 50 –loop 1 *.jpg stackoverflow.gif
我使用了以下参数:
–delay 50:每0.5s改变画面。数字代表每1/100秒。
–loop 1:对所有画面只循环一次。默认情况下是进行无限循环,但在这里没有意义。
你可能想要使用-delay参数进行播放,这取决于你有多少图片以及网站改变的频率。
我也做了一个谷歌版本(约10MB)的gif,每秒5帧,并使用了 –delay 20参数。我使用了与StackOverflow gif相同的延迟时间::每个截图之间至少间隔5周。通过查看每张图片的底部,你可以看到每个截图来自哪一年。
2018年 12月3日-#experiments,#imagemagick,#python,#selenium
——Baptiste Fontaine"s Blog
英文原文:https://qiniumedia.freelycode.com/vcdn/1/%E4%BC%98%E8%B4%A8%E6%96%87%E7%AB%A0%E9%95%BF%E5%9B%BE2/record-website-change-gif.pdf
译者:浣熊君( ・᷄৺・᷅ )




