使用 Python 绘制《星战》词云
点击上方
Datartisan数据工匠
可以订阅哦!
作者介绍
Rafael Schultze-Kraft
“前神经科学家,数据挖掘及机器学习的狂热爱好者,Python 的狂热粉丝”
使用 Python 绘制《星战》词云
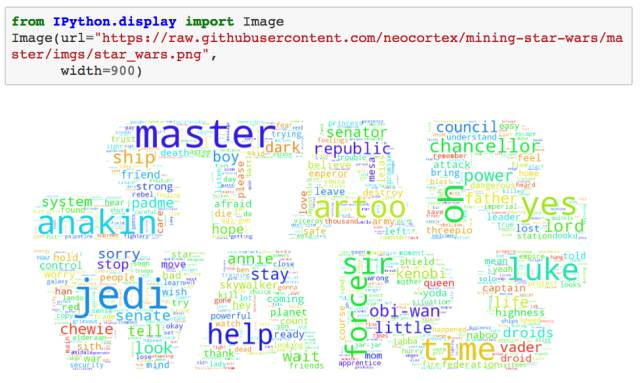
当前我们在 Jupyter Notebook 中推进的是一个有趣的小项目,它的目标是将星球大战中的角色可视化为词云 —— 也就是说,从星战系列 1-6 部中的角色台词出发,找到最能刻画他们的人物特征的词语。
因此,我爬取了星战系列 1-6 部的电影剧本,提取出星战中每个角色的台词内容,并经过进一步的加工处理,对每一个人物角色进行词云可视化。
本文介绍了一些基本的数据科学概念,演示了一些 Python 库的使用,包括了爬虫库(requests 和 beautifulSoup)、自然语言处理库(NLTK、string 和 re)、词云库(Andreas Muller 的 wordcloud),以及可视化库(matplotlib)。
电影剧本的数据来源是 IMSDb(该数据库仅可用于教育目的)。
你能在我的 GitHub(https://github.com/neocortex/mining-star-wars) 上找到本文的所有代码。其实,我早在 2016 年的 EuroPython 大会上分享过此项目实例。
让我们开始着手做吧!
(下面的第一条代码纯粹是为了避免在 notebook 输出时出现警告内容,影响美观)

导入必备模块
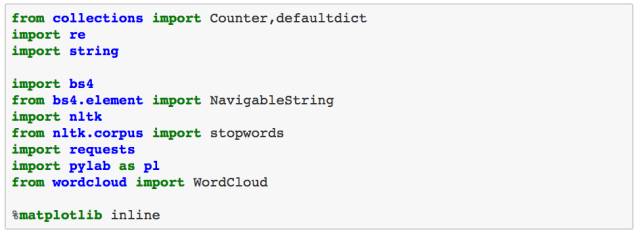
首先,我们需要导入一些后文中一定会用到的库。正如前文所说,为了爬取包含电影剧本的 HTML 页面,我会结合使用 requests 和 BeautifulSoup,requests 用来发起 HTTP 请求,而 BeautifulSoup 用来解析 HTML 页面,并提取出我们想要的内容。另外,我们还需要导入一些辅助性的库(比如 collections),用来处理字符的库(re、string 和 nltk),用来画图的 matplotlib 库,以及用来生成词云的 wordcloud 库。
数据来源
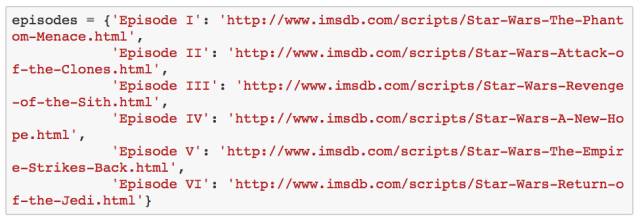
正如前文中提到的,我会把 IMDSb (http://www.imsdb.com/ )作为我们的数据源。下面我将建立一个字典,用来存储星战系列电影名称及其对应的数据库链接。
抓取数据
星战系列之四 —— 新希望


我会按照电影上映的日期来进行爬取,因此我首先爬取星战系列中的第四部。我们只需要简单地构造一个包含目标链接的 GET 请求,就可以得到电影剧本了。得到的响应内容则会被转换为一个 BeautifulSoup 对象。

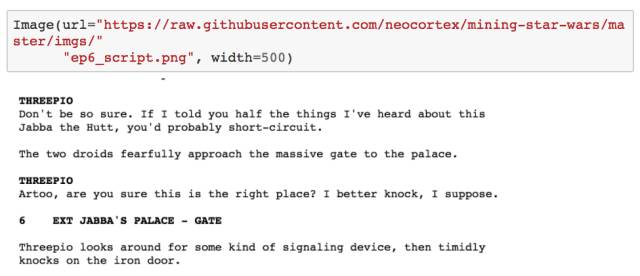
HTML 页面源码混合了文本、标签、JavaScript 脚本等内容。幸运的是,BeautifulSoup 能帮助我们解析这些 HTML 页面,从而取得我们想要的文本信息。 因此,为了得到电影中每个人物的台词,我们需要查看 HTML 的结构,看看怎样才能提取出我们所需要的内容。下图是星战第四部剧本的部分 HTML 页面截图。
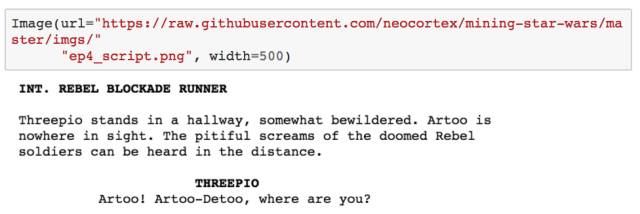
在快速查看 HTML 源码后,我发现,嵌入了人物名称(比如 THREEPIO)的 <b> 标签下紧跟着的便是对应人物的台词内容。然而,我发现,人物对话发生的位置场景描述(比如,INT. REBEL BLOCKADE RUNNER)也以同样的结构被放在了 HTML 源码中。两者的区别在于,包含人物名称的 <b> 标签缩进得更多(实际上确切来说,缩进了 37 个空格)。因此,我采用的爬取方式是遍历 soup 中的所有 <b> 标签,并且检查该 <b> 标签是否至少缩进了 37 个空格(否则该 <b> 标签下的文本内容应该是位置场景描述),若是的话,我们便只需要提取出该 <b> 标签的闭合标签后紧跟的文本内容,就能得到人物台词了。
最后,我遍历了对话的每一行(直至遇到空行),由于以 “(” 开头的句子是描述性的内容,和对话中的人物台词无关,所以我还需要过滤掉它们。
听起来好像有点复杂,但实际上真的挺简单的。代码如下:

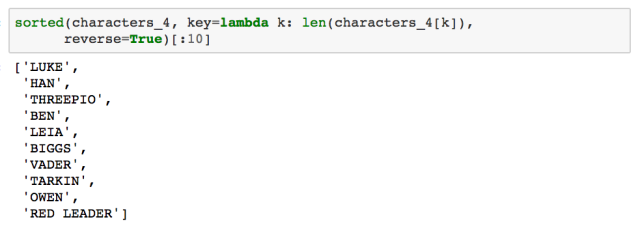
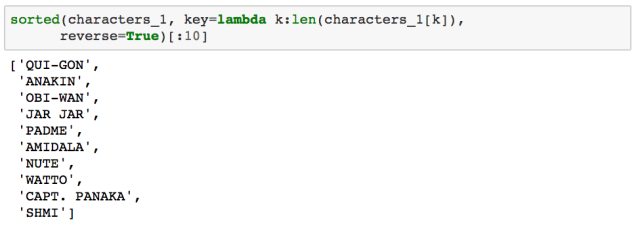
爬取出来的结果是以字典格式存储的,形如,{角色名称:台词}。这能让我们得到星战四中台词数排名前十的人物角色:
下面给出字典中一个角色(Darth Vader)台词的示例:


目前一切都进展得很顺利!让我们接下来看看星战五的情况:
星战系列之五 —— 帝国反击战


系列之五的爬取和上面的爬取方法基本一致,唯一的区别在于,位置场景描述和人物角色对话处的 <b> 标签的缩进数,与第四部中的不一样。在第五部中,没有用空格缩进,而是用 tab 来缩进的。除此之外,对话的提取方法和上文是完全一致的。
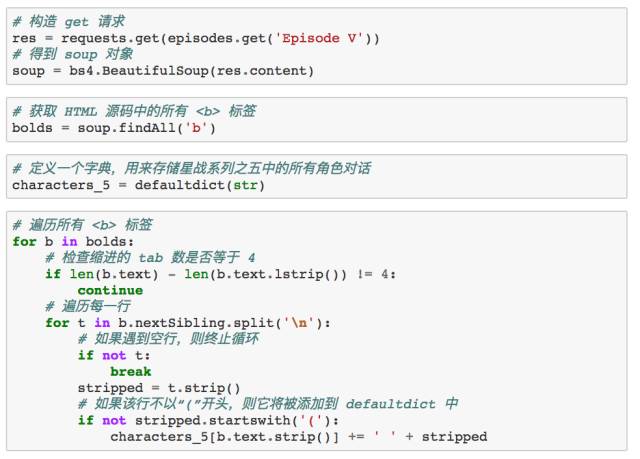
第五部中台词数排名前十的人物角色是:
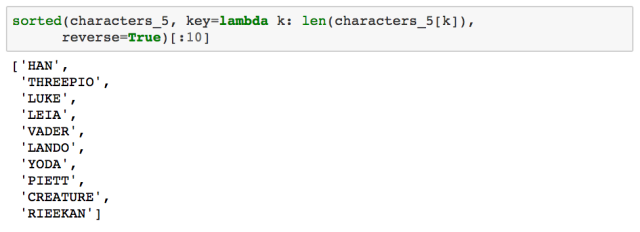
让我们再来看看星战系列之六的情况。
星战系列之六 —— 绝地归来


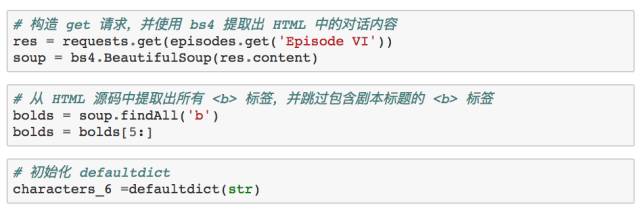
在《绝地归来》中,提取对话的方式和之前几部的有些不一样。同样地,<b> 标签之间既包含了角色对话,也包含了对位置场景的描述。然而,区分两者的方式发生了变化:位置场景描述的前面多了一个数字(对话格式依然保持不变)。
因此,我们可以简单地遍历所有 <b> 标签,检查其中嵌套的文本内容是否始于数字,如果不是始于数字,则表明该内容是角色名称,那么接下来的步骤和前面几部的是一样的。

星战系列之一 —— 幽灵的威胁


星战一的文本提取方法与之前的方法不同。通过查看 HTML 源码,我们发现了剧本内容被写入了 <pre> 标签中。因此,第一步就是把这些内容提取出来。

我们需要遍历上面提取出来的 <pre> 节点的所有孩子节点,才能提取出对话内容。通过识别双换行符 \n\n 来拆分文本,我们可以得到这些孩子节点中的文本所包含的每个段落。
另外,角色名称后面跟着一个冒号表示这是一段对话,因此,如果我们利用冒号对文本段落再次进行拆分,若分裂出来的只有一个部分,则我们可以认为该段落不属于对话。最后,为了确保当前行是一段对话,我们还需要检查拆分出来的第一部分是否是大写的(即角色名称),并且移除括号里的文本。

星战系列之二 —— 克隆人的进攻


《克隆人的进攻》的对话提取方法和星战五的方法相似。我再次遍历所有 <b> 标签,并确保文本缩进长度等于 4。基于此,对于 <b> 标签的闭合标签后的内容的每一行,我还检查了其缩进数是否正好为 3,这些判断确保了该行的确属于对话内容(而不是其他剧本内容)。 注:这些提取特点都能通过查看 HTML 源码得知。
星战系列之三 —— 西斯的复仇


已经到了最后一部啦!在查看 HTML 源码后,对话文本的提取在这里开始变得相当简单:我们简单地遍历 <body> 标签下的每一行(使用双换行符 \n\n 来拆分文本)—— 如果该行包含一个冒号,并且拆分出来的第一部分是大写的,则当前行即为对话文本...以上便是我们所需要完成的步骤。
合并分析
我们已经得到了从每部剧集中提取出来的对话内容,接下来,我们会将这些对话内容整合到单个字典中。老实说,我们可以从一开始就使用单个字典来存储这些剧集中的对话内容。我没有这样做的原因在于,考虑到有人可能想要分析这些剧集之间的关系。

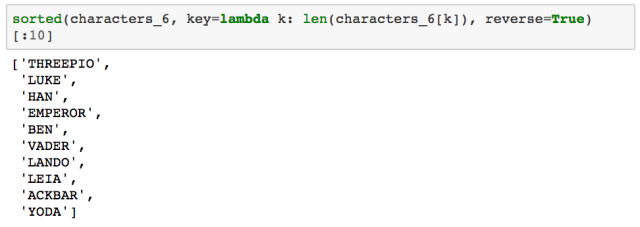
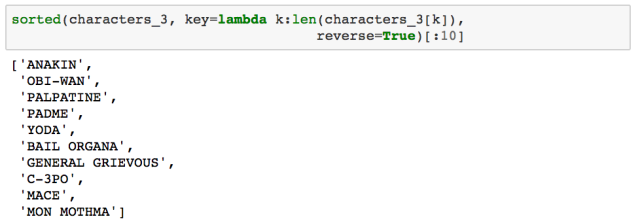
最后,我们列出了对话中台词数排名前 100 的角色名称:




细心的读者可能会发现,实际上属于同一角色的台词条目,却被划分给了“多个”角色,比如,“BEN” 和 “BEN'S VOICE”,以及 “PADM\xc9” 和 “PADME”。因此,接下来,我定义了一个函数,将这些台词条目合并给同一个角色。并且我决定将系列一至系列三中的 OBI-WAN,和系列四至系列六中的 BEN 当成两个独立的角色。


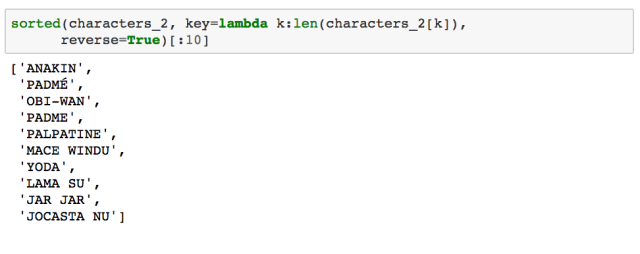
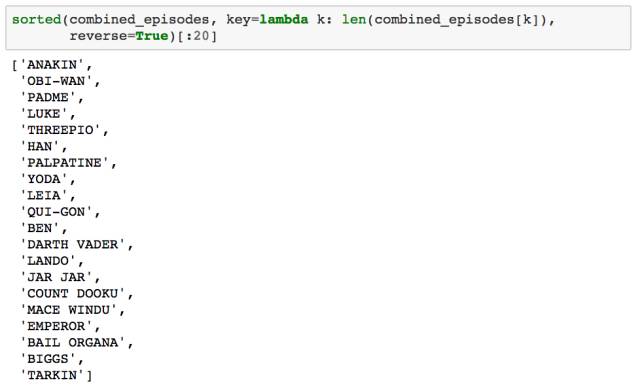
同样地,通过对各角色在所有剧集中的台词总数进行排序,我们能得到排名前 20 的角色:
进一步的文本预处理
为了对文本进行进一步的预处理,以及生成词云,我选取了下面存在感比较强的角色:

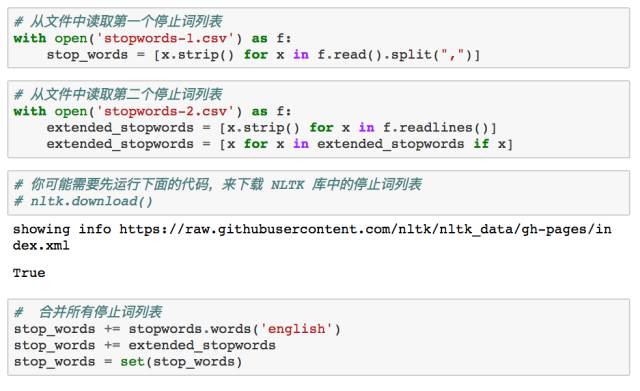
停止词
下一步我们需要做的是,移除提取出来的文本中的停止词。为了达到目的,我使用三个不同的停止词词源:其中两个是我用谷歌搜索到的英文停止词词源,剩下的那个是 Python 的 NLTK 库(http://www.nltk.org/)自带的停止词词库。
清洗文本
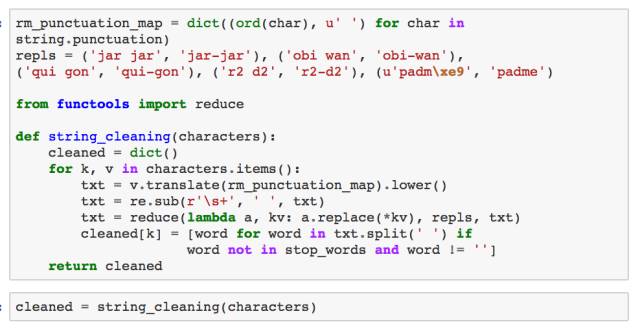
文本的清洗步骤如下:
移除标点符号
给角色名称添加标点符号(例如,“r2 d2” 应该被识别为 “r2-d2”)
移除特殊的字符,比如 tab 和换行符
移除停止词,并把文本拆分成单词列表
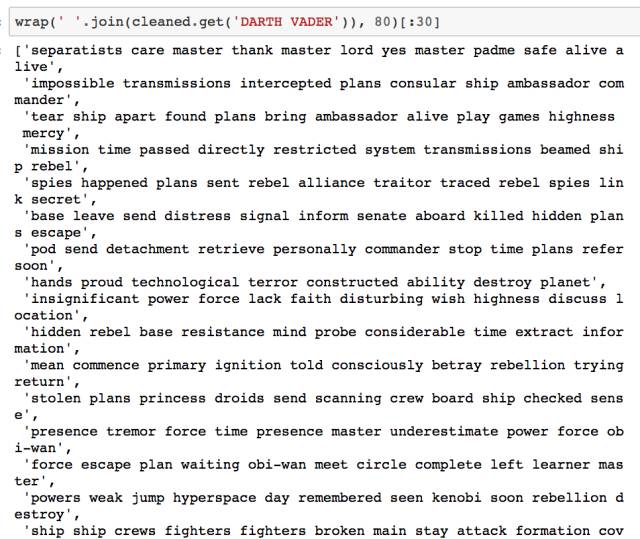
让我们看看经清洗后的文本长什么样子(以 Darth Vader 为例):

词云
是时候生成词云了! 为了达到目的,对于 cleaned 字典中的每个角色而言,我们需要先计算其对应的每个单词的词频(使用 collections库中的 Counter),然后将结果输入到 wordcloud 库中(这就和用单词、频率列表来实例化 WordCloud 类一样简单 —— 事实上,你还可以使用纯文本)。我们接下来会使用 matplotlib 库来展现词云。

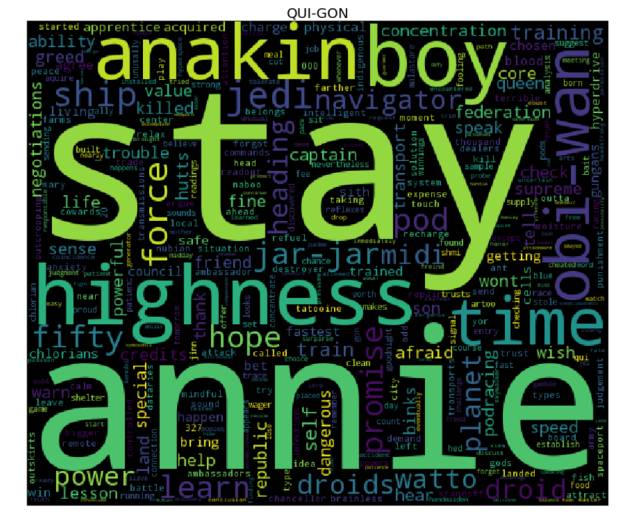
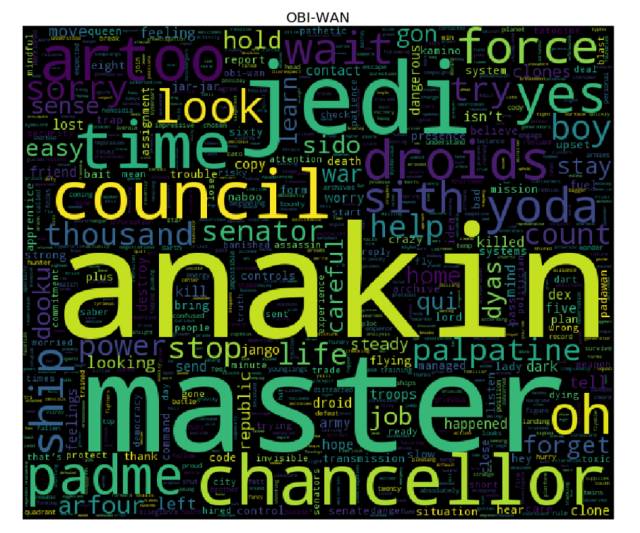
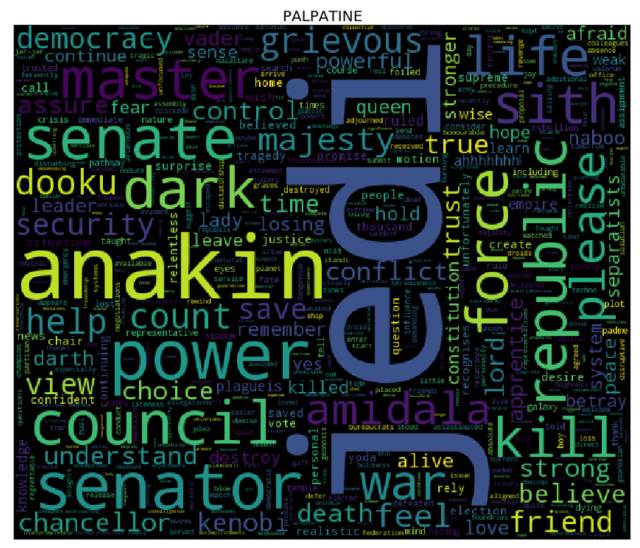
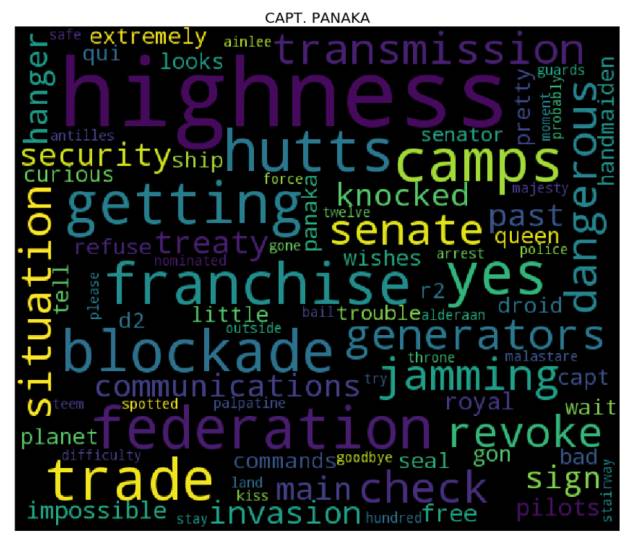

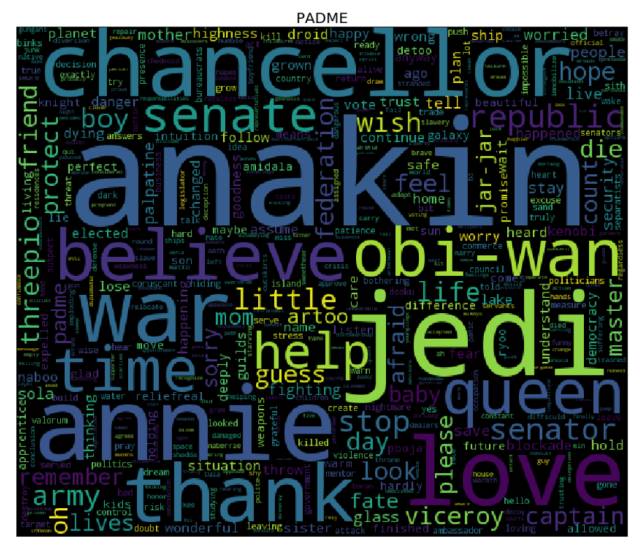
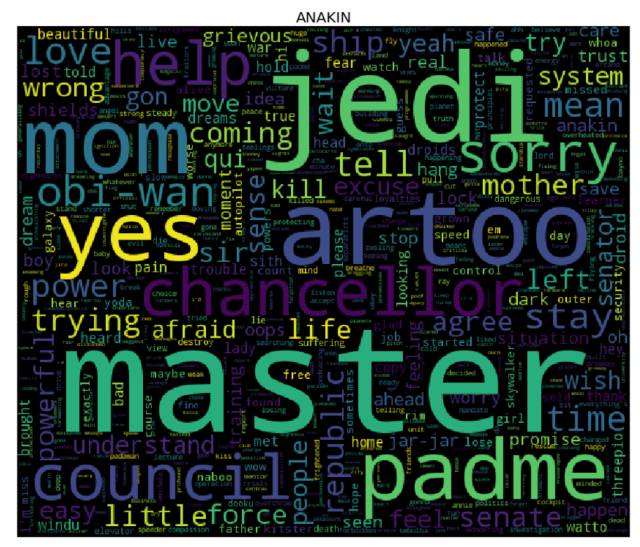
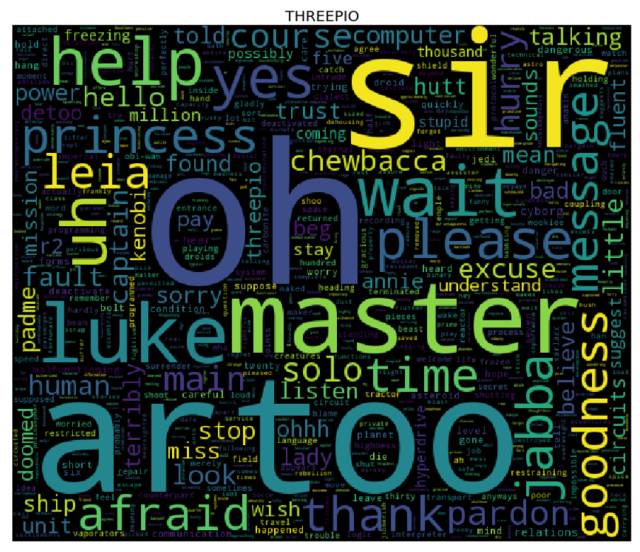
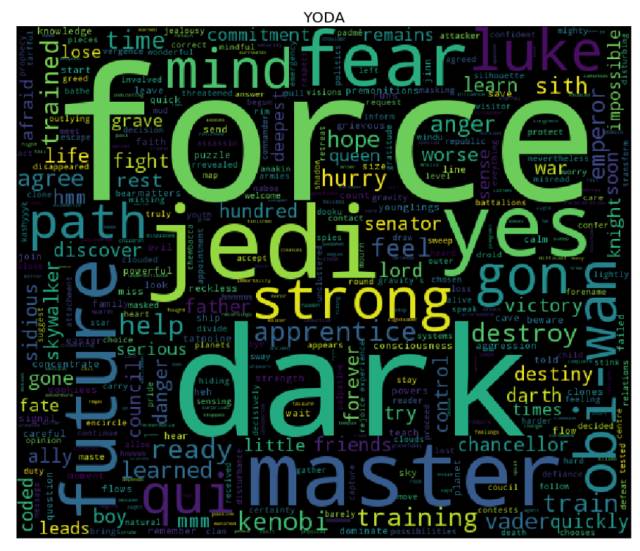
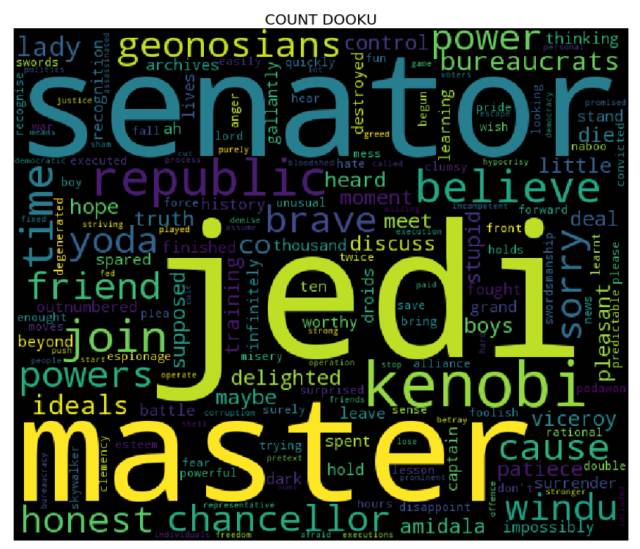





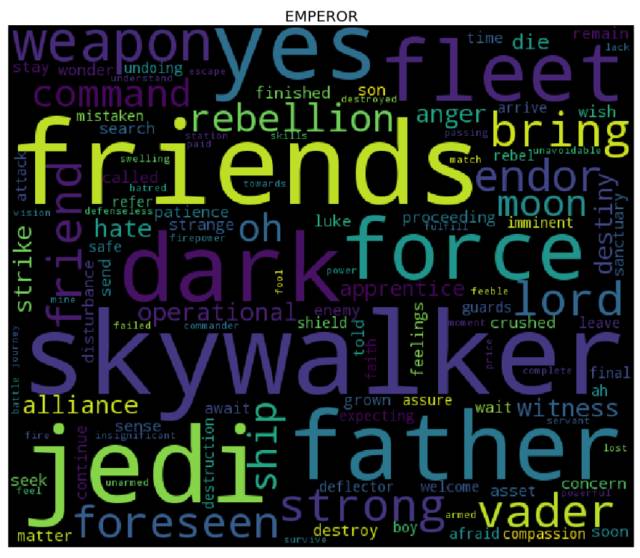
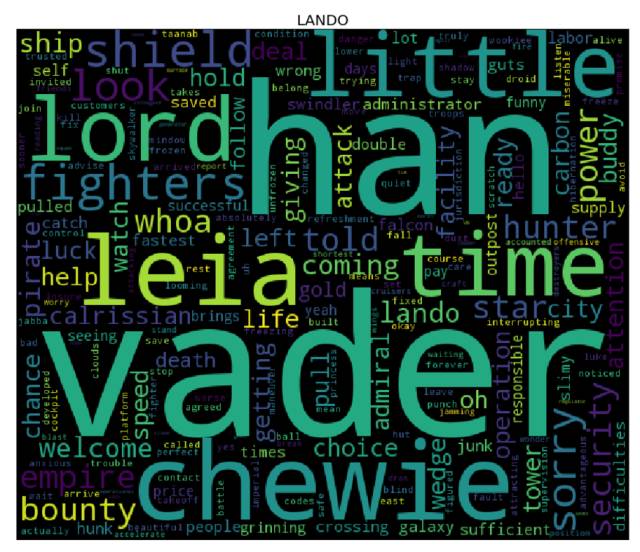

更多课程和文章尽在微信号
「datartisan数据工匠」