又一新框架 | 无监督图像转换任务新境界(附论文代码)
关注并星标
从此不迷路

2020 IEEE国际计算机视觉与模式识别会议(IEEE Conference on Computer Vision and Pattern Recognition,简称CVPR)公布接收论文结果。清华大学计算机系“类脑计算与认知”团队提交的论文《Reusing Discriminators for Encoding Towards UnsupervisedImage-to-Image Translation》被成功接收。论文第一作者为陈润发,是清华大学计算机系硕士二年级研究生;指导老师为孙富春教授(中国人工智能学会副理事长,清华大学教授,IEEE/CAAI Fellow)等。

CAAI认知系统与信息处理专委会
一、无监督背景
无监督学习适用于你具有数据集但无标签的情况。无监督学习采用输入集,并尝试查找数据中的模式。比如,将其组织成群(聚类)或查找异常值(异常检测)。
例如:想像一下,如果你是一个T恤制造商,拥有一堆人的身体测量值。那么你可能就会想要有一个聚类算法,以便将这些测量组合成一组集群,从而决定你生产的XS,S,M,L和XL号衬衫该有多大。
你将在文献中阅读到的一些无监督的学习技术包括:
•自编码(Autoencoding)
http://ufldl.stanford.edu/tutorial/unsupervised/Autoencoders/
•主成分分析(Principal components analysis)
https://www.quora.com/What-is-an-intuitive-explanation-for-PCA
•随机森林(Random forests)
https://en.wikipedia.org/wiki/Random_forest
•K均值聚类(K-means clustering)
https://www.youtube.com/watch?v=RD0nNK51Fp8
无监督学习中最有前景的最新发展之一是Ian Goodfellow(当时在Yoshua Bengio的实验室工作时提出)的一个想法,称为“生成对抗网络(generative adversarial networks)”,其中我们将两个神经网络相互联系:一个网络,我们称之为生成器,负责生成旨在尝试欺骗另一个网络的数据,而这个网络,我们称为鉴别器。这种方法实现了一些令人惊奇的结果,例如可以从文本字符串或手绘草图生成如照片版逼真图片的AI技术。
二、技术背景
随着近几年对抗生成网络(GAN)的快速发展,无监督图像转换任务成为计算机视觉领域的一个热门方向。近几届人工智能领域顶级学术会议上(如CVPR、ECCV、ICCV、NIPS、ICLR等)有关对抗生成网络和图像转换任务的论文数量也呈现爆炸增长的趋势。当我们回顾当前成功的图像转换框架时(例如CycleGAN),大多数都由三个部分组成:
将输入图像嵌入到低维隐层空间的编码器;
将隐层编码转换为其他域图像的生成器;
使用对抗训练进行域对齐的判别器。
尽管这种堆叠方式是标准的,但我们仍然好奇这样的问题:是否有可能重新考虑每个组件在转换框架中的作用?是否还有更紧凑更有效的网络框架?
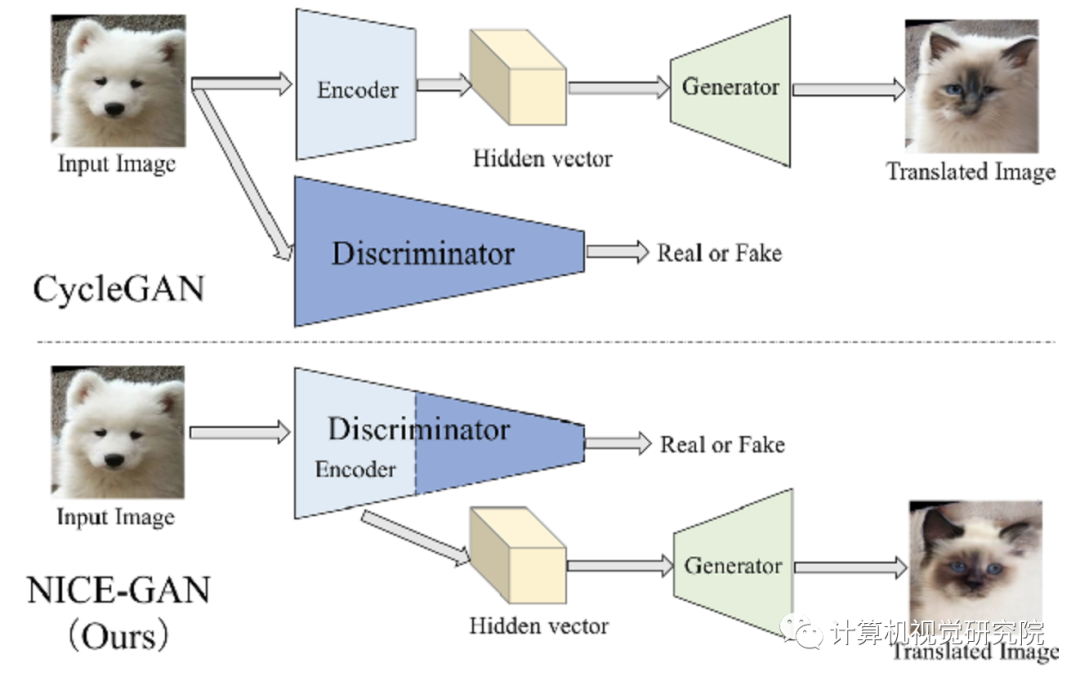
类似CycleGAN的框架与作者的NICE-GAN框架之间的主要差异
本次提出了一个新颖的思路。众所周知,在图像转换任务中,当网络训练完成后,当前的网络框架将丢弃判别器。而在论文提出的新框架中,判别器赋予了双重角色——编码和分类:通过复用目标域判别器的前几层网络来替代目标域图像的编码器。作者将这个新的体系结构称为NICE-GAN。实际上,判别器的编码潜力在DCGAN这篇文章中就已经被讨论。
与以前的方法相比,NICE-GAN具有两个优势:首先,由于不需要独立的编码组件,因此结构更紧凑,同时在训练完成后,其编码部分仍保留用于推断。其次,传统的编码器是通过生成器的梯度传播进行间接训练的。在这里,通过将其插入判别器中,可以直接利用判别损失(Discriminative Loss)进行训练,如果应用了多尺度判别器结构,则它将拥有更多的信息量和更高的训练效率。
四、解耦训练策略
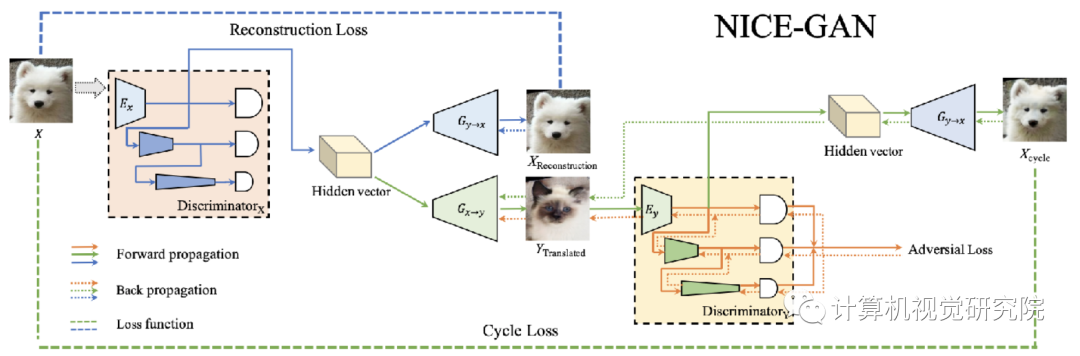
无监督图像到图像的转换是计算机视觉的核心问题。训练结束后,大多数当前的图像转换框架将丢弃判别器。本文通过重复使用判别器来对目标域的图像进行编码,提出NICE-GAN。与以前的方法相比,方法具有两个好处:首先,由于不需要独立的编码组件,因此结构更紧凑;其次,这种插入式编码器直接受对抗损失训练,如果应用了多尺度判别器,则其信息量更大,训练更有效。
第一个重用判别器来编码非监督图像到图像转换的人。通过这样的重用,可以派生出更紧凑、更有效的体系结构,称为非独立组件编码GAN (NICE-GAN)。
考虑到典型训练过程中判别器的重用会导致不稳定,本文开发了一种简单有效的解耦训练范式。
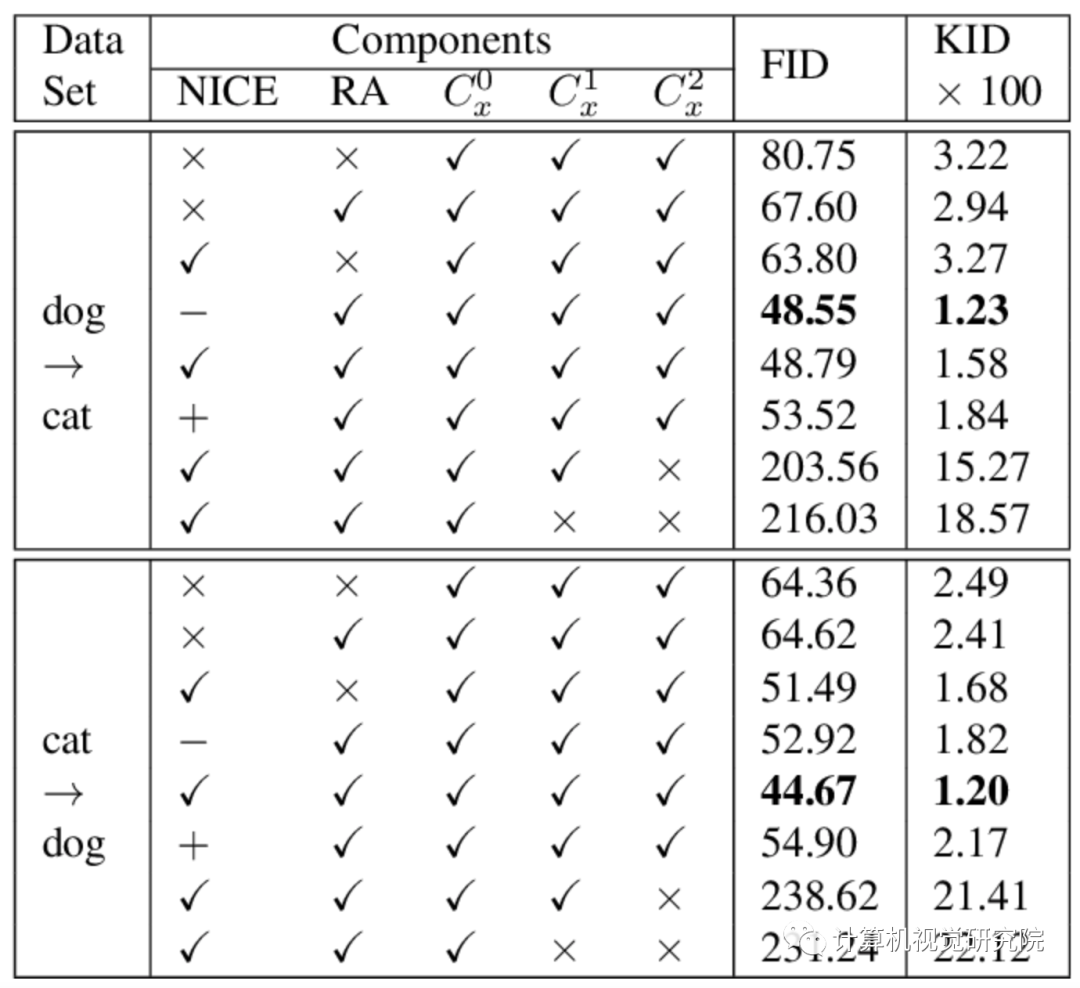
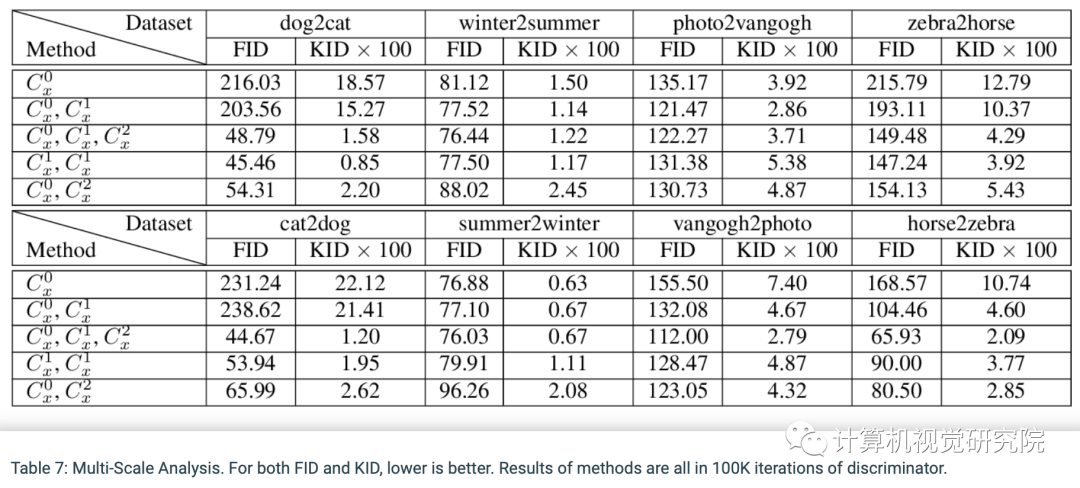
在几个流行的基准上进行的广泛实验评估显示,所提出的方法优于各种先进的对应方法。此外,还进行了全面研究,以验证各组件的有效性。
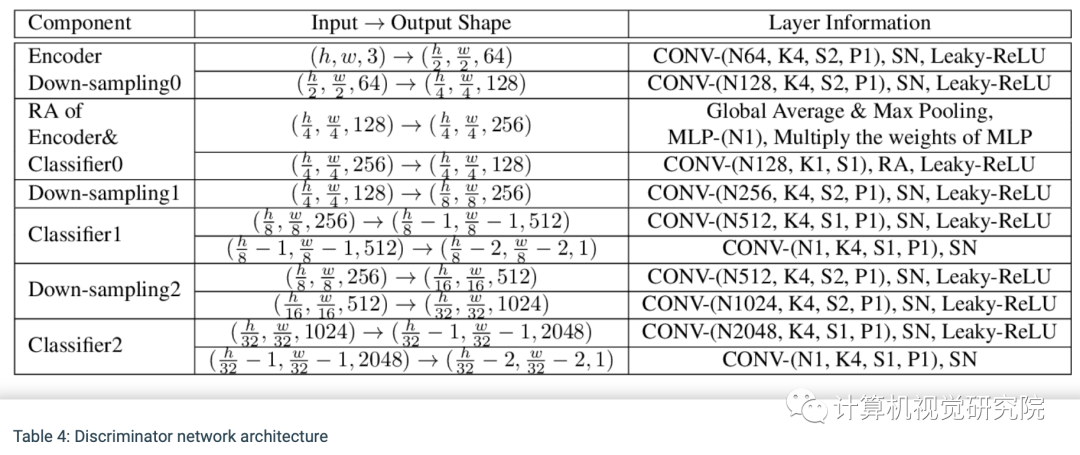
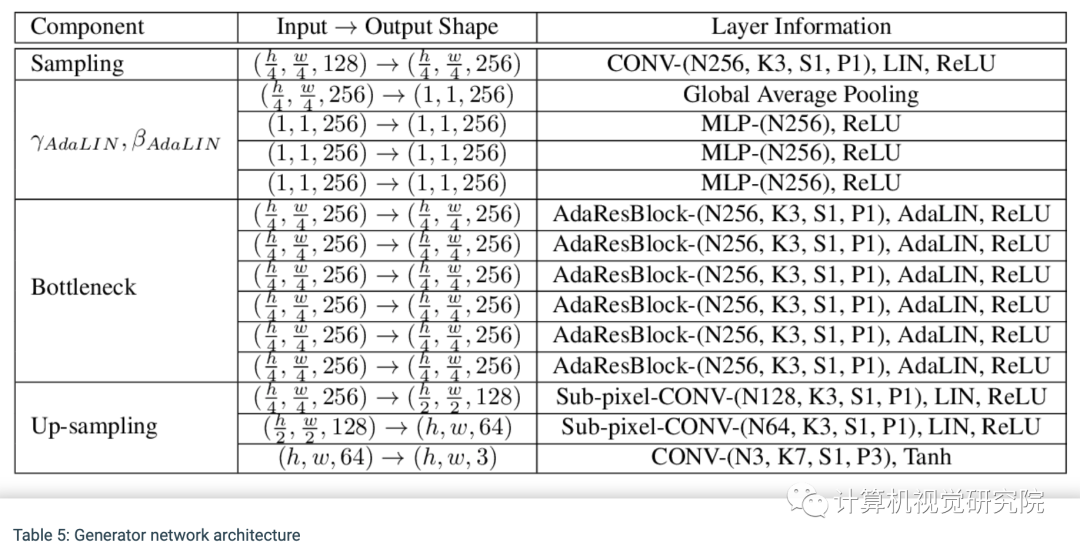
网络结构:NICE-GAN图形流程图的说明。在这里,我们只显示从X到Y(从狗到猫)的一个转换流。注意,我们应用了一种解耦的训练方式:当最小化对抗损失、重建损失和周期损失时编码器Ey是固定的,当最大化对抗损失时,它是训练的。
五、实验验证
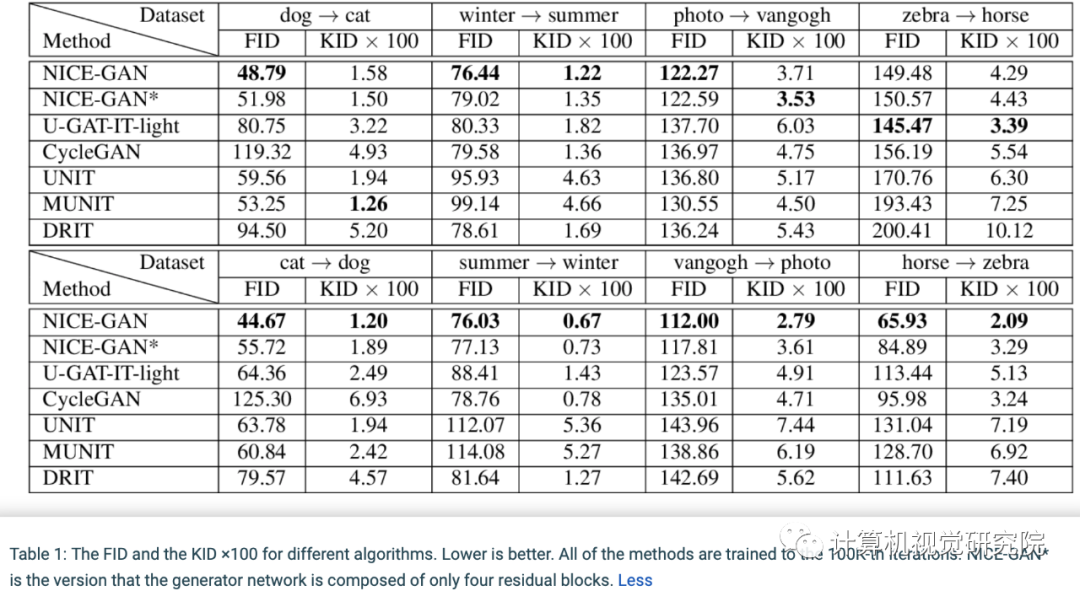
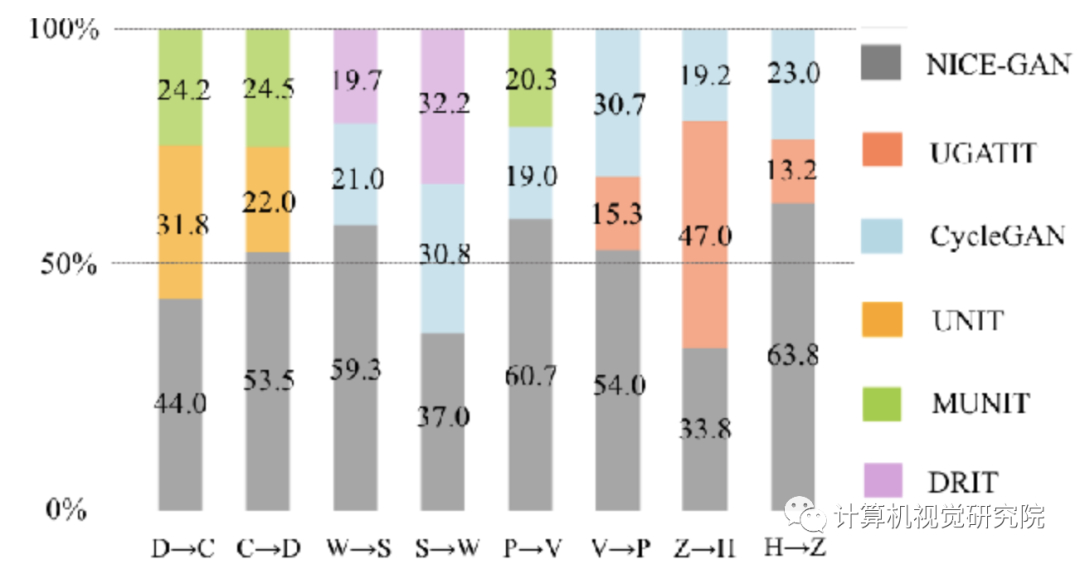
作者在四个流行的基准上进行的广泛实验证明,在FID,KID以及人类感知偏好等指标上,NICE-GAN的性能优于最新方法。此外,作者还进行了全面的消融研究,以验证每个组件的有效性。


转换效果图。从上到下依次为:狗<—>猫,冬天<—>夏天,普通照片<—>梵高作品,斑马<—>综马
在四个流行的基准上的FID和KID指标。NICE-GAN的性能优于最新方法
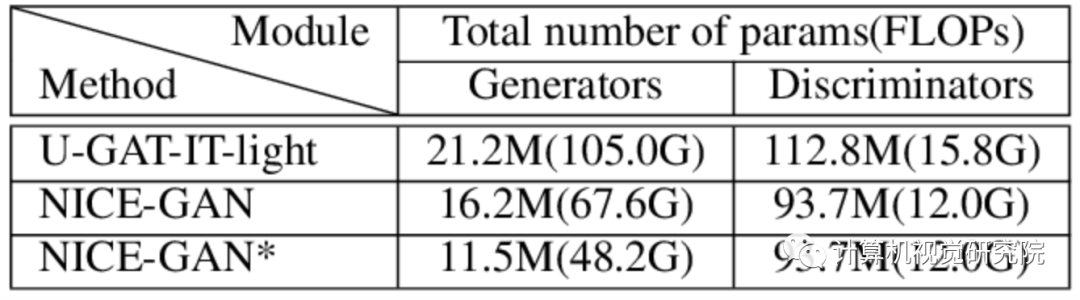
模型大小和浮点运算量。表明NICE-GAN体系结构更加紧凑,模型复杂度更低


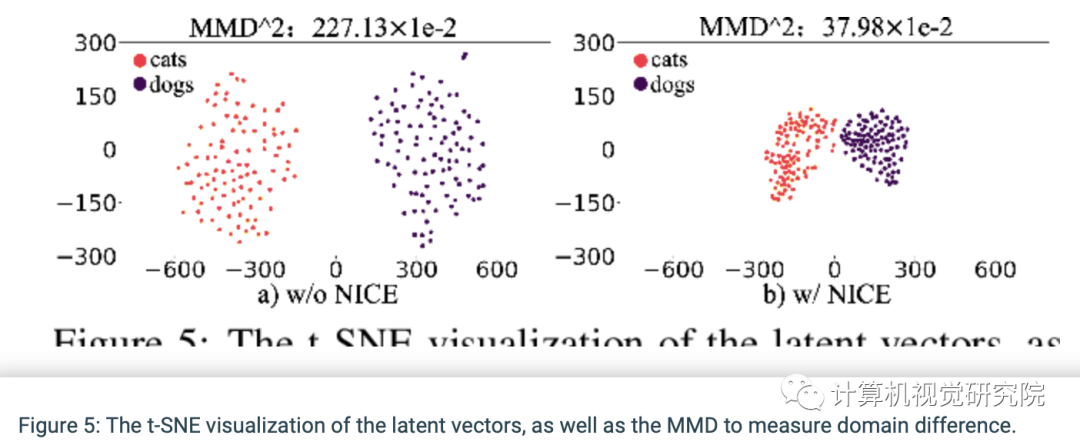
通过t-SNE可视化隐层编码,并利用Maximum Mean Discrepancy(MMD)以计算隐层空间两个编码分布的差异。有趣的是,通过NICE的训练,两个域的隐层空间分布变得更加聚集和紧密,但彼此依然可分。这种现象解释了为什么NICE-GAN表现出色。基于共享隐层空间假设构建的NICE-GAN,通过缩短低维隐层空间中域之间的转换路径,可能会促进高维图像空间的域的转换。同时进一步支持了一个重要观点:对比由通过最大似然训练的编码器网络学习的特征,由经过判别训练的网络学习到的特征往往更具表现力,也更适合推理。在NICE-GAN中,编码器也成为分布距离度量函数的一部分,而生成器只需要从隐层分布中提取循环一致性信息并拟合目标域分布。这种简单解耦的明确分工,有望引起人们对判别器实际作用的重新思考,它可能会刷新基于GAN的诸多任务的实现框架。
该论文得到了国家科技部科技创新2030“新一代人工智能”重大项目的资助支持。后续工作中,清华大学计算机系“类脑计算与认知团队”将会继续关注机器人感知中的表征学习的基础理论问题,致力于寻找更有效的算法,实现更好的机器人学习效果。
/End.

我们开创“计算机视觉协会”知识星球一年有余,也得到很多同学的认可,我们定时会推送实践型内容与大家分享,在星球里的同学可以随时提问,随时提需求,我们都会及时给予回复及给出对应的答复。

长按扫描维码
关注我们回复“NiceGAN” 获取论文





