ACL@2022 | 反向预测更好?基于反向提示的小样本槽位标注方法
论文名称:Inverse is Better! Fast and Accurate Prompt for Few-shot Slot Tagging 论文作者:侯宇泰,陈成,罗先镇,李博涵,车万翔 原创作者:陈成,侯宇泰 论文链接:https://arxiv.org/abs/2204.00885 代码链接:https://github.com/AtmaHou/PromptSlotTagging 转载须标注出处:哈工大SCIR
1. 简介
在本文中,我们探索了如何更好的将提示学习(Prompt)方法运用到小样本槽位标注任务上。基于Prompt的方法将目标任务转化为语言模型建模任务,减少了预训练任务和目标任务之间的差距,以更好地利用预训练语言模型 [1,2,3,4],并在句子级别的任务上取得了瞩目的成绩。而现有的基于Prompt方法的词级别任务,如槽位标注任务在时间上十分低效[5],如图1(a)所示,由于槽位标注任务需要识别是一个句子中的多个连续单词,基于Prompt的方法必须枚举句子中所有n-gram,以找到所有可能的槽位,这大大降低了预测速度。其次这种范式对标签逐个预测,并未考虑标签之间的依赖关系,如<出发地>经常和<到达地>成对出现。
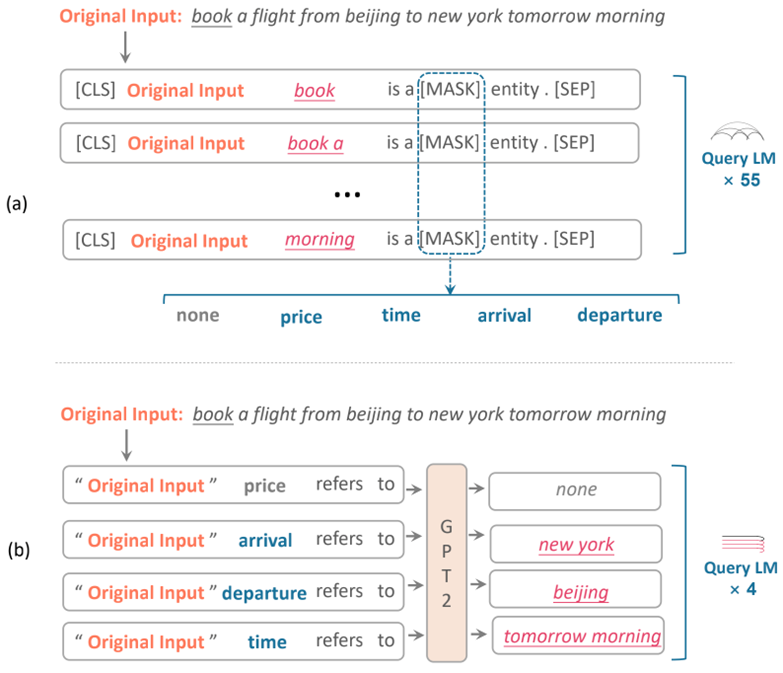
为了解决上述低效率和标签依赖关系的问题,我们提出了一种反向的Prompt范式。如图1(b),我们的范式在给定槽位标签类型的情况下,我们反向预测槽位值,而不是列举槽位值来预测标签。与要求对每个n-gram进行预测的正向Prompt方法(图1中为55次)相比,我们只需要对V次进行反编码,其中V是标签类型的数量(图1中为4次),因此大大加快了预测速度。实验表明,我们的方法不仅在速度上在显著优于最强baseline,而且在多个数据集上提升约6个点。
2. 方法
2.1 背景:小样本槽位标注
![]() 图2 传统的序列标记方法(a)和经典Prompt方法(b)
图2 传统的序列标记方法(a)和经典Prompt方法(b)

如图2,传统的小样本槽位标注通常被建模为为序列标注问题,即输入序列中的每个单词被预测为一个结构性标签;而从前的基于Prompt的小样本槽位标注方法对句中每个可能的槽位值通过填空模版来预测其标签。
2.2 用于小样本槽位标注的反向Prompt(Inverse Prompt for few-shot slot tagging)
动机: 减少对语言模型的查询次数来加速基于Prompt的小样本槽位标注
解决方案: 我们使用反向Prompt将小样本槽位标注任务转化成一个受控制的自然语言生成过程,由三部分组成:
标签映射:将标签转换成预训练模型便于理解的自然语言标签。例如from.Loc->departure
-
反向模版:将要进行槽位标注的原句子x,遍历标签集并经过标签映射得到的标签组合到一个句子中: ______,并期望模型可以自然地预测出x中标签为 的部分。
控制词:使用<;>来分隔一个句子中多个同类别槽位;<.>来标志生成过程的结束;<none>
表示没有对应槽位类型的槽位值。
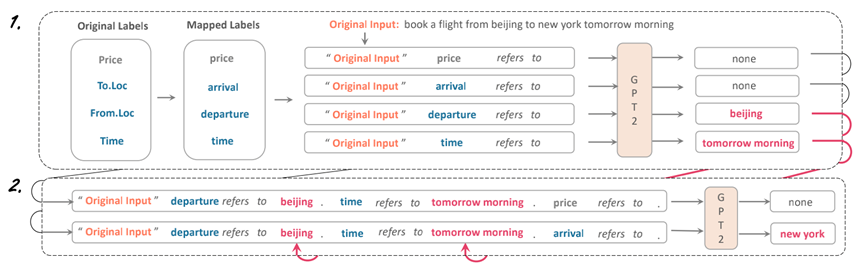
2.3 迭代预测策略(Iterative Prediction Strategy)
动机: 考虑标签之间的关联性
解决方案: 如图3所示,通过将第一轮预测的结果加入到第二轮的Prompt模版中来建模标签之间的依赖关系:例如,第一轮中预测出departure是beijing,time是tomorrow morning,未预测出price和arrival;则构造一个包含预测出的槽位对而对未预测出槽位进行预测的模版,例如:"book a flight from beijing to new york tomorrow morning" departure refers to beijing . time refers to tomorrow morning. price refers to none . arrival refers to __。期望模型考虑在已经出现departure的情况下的arrival。
3. 实验
本文在两种小样本设置下测试了我们的方法:
领域内小样本:只在该领域的小样本数据的支持集上finetune,并在查询集上测试。对于领域内小样本,本文使用MIT数据集(包括MIT-movie,MIT-restaurant,MIT-movie-hard)
有源域迁移的小样本:在源域数据上进行训练,再迁移到小样本领域。对于有源域迁移的小样本场景,本文采用SNIPS数据集。
表6 领域内小样本实验的结果
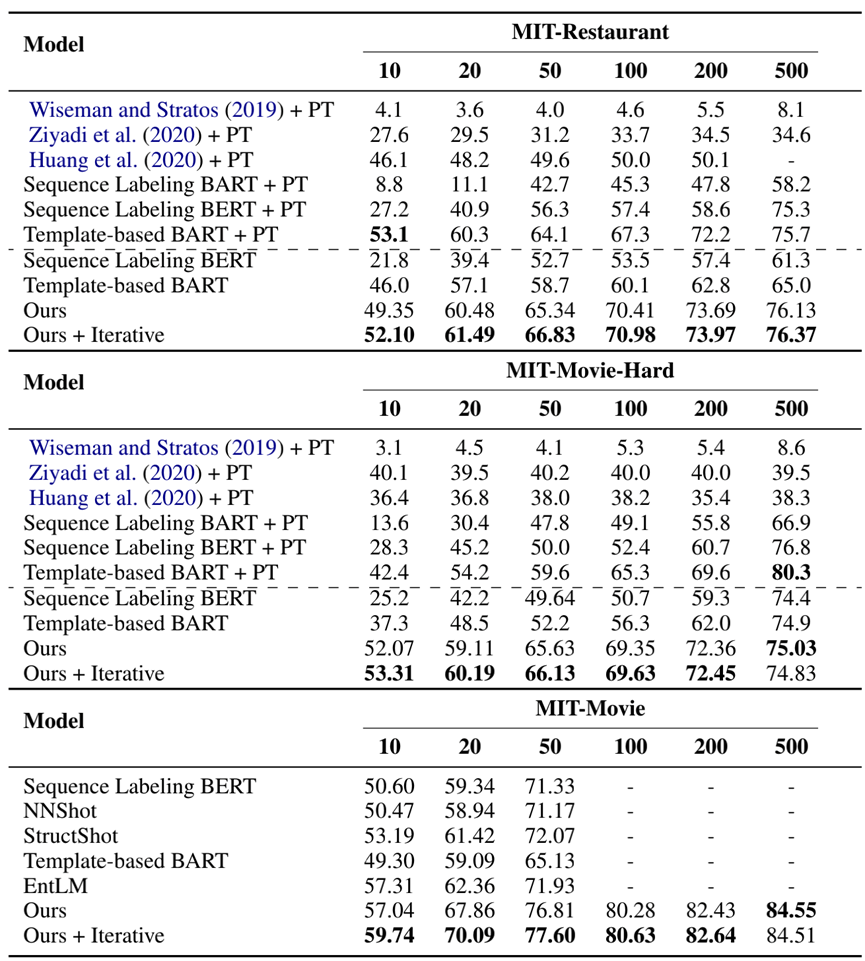
表7 有源域迁移的小样本结果
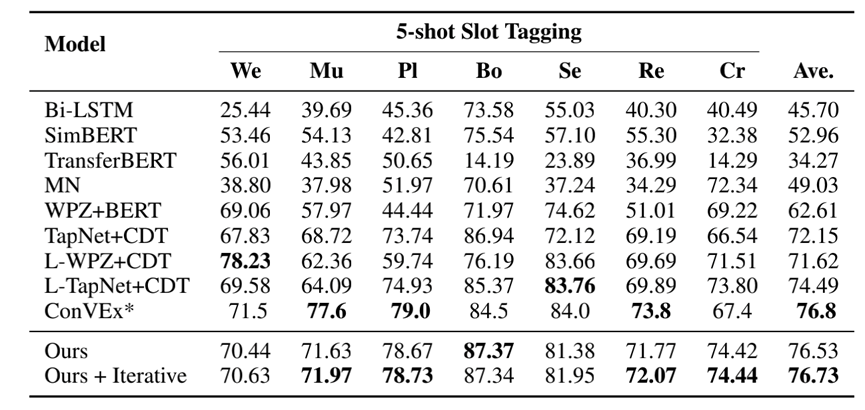
表8 速度实验
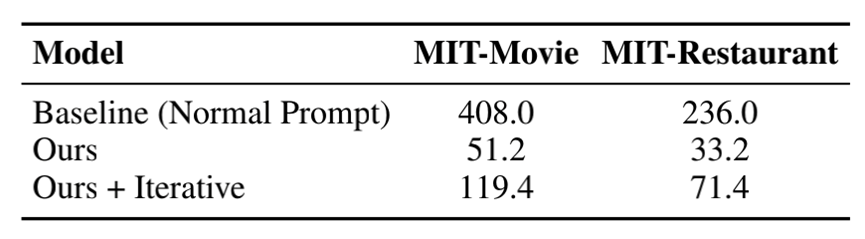
如图6、7、8所示,我们的模型大幅地提升了小样本槽位标注的精度和速度。
表9 对迭代预测策略的分析实验
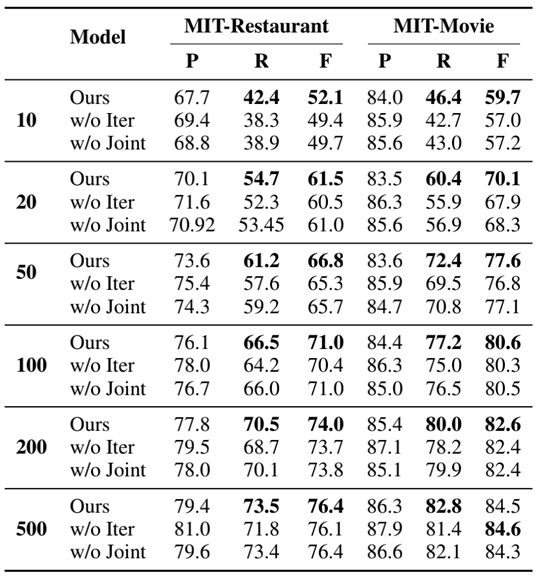
如图9,进一步的消融实验说明了迭代预测策略对性能的改进主要来源于增加召回率。
4. 总结
在本文中,为了加快基于Prompt的槽位标注任务,我们提出了一种新颖的用于槽位标注任务的反向Prompt方法,这显著提高了效率和准确性。为了进一步提高性能,我们提出了一种迭代预测策略,该策略构建使模型能够考虑标签之间的相关性的Prompt来优化预测结果。扩展实验验证了该方法在各种小样本设置中的有效性,表明反向预测更适合于基于Prompt的槽位标注任务。
5. 参考文献
[1] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapolis, Minnesota. Association for Computational Linguis tics.
[2] Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692.
[3] Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Zettlemoyer. 2020. BART: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. In Proc. of the ACL, pages 7871–7880.
[4] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language models are few-shot learners. In Advances in Neural Information Processing Systems, volume 33, pages 1877–1901. Curran Associates, Inc.
[5] Leyang Cui, Yu Wu, Jian Liu, Sen Yang, and Yue Zhang. 2021. Template-based named entity recognition using BART. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 1835–1845, Online. Association for Computational Linguistics.
本期责任编辑:丁 效
理解语言,认知社会
以中文技术,助民族复兴



