深度学习碰上古文献,西南大学提出基于CNN的古彝文识别方法
机器之心发布
作者:西南大学计算机与信息科学学院 陈善雄
在论文《A Recognition Method of Ancient Yi Character Based on Deep Learning》中,西南大学计算机与信息科学学院陈善雄副教授联合贵州工程应用技术学院彝学研究院的专家,提出了使用深度学习技术识别古彝文的方法。
摘要:作为世界六大古文字之一的古彝文记录下几千年来人类发展历史。针对古彝文的识别能够将这些珍贵文献材料转换为电子文档,便于保存和传播。由于历史发展,区域限制等多方面原因,针对古彝文识别的研究鲜有成果。本文把当前新颖的深度学习技术,应用到古老的文字识别中去。在四层卷积神经网络(Convolutional Neural Network, CNN)的基础上扩展出 5 个模型,然后再利用 Alpha-Beta 散度作为惩罚项对 5 个模型的输出神经元重新进行自编码,接着用两个全连接层完成特征压缩,最后在 softmax 层对古彝文字符特征进行重新评分,得到其概率分布,选择对应的最高概率作为识别的字符。实验表明本文所提方法相对于传统 CNN 模型而言对古彝文手写体的识别具有较高的精度。
1 引言
古彝文作为一种重要的少数民族文字,距今有八千多年历史,可与甲骨、苏美尔、埃及、玛雅、哈拉般 5 种文字并列,是世界六大古文字之一,一直沿用至今,并在历史上留下了许多珍贵的典籍,这些用古彝文书写的典籍具有重要的历史意义和社会价值 [1, 2]。而作为彝文古籍的载体,石刻、崖画、木牍和纸书由于年代久远,往往模糊不清,或者残缺不全,这给古彝文的识别带来了极大的挑战。

图 1:从左至右分别为石刻、木犊、羊皮书写的古彝文。
当前,在古彝文识别方面成果相对较少,主要是国内民族类高校和研究所开展了部分研究。云南民族大学王嘉梅等人曾使用图像分割的方法进行彝文识别,首先在预处理过程中对彝文字符进行细化、归一化、二值化等处理,之后使用模板匹配法进行彝文识别 [3]。朱龙华等人使用组合特征分类的方法进行彝文识别,他们使用的特征有:方向线素特征、笔画密度特征和投影特征,在分类过程中,使用多个分类器投票的方式来确定最终的类别,最终获得了接近 96%的识别率,是典型的特征提取外加分类的方法 [4]。朱宗晓、吴显礼在印刷体规范彝文识别中首先提取周边方向贡献度的特征,并将特征压缩为 128 维,之后使用基于单一特征的三级距离字典匹配算法进行识别,最终在包含 10 种彝文文字的测试集中达到了 99.21%的一次识别率 [5]。在彝文识别研究中,值得一提的是 2017 年 3 月西南民族大学沙马拉毅教授与中央民族语文翻译局共同研制出了彝文手写体识别技术,并开发出相关彝文识别软件,有力地推动彝族文字和文化的保护和发展。
相对于其他文字识别而言,古彝文的书写随意性较大,没有统一的规范,其识别复杂性也随之增加。虽然现有的中英文识别技术获得的较大的发展,但由于历史、区域发展的不平衡,古彝文识别当前研究甚少。而现存的古彝文基本都为手写体,手写体的多样性无疑加大了识别的难度 [3, 6, 7]。因此,古彝文识别是一个极具挑战性的模式识别问题,其主要表现在:
缺乏成熟的手写样本库。手写样本库是古彝文识别成功的关键因素,直接决定着识别的效果。当前的古彝文研究仍然主要集中在对古彝文文献的整理,没有人专门对古彝文识别进行研究,找不到可用的古彝文手写样本库。
字符集庞大。古彝文拥有庞大的字符集,2004 年出版的《滇川黔桂彝文字集》就包含着 87000 多个字 [8]。对如此庞大的字符集进行分类是一个比较困难的任务。
古彝文字体字形变化较多,且没有统一标准,不同地区书写规则不同,体例和格式变化较多,增加了识别难度。
本文采用深度学习中的卷积神经网络对古彝文字符进行识别。在四层卷积神经网络基础上扩展出 5 个模型,然后再利用 Alpha-Beta 散度作为惩罚项对 5 个模型的输出神经元重新进行自编码,接着用两个全连接层完成特征压缩,最后用 softmax 层对古彝文字符进行重新评分,得到其概率分布,选择对应概率最高者作为识别的字符。
2 基础网络结构
本文构造一个四层卷积神经网络用于古彝文字符识别 [9-11],称为模型 M0,如图 2 所示。M0 由 4 个卷积层、2 个全连接层、1 个 softmax 层构成。其符号化描述为如下:
Conv:卷积层 (Convolutional layer)
MP:最大池化层(Max Pooling layer)
Drop:随机失活层(Dropout layer)
Softmax:Softmax 层
FC :全连接层 (Fully Connected layer)
例如,Conv(3x3, 64, S2, P1) 其表示大小为 3×3,输出通道数位 64,步长为 2,填充为 1,的卷积层。默认情况下 Conv 的步长为 1,填充为 1,这里主要是为了使得卷积前后特征图大小相等。而 MP 的在默认情况下大小 2×2,步长为 1,填充为 0,此时特征图大小变为前一层的 1/4。
对于模型 M0 而言,符号化描述为:
Input(64x64x1) – Conv(3x3, 100) - MP – Conv(3x3, 200) – MP - Conv(3x3, 300) – MP - Conv(3x3, 400) – MP – FC(2048) – Drop(0.5) – FC(1024) – Softmax(2162)

图 2:模型 M0
本文以模型 M0 为基础,分别在其各卷积层的前方再额外添加一个 3×3 的卷积层,得到了 4 个模型:M1,M2,M3,M4。所有模型的符号化描述如表 1 所示。M1 在第一个卷积层前添加了一个通道数为 50 的卷积层;M2 在第二个卷积层前添加了一个通道数为 150 的卷积层;M3 在第三个卷积层前添加了一个通道数为 250 的卷积层;M4 在第四个卷积层前添加了一个通道数为 350 的卷积层;而 M5 则将 M1-M4 所有的操作都应用到模型 M0 上,并同时在所有卷积层的前方添加一个 3×3 的卷积层,得到模型 M5,如图 2 所示。
表 1:M0-M5 模型的符号化描述。
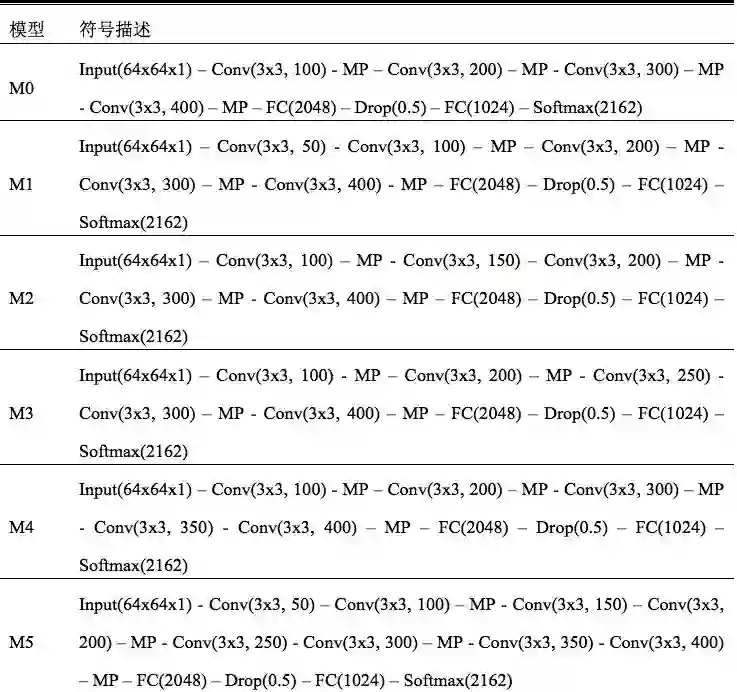
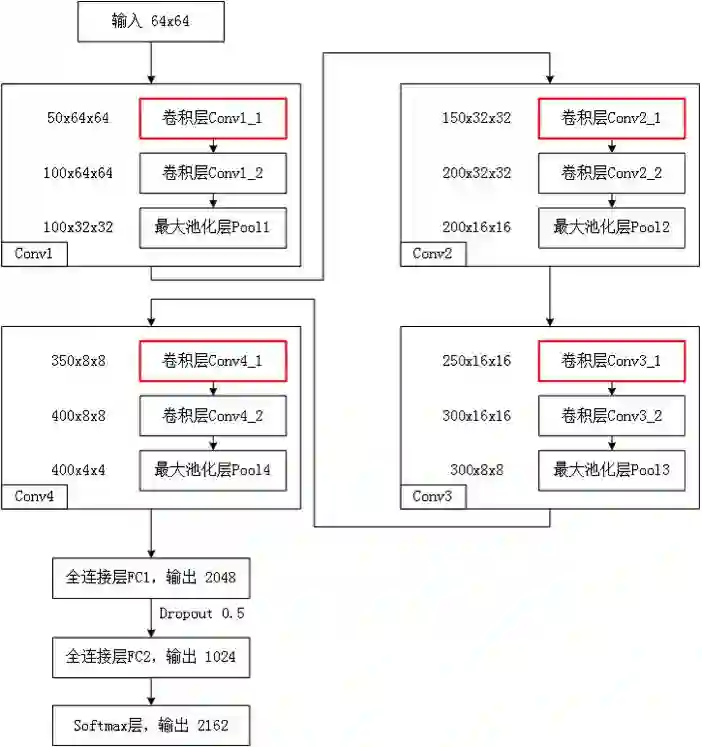
图 3:模型 M5:红色为额外添加的卷积层。
模型 M5 结构如图 3 所示,网络由 4 个大卷积层、2 个全连接层、1 个 softmax 层构成,并对除 softmax 的其他层的输出使用 ReLU 函数进行激活。其中每个大卷积层由两个连续的 3×3 卷积层以及一个 2×2 最大池化层构成,卷积核的输出通道数以 50 为基数进行递增。为了进一步规范模型描述,我们对 M5 模型包含的四个卷积层进行形式化描述如下:
层次 1: 模型描述
Conv1: Conv1_1(参数量 4K),Conv1_2(参数量 405K),Pool1
通道数: 50,100,100
输出尺寸:32×32
总量: 100
对于第一个卷积层 Conv1,其由卷积层 Conv1_1,Conv1_2,池化层 Pool1 构成,其通道数分别为 50,100,100,该层的输出为 100 张大小为 32×32 的特征图,卷积层 Conv1_1,Conv1_2 的参数数目分别为 4k,405k,整个卷积层 Conv1 的参数数目为 409k。
层次 2 模型描述
Conv2: Conv2_1(参数量 1215K),Conv2_2(参数量 2430K),Pool2
通道数: 150,200,200
输出尺寸:16×16
总量: 200
层次 3 模型描述
Conv3: Conv3_1(参数量 4050K),Conv3_2(参数量 6075K),Pool3
通道数: 250,300,300
输出尺寸:8×8
总量: 300
层次 4 模型描述
Conv4: Conv4_1(参数量 8505K),Conv4_2(参数量 11340K),Pool4
通道数: 350,400,400
输出尺寸:4×4
总量: 400
而对于全连接层与 softmax 层而言,其参数分别为 13107k,2097k,2214k。其中第一个全连接层的随机失活概率为 0.5。整个网络的参数共计约 51442k。
3 Alpha-Beta 散度的自编码结构
单个 CNN 模型的表达能力往往是有限的,不同的模型对于同一个问题的解决能力也不尽相同,有着自己特有的偏好,既要考虑不同模型对于局部类别识别的可信度,又要考虑模型对于整体的分类效果 [12, 13]。本文构建出一种泛化的散度,用 Alpha-Beta 散度作为惩罚项对模型 M0-M5 的输出神经元重新进行自编码 [14, 15],之后利用两个全连接层进行特征压缩,最后使用一个 Softmax 层对古彝文字符进行重新评分 [16],得到其概率分布。
假设对于 P 和 Q 是同一个空间中的两个概率密度函数,它们之间的 Alpha-Beta 散度可以表示如下 [15]:
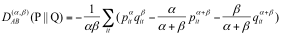
其中 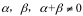
上式满足如下约束条件
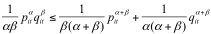
其中
为了能够避免在某一值下存在不确定性和奇异性,Alpha-Beta 散度被扩展到覆盖所有的实数集,因此 Alpha-Beta 能更直接地表示为:
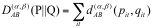
其中
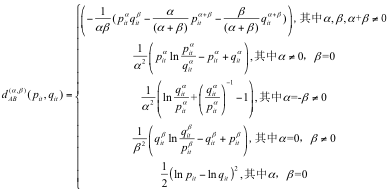
本文对 M0-M5 输出神经元采用 Alpha-Beta 散度作为惩罚项重新进行自编码的学习(如图 4 所示),再通过两次全连接进行特征抽取,目的在于把 M0-M5 模型进行全局优化,提升对古彝文识别的精度。
根据自编码神经网络原理 [17, 18],学习一个函数,使得
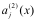
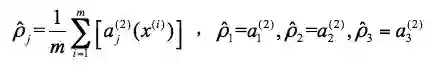
一般强制约束为
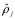
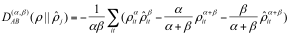
因此,全局损失函数为:
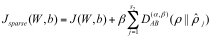
其中,
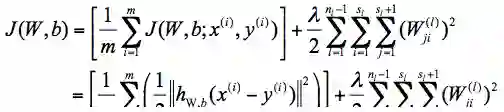
这里,
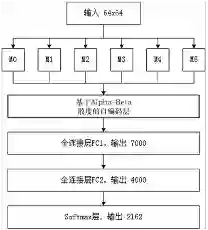
图 4:基于 Alpha-Beta 散度自编码融合模型 M6。
4 模型训练及样本采集
(1)模型训练
本文将模型的激活函数设置为 ReLU[19],优化算法选择 Adam[20, 21],同时对训练集进行了增量,扩大训练集容量,使模型能够更加充分地学习到图像中的特征。此外为了使模型能够顺利的收敛,这里为每一个卷积层都附加了一个 Batch Norm 层。
虽然 Adam 算法计算高效,方便实现,内存占用少;更新步长和梯度大小无关初始学习率。但在增量后的数据集上其优化效果不明显。当学习率为 0.001 时,损失函数基本无法收敛,而将学习率设置为 0.0001 时,损失函数开始下降,如图 5 所示,因此本文将初始学习率设置为 0.0001。
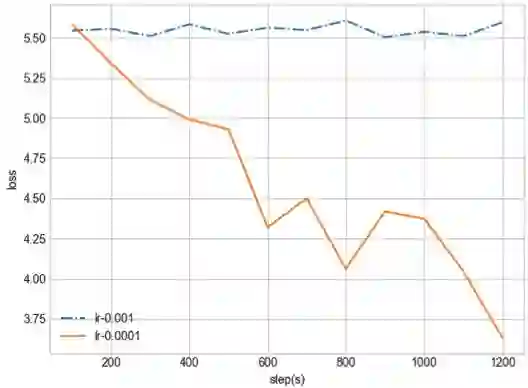
图 5:模型 M0 不同学习率下的损失函数。
(2)样本采集
样本来源于 37 万字的《西南彝志》中选取的 2142 个常用古彝文字符 [22],并邀请彝族老师和学生进行临摹,发放了 1200 份采集表(如图 6 所示),其中彝文正体采集表 800 份、软笔风格采集表 200 份、硬笔风格采集表 200 份,如图 7 所示,共得到了 151200 个字体样本。同时,考虑便于后期处理分析,设计了相应的字体库(如图 8 所示)和古彝文输入法。

图 6:采集表扫描样本。

图 7:古彝文硬笔(上)软笔(下)。

图 8:古彝文字体库。
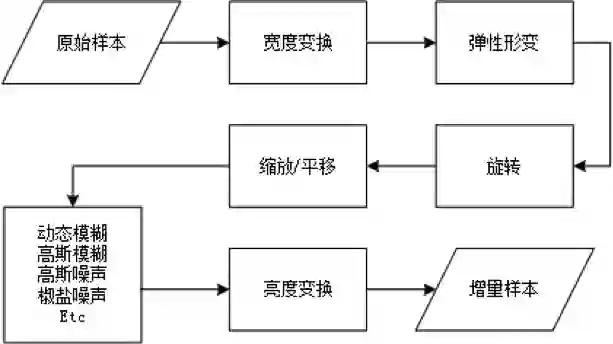
图 9:样本增量。
为了确保模型能够学习到足够多的特征,这里对样本进行增量处理。样本增量流程如图 9 所示,首先对原始样本进行宽度变化和弹性形变,然后进行旋转、缩放、平移的仿射变换,接下来是模糊加噪,最后则是亮度及对比度变换。增量后的样本示例如图 10 所示。

图 10:增量后的样本。
经过以上处理我们得到了训练集 A,为了更真实地验证本文所提方法的效果,我们从贵州彝学研究院提供的出版物「彝学经书」之「布斗布周数」影印文件中选取了 20 份文件,每份约 150 个字符,作为测试数据。此外本文运用增量技术对训练集 A 进行了样本增量得到了训练集 A2。
实验及分析
本文使用训练集 A2,对 M0-M5 进行了训练,并在测试集 B 上进行了测试。其结果如表 2 所示,模型在测试集 B 上的准确率远高于训练集 A2 的准确率,这表明本文使用的模型通过增量后的训练集学习到了足够多的手写风格,同时表明本文所提出的增量方法是可行且有效的。但在另一方面,在经过了足够多的训练次数后,训练集的准确率仍然没有超过 90%,这表明本文所使用的训练数据集可能存在某些难以识别的样本。对训练数据集进行人工排查后,发现由于原始样本的分辨率过低,在增量变形的过程中,部分样本出现了笔迹丢失,粘连以及过度模糊的情况。如图 11 所示,对于同一个字符,由于过度变形,其几乎完全偏离了这个字的正常书写风格。正是这些过度变形后的样本为模型带入了额外的噪声,使得模型在训练集上表现不佳。
表 2:模型 M0-M5 准确率。


图 11:过度变形后的数据。
由表 2 可知,模型 M1 的性能最优,其在测试集 B 上的准确率达到了 92.84%,最差的则为 M5,仅有 90.06%。相对于最简单的模型 M0,在其各层分别添加额外的卷积层,显然有利于模型性能的提升,但随着模型插入位置的向后迁移,其提升幅度逐渐下降。而模型 M5 在每个卷积层前都添加了额外的卷积层,期望达到更好的效果,现实情况却是整个模型性能明显下降。
此外,表 4 展示了不同模型迭代 100 次所消耗的时间,毫无疑问,最简单的模型 M0 所消耗的时间是最少的,仅为 237.27s。而模型 M5 所消耗时间高达 563.40s。同时随着插入卷积层位置的增高,参数也随之增多,相应需要的时间也开始急剧增加。但在 M3 和 M4 与 M2 相比,却出现了时间减少的情况,这主要是由于随着层数的增加,特征图尺寸缩小,其计算量也随之变小。如表 3 所示,与模型 M0 相比,模型 M2 增加的连接数量最多达到了 2.07e9,而模型 M3 与 M4 的增加的连接数量却开始降低,其中模型 M4 增加的连接数量最小仅为 0.65e9。
表 3:模型 M1-M4 与 M0 相比增加的连接数量。

从表 2 和表 4 中可以看出 M1 综合性能最佳,其在仅带入了极少计算量的同时,最大限度提高了模型性能。而 M5 显然是最得不偿失的选择,占用了几乎两倍于 M0 的计算时间,性能不升反降。
表 4:模型 M0-M5 迭代 100 次所消耗的时间(秒)。

通过进一步分析发现,在卷积层后再次进行卷积运算确实有助于模型性能的提升,但底层的效果远远好于高层,同时其在底层进行添加后的代价也是最小的(参数量偏小)。而高层添加卷积层往往效果不是特别明显,但又带来的庞大的计算量(引入了大量的参数)。而模型 M5 在各个层都直接添加卷积的做法,显然在带入大量计算量的同时,也引起了梯度弥散。
为了综合各个模型优势,实验采用了图 3 的模型 M6,以模型 M0-M5 的输出概率分布作为输入,在训练集 A2 上进行训练,并在测试集 B 上进行了测试。其在测试集 B 上的准确率达到了 93.97%,在训练集 A2 上的准确率也达到了 90.63%。

图 12:模型 M0-M6 在测试集 B 上的准确率变化。
进一步实验分析了模型准确率变化情况,图 12 所示为模型 M0-M6 在测试集上随着迭代次数增加的准确率变化(多次实验发现模型迭代次数在 100 到 150 之间准确率趋于稳定,再增加迭代次数准确率没有明显变化)。从图中可以明显的看出模型 M5 明显劣于其他几个模型,其上升最慢,在第 12 个周期才达到最佳准确率 91.06%。模型 M0,M1 在第 8 个周期达到最佳准确率,91.54%、92.84%,而模型 M6 则在第 7 个周期便达到了最佳准确率 92.97%。同时可以看到模型 M0、M1、M2、M6 上升速度较为接近,同时模型 M6 在第 7 个周期开始达到相对平稳的状态,相比于其他模型更早达到平稳状态。总体而言,模型 M6 优于其他模型,这正是 M6 对其他几个模型的输出神经元进行重新编码优化的结果。
结论
本文对古彝文数据集利用深度学习的 CNN 网络进行识别,具有较高的识别精度。特别是采用了 Alpha-Beta 散度作为惩罚项对各个模型的输出神经元重新进行自编码生成的融合的方案,在带入有限计算量的情况下提升整个识别网络的性能,同时能够避免网络层数增加带来的性能下降问题。当前,彝文的识别尚处于起步阶段,其主要针对书写规范的手写体和印刷体进行文本提取,且由于字符库有限,仅限于对常见的彝文进行处理。而针对彝文古籍中古彝文识别的相关研究就非常稀少,可以说这是当前国内外研究的空白。本文把深度学习技术结合到少数民族古文字处理,也对文化保护和发展做出一些有益的探索。另外,考虑到本文对各个模型输出进行重新自编码的融合方案采用了概率分布的方式进行度量,需要大量的样本,而通过彝族同胞手写样本的代价较大,后续拟采用深度学习的生成对抗网络(GANs)生成更多的古彝文手写体样本。

参考文献
[1] 朱崇先, "彝文古籍整理与研究",民族出版社, 2008.
[2] 高娟,刘家真, "中国大陆地区古籍数字化问题及对策",中国图书馆 学报, vol. 2013, pp. 110-119, 2013.
[3] 王嘉梅, 文永华, 李燕青, 高雅莉, "基于图像分割的古彝文字识别系统研究",云南民族大学学报:自然科学版,, vol. 17, pp. 76-79, 2018.
[4] 朱龙华,王嘉梅, "基于组合特征的多分类器集成的脱机手写体彝文字识别",云南民族大学学报:自然科学版, vol. 19, pp. 329-333, 2010.
[5] 朱宗晓,吴显礼, "脱机印刷体彝族文字识别系统的原理与实现",计算机技术与发展, vol. 22, pp. 85-88, 2012.
[6] 刘赛,李益东, "彝文文字识别中的文字切分算法设计与实现",中南民族大学学报 (自然科学版), vol. 26, pp. 74-76, 2007.
[7] 吴兵, "基于文字识别角度的规范彝文字分析研究",西南民族大学学报 (人文社科版), pp. 47-53, 2018.
[8] 滇川黔桂彝文协作组, "滇川今注彝文字集",云南民族出版社, 2004.
[9] X. H. Ren, Y. Zhou, J. H. He, K. Chen, X. K. Yang, J. Sun, "A Convolutional Neural Network-Based Chinese Text Detection Algorithm via Text Structure Modeling," Ieee Transactions on Multimedia, vol. 19, pp. 506-518, Mar 2017.
[10] M. A. H. Akhand, M. Ahmed, M. M. H. Rahman, aM. M. Islam, "Convolutional Neural Network Training incorporating Rotation-Based Generated Patterns and Handwritten Numeral Recognition of Major Indian Scripts," Iete Journal of Research, vol. 64, pp. 176-194, 2018.
[11] A. Nasee,K. Zafar, "Comparative Analysis of Raw Images and Meta Feature based Urdu OCR using CNN and LSTM," International Journal of Advanced Computer Science and Applications, vol. 9, pp. 419-424, Jan 2018.
[12] V. A. Sindagi,V. M. Patel, "A survey of recent advances in CNN-based single image crowd counting and density estimation," Pattern Recognition Letters, vol. 107, pp. 3-16, May 1 2018.
[13] X. M. Deng, Y. D. Zhang, S. Yang, P. Tan, L. Chang, Y. Yuan, and H. A. Wang, "Joint Hand Detection and Rotation Estimation Using CNN," Ieee Transactions on Image Processing, vol. 27, pp. 1888-1900, Apr 2018.
[14] C. A,A. S, " Families of Alpha- Beta- and Gamma- Divergences: Flexible and Robust Measures of Similarities," Entropy, vol. 12, pp. 1532-1568, 2010.
[15] C. A, C. S, and A. S, "Generalized Alpha-Beta Divergences and Their Application to Robust Nonnegative Matrix Factorization," Entropy, vol. 13, pp. 134-170, 2011.
[16] W. W. Shi, Y. H. Gong, X. Y. Tao, N. N. Zheng, "Training DCNN by Combining Max-Margin, Max-Correlation Objectives, and Correntropy Loss for Multilabel Image Classification," Ieee Transactions on Neural Networks and Learning Systems, vol. 29, pp. 2896-2908, Jul 2018.
[17] A. Sengupta, Y. Shim, K. Roy, "Proposal for an All-Spin Artificial Neural Network: Emulating Neural and Synaptic Functionalities Through Domain Wall Motion in Ferromagnets," Ieee Transactions on Biomedical Circuits and Systems, vol. 10, pp. 1152-1160, Dec 2016.
[18] P. Knag, J. K. Kim, T. Chen, Z. Y. Zhang, "A Sparse Coding Neural Network ASIC With On-Chip Learning for Feature Extraction and Encoding," Ieee Journal of Solid-State Circuits, vol. 50, pp. 1070-1079, Apr 2015.
[19] S. Qian, H. Liu, C. Liu, S. Wu, H. S. Wong, "Adaptive activation functions in convolutional neural networks," Neurocomputing, vol. 272, pp. 204-212, Jan 10 2018.
[20] A. Arcos-Garcia, J. A. Alvarez-Garcia, and L. M. Soria-Morillo, "Deep neural network for traffic sign recognition systems: An analysis of spatial transformers and stochastic optimisation methods," Neural Networks, vol. 99, pp. 158-165, Mar 2018.
[21] K. Gopalakrishnan, S. K. Khaitan, A. Choudhary, and A. Agrawal, "Deep Convolutional Neural Networks with transfer learning for computer vision-based data-driven pavement distress detection," Construction and Building Materials, vol. 157, pp. 322-330, Dec 30 2017.
[22] 贵州省彝学研究会, "西南彝志," 贵州民族出版社, 2015.
本文为机器之心发布,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com


