亲兄弟明算账:快速了解阿里的M2GRL模型
读论文有如吃包子
在开始正文之前,我想把我的“论文包子论”公之于众。我始终认为学术论文就是当代的八股文,中外皆如是。古代的八股文需要“起承转合”,现在的学术论文也要遵循“Introduction - Related Work - Real Content - Experiment - Conclusion”这基本的几步。而我们读论文时,就有如吃包子:
-
吃包子的第一口,吃的是皮。就好比读论文时,先读到的是Introduction和Related Work。看完项目背景和简介,开始对下面的“干货”充满期待。 -
吃包子的第二口,能吃到馅儿了。就好比读论文时,读到了文章核心干货部分,了解作者是如何解决问题的。馅儿吃完了,对包子的评价也就基本形成了。 -
吃包子的第三口,又是皮。就好比读论文时,读到Experiments部分。也是重要的部分,但是也就看一看就行了,不用太放心上。 毕竟所有实验结论永远都是“远超前人的工作,远超对照组”。即便所有的论文中的实验结论都不掺水,大家也要记住一句古语“ 橘生淮南则为橘,生于淮北则为枳”,论文中标榜的“疗效”未必能够在你们的环境中复现。
我吃到过好包子,比如《Ad Click Prediction: a View from the Trenches》、《Wide & Deep Learning for Recommender Systems》、《Deep Neural Networks for YouTube Recommendations》、......,都是皮薄馅大,干货满满,让人回味无穷。初读之后,过上一段时间,等自己的功力上升了,重新再读一遍,又会有新的收获。反到是现在,可能是我见识得多了,口味变刁了,吃到的好包子是越来越少了。想起一个笑话,说某食堂买的的包子,”吃第一口没吃到馅,第二口还没有,等到第三口终于咬到肉了,咬到了自己的手指头“。
至于今天的主角,阿里这篇被KDD 2020收录的M2GRL,味道如何,客官请往下看。
M2GRL的馅在哪里?
常规作法
先描述一个我们经常使用的召回方法:
-
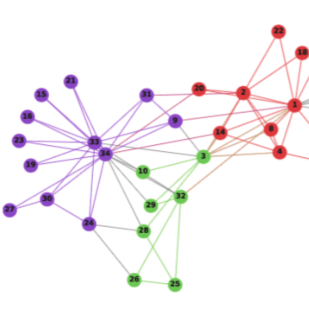
我们可以将用户点击序列中的item构建成图(用户在一个session内先点击A再点击B,则AB之间就有了边) -
在这个图上进行DeepWalk,就能够得到item embedding。 -
拿用户点击过的item,在所有候选item embedding进行近邻搜索,就能够得到与用户点击过的item相似的item,作为召回结果返回
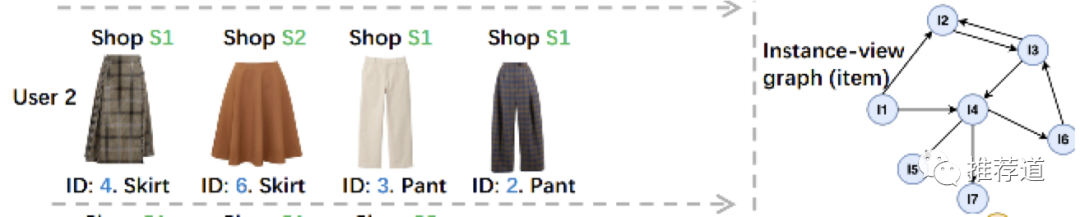
类似的方法不仅仅可用于学习item emberdding,还可以扩展到其他领域:
-
将用户访问过的shop构建成图,在这个shop图上进行DeepWalk,得到shop embedding。拿用户访问过的shop,通过近邻搜索得到相似shop,将这些相似shop中的卖的好的item,作为召回结果返回

-
将用户访问过的item的category构建成图 ,在这个category图上进行DeepWalk,得到category embedding。拿用户点击的item的category,通过近邻搜索得到相似的category,将这些相似category下卖的好的item,作为召回结果返回

这就是我们日常再普通不过的召回方式。M2GRL也是基于这种思路,那它的创新点在哪里?
M2GRL的馅
M2GRL说以上的学习方式,只是在item, shop, category三个view中独立学习(“亲兄弟明算账”),即所谓的intra-view task learning,每个view都遵循标准的word2vec训练
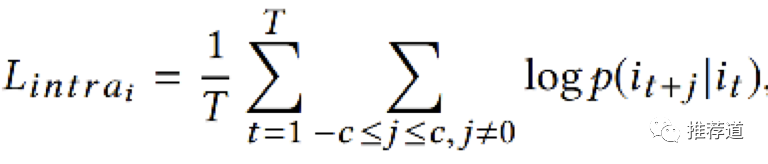
M2GRL又说,只有三个独立的intra-view task learning还不够,还需要加入item-shop, item-category两个cross-view task learning。这个cross-view task学习什么?论文里的符号也没有交待清楚。根据我的理解,比如某个item "i"是属于category “c”,那么item i's embedding " "映射到category embedding空间后,就要与自己所携带的category "c"的embedding “ ”非常近。(但是论文中的 是怎么回事?如果说 是将item embedding映射到category embedding,那 为什么也要映射?如果说是将 映射到第三空间,那为什么作者觉得item embedding与category embedding可以共享一个映射矩阵 ?)
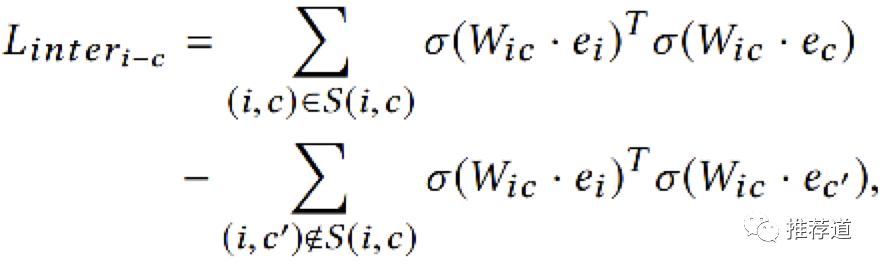
目前,这里有item/shop/category三个intrra-view task,还有item-shop、item-category两个cross-view task,多个目标一同优化,属于multi-task learning。M2GRL还使用了一种fancy的方法来自动确定多个task的权重。公式有点复杂,感觉也不是多重要的问题,就没有仔细看。
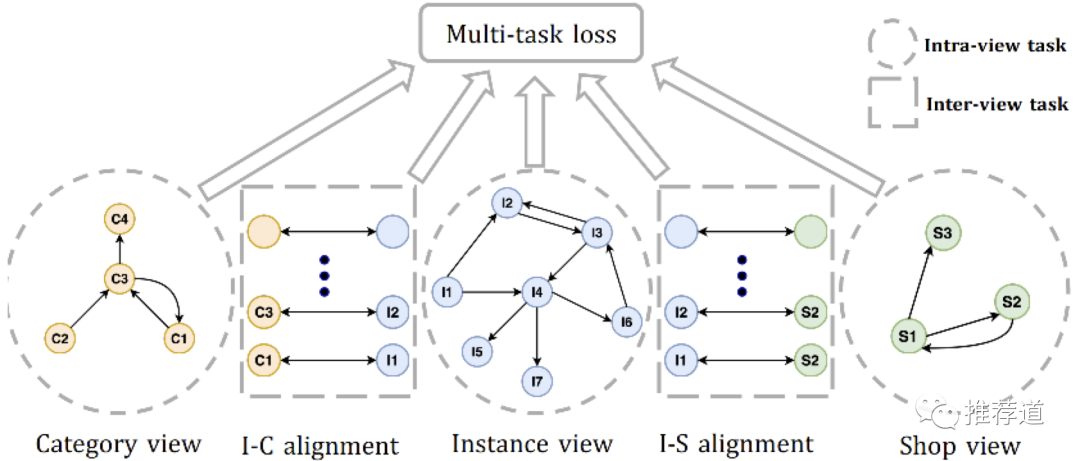
That's it? 基本上是吧,M2GRL的“馅”都在这里了,再咬就咬到手指头了。
怎么评价M2GRL?我丝毫不怀疑 M2GRL给作者的项目带来了实实在在的收益,但是它的馅太小,不对我的口味。
本文的馅在哪里?
M2GRL的馅不对我口味,那么在这个所谓“multi-view多信息融合"的场景下,你能做出什么好吃的包子来吗?嗯,文章的最后,提出一些建设性的意见。
文中的场景被称为multi-view,即item/shop/category是三个view。换一套语境,同样的场景可以被称为异构图(item/shop/category是三类异构节点)或知识图谱(item/shop/category是三类entity)。拿“异构图”或“知识图谱”来搜索,其实业内有很多工作聚焦于"多域信息融合"的问题。
常规的intra-view task learning
如果你的项目草创,需要尽快上线一个召回算法。只有intra-view task learning的方案,即通过DeepWalk学习到item/shop/category embedding,再将与用户历史相似的item、相似shop下的item、相似category下的item,作为召回结果返回,其实就已经很不错了,足以满足你项目初期的需求。各个view各做各的,也没有multi-task learning的麻烦。
阿里的EGES
如果你的项目已经稳定上线一段时间,目前需要进一步优化,那么尝试一下阿里在论文《Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba》得到的EGES,或许能有效果。
与M2GRL标榜的multi-view representation alignment不同,EGES属于multi-view representation fusion。在fusion做法中,我们只关心如何学习到高质量的item embedding,shop/category不再作为独立的view,而是作为item的属性。EGES实际上是word2vec的升级
-
传统word2vec中,只拿item id映射成item embedding,参与word2vec计算 -
EGES中, 拿item embedding + item所属shop的shop embedding + item所属category的category embedding,三者pooling成一个新的item embedding,参与word2vec计算
好处是,学习到的item embedding既利用了用户作为序列的信息,又利用了item本身属性(shop & category)的信息,信息含量更大。而且,对于新item,即使其缺乏用户行为信息,但是自身属性信息还在,就能够生成embedding,非常有助于新item冷启。
腾讯的GraphTR
文中M2GRL诟病EGES这类fusion方法,就是将多个异构信息pooling成一个向量,会带来信息损失。如果要弥补这一损失,可以看看腾讯的GraphTR模型。GraphTR面向的问题中,包含user, item, tag, media四类异构节点,与本文item, shop, category的场景非常类似。GraphTR采用了GraphSAGE+FM+Transformer三种聚合方式:
-
GraphSAGE,不区分各个view,将所有view向量拼接成一个向量,参与信息传递与融合。 粒度最粗。 -
FM,不同view之间的embedding要两两交叉。 粒度稍细。 -
Transformer,不仅考虑了不同view之间的交叉,还考虑了一个view内部多个特征之间的交叉。 粒度最细。
GraphTR采取三种方式,粒度从粗到细,完成信息融合,避免了传统multi-view representation fusion中由于pooling成单一向量而带来的信息损失。缺点就是复杂太过复杂了。对这个模型感兴趣的同学请出门左转,参考我之前的文章《GraphSAGE+FM+Transformer强强联手:评微信的GraphTR模型》。
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏