周志华教授:开放环境机器学习
近期,南京大学周志华教授在《国家科学评论》(National Science Review, NSR)发表题为“Open-environment Machine Learning”的文章,对开放环境机器学习(简称Open ML)的研究内容进行了界定,并对相关进展进行了回顾总结。

传统的机器学习研究通常假设在封闭的环境中,学习过程的重要因素保持不变。随着机器学习的巨大成功,如今越来越多的实际任务,尤其是那些涉及到开放环境场景的任务,其中重要因素会发生变化,本文称之为开放环境机器学习。显然,机器学习从封闭环境向开放环境的转变是一个巨大的挑战。更具有挑战性的是,在各种大数据任务中,数据通常是随着时间的积累而积累的,就像流一样,而很难像传统研究那样收集完所有的数据后训练机器学习模型。本文简要介绍了这一研究方向的一些进展,重点介绍了新类别、增量特征、变化的数据分布和不同的学习目标等方面的技术,并讨论了一些理论问题。
机器学习在各种应用中取得了巨大的成功,特别是在监督学习任务,如分类和回归。通常,在机器学习中,优化特定目标的预测模型是从由训练示例组成的训练数据集学习的,每个示例对应一个事件/对象。一个训练示例由两部分组成:描述事件/对象外观的特征向量(或称为实例),以及表示相应地面真实输出的标签。分类时,标签表示训练实例所属的类;在回归中,标签是对应于实例的实值响应。这篇文章主要关注分类,尽管大多数讨论也适用于回归和其他机器学习任务。形式上,考虑从训练数据集D = {(X 1, y1),…, (x m, ym)},其中x i∈x是特征空间x中的特征向量,yi∈Y是给定标签集Y中的真值标签。
值得注意的是,目前机器学习的成功案例大多涉及假设接近封闭环境场景的任务,其中学习过程的重要因素保持不变。例如,所有要预测的类标签都是预先知道的,描述训练/测试数据的特征永远不会改变,所有数据都来自一个相同的分布,学习过程朝着一个不变的唯一目标优化。图1说明了在封闭环境机器学习研究中假设的典型不变因素。封闭环境假设提供了一种简化的抽象,使复杂的任务能够以更容易的方式处理,导致机器学习技术的繁荣发展。随着这些技术取得的巨大成就,如今,越来越多的超越封闭环境设置的具有挑战性的任务出现在社区中,要求新一代的机器学习技术能够处理学习过程中重要因素的变化。我们称之为开放环境机器学习,简称开放学习或开放ML。请注意,“开放世界机器学习”这个名字是用来指带有不可见类[1]或超出分布(OOD)数据[2]的机器学习。事实上,如果看不见的类是事先知道的,它并不超出封闭环境研究,如果看不见的类是未知的,它与“新兴的新类”一节有关。OOD与“变化的数据分布”一节有关,尽管只关注不同的分布比随时间变化的分布更简单。
似乎有一个直接的解决方案:通过提前模拟可能的变化来人为地生成许多训练样本,然后将这些数据输入强大的机器学习模型(如深度神经网络)。然而,这样的解决方案只适用于当用户知道或者至少可以估计什么变化以及变化将如何发生时。不幸的是,在大多数实际任务中并非如此。当我们考虑到真正的大数据任务中的数据通常是随着时间累积的,例如实例是一个接一个接收的,就像一个流一样,这就变得更加具有挑战性。我们不可能像传统研究那样在获得所有数据后训练机器学习模型;更合理的方法是根据新接收到的数据对训练好的模型进行细化/更新。不幸的是,众所周知,如果只使用新数据对训练好的深度神经网络进行精化,则可能会发生灾难性遗忘[3],而基于存储所有接收到的数据的频繁重新训练可能会导致难以承受的巨大计算和存储成本。虽然有像[4]这样的研究试图帮助深度神经网络抵抗遗忘,但通常需要对大量训练数据进行多次扫描和离线训练,对大流数据有严重的计算和存储问题。尽管面临巨大的挑战,但最近在开放机器学习方面进行了大量的研究工作。本文简要介绍了这一研究方向的一些进展,重点关注有关新兴类别、递减/增量特征、变化的数据分布和不同的学习目标的技术。本文还将讨论一些理论问题。
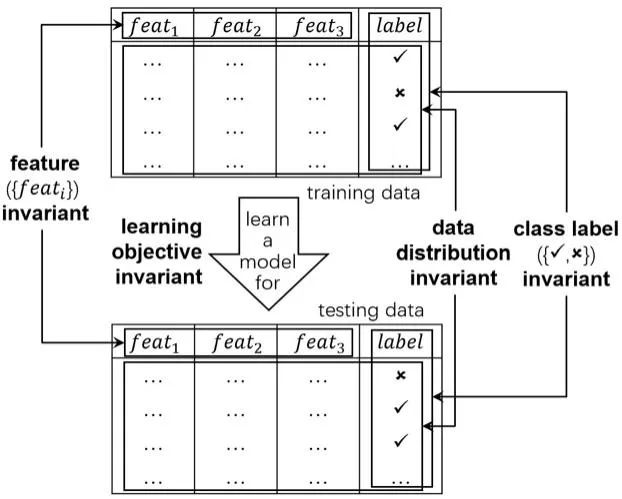
封闭环境机器学习中的典型变量
以森林病虫害预测任务为例:
1. 标记集合发生变化。随着时间推移,可能会有新的病虫类型出现。针对该类问题,典型应对思路包括:先通过异常检测技术对潜在新类别进行识别,再进一步精化将其加入标记集合进行增量学习。
2. 特征空间发生变化。森林部署的数据监测传感器由于寿命有限,研究人员需要在其失效前加装新的传感器以保证有效的监测,这将导致特征空间发生变化。针对该类问题,典型应对思路包括:利用新旧特征共存时的数据学习特征之间映射关系,从而使旧模型在新空间也能发挥作用。
3. 数据分布发生变化。夏季绿叶茂盛,而冬季叶萎雪积,直接利用旧分布上训练出的模型可能无法在新任务上取得良好性能。针对该类问题,典型应对思路包括:利用滑窗或遗忘法降低历史数据在学习目标中的权重,构建多个分类器并采用集成学习等手段缓解分布变化带来的影响。
4. 学习目标发生变化。随着收集数据的增多以及模型准确率的提高,学习目标可能由追求更高的准确率变更为追求更低的耗电量。针对该类问题,典型应对思路包括:考察不同学习目标之间的相关性,将旧模型输出作为基础,复用相应模型以优化新的学习目标,实现学习目标的快速切换。
文章还对建立开放环境机器学习理论进行了探讨并给出了初步框架。
作者认为,亟需研究能够适应开放环境的机器学习理论与方法,这将为提升和保障人工智能系统的稳健性提供关键技术支撑。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“OEML” 就可以获取《周志华教授:开放环境机器学习》专知下载链接





