CVPR 2022|39亿参数模型公开可用,采样速度7倍提升,残差量化生成图片开源

极市导读
基于残差量化的自回归图像生成,官方已将代码公开。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
向量量化(Vector quantization,VQ)已经成为自回归(AR)模型生成高分辨率图像的一种基本技术,具体来说,该技术将图像特征图通过 VQ 量化后,再进行光栅扫描等排序,之后将图像表示为离散编码序列。量化后,训练的 AR 模型对序列中的编码进行序列预测。也就是说,AR 模型可以生成高分辨率的图像,而无需预测图像中的全部像素。
我们假设减少编码的序列长度对于图像的 AR 建模很重要。短编码序列可以显着降低 AR 模型的计算成本,因为 AR 通常使用先前位置的编码来预测下一个编码。然而,以前的研究由于图像的序列长度问题在速率 - 失真(rate-distortion)不能很好的权衡。也就是说,VQ-VAE 需要呈指数增长的编码簿 (Codebook)大小来降低量化特征图的分辨率,同时保持重建图像的质量。然而,巨大的编码簿会导致模型参数增加和编码簿崩溃,使得 VQ-VAE 的训练不稳定。
来自 Kakao Brain 、韩国浦项科技大学的研究者提出了一种残差量化 VAE (RQ-VAE)方法,它使用残差量化 (RQ) 来精确逼近特征图并降低其空间分辨率。RQ 没有增加编码簿大小,而是使用固定大小的编码簿以从粗到细的方式递归量化特征图。在 RQ 的 D 次迭代之后,特征图表示为 D 个离散编码的堆叠图。由于 RQ 可以组成与编码簿大小一样多的向量,因此 RQ-VAE 可以精确地逼近特征图,同时保留编码图像的信息,而无需庞大的编码簿。由于精确的近似,RQ-VAE 可以比以前的研究 [14,37,45] 进一步降低量化特征图的空间分辨率。例如, RQ-VAE 可以使用 8×8 分辨率的特征图对 256×256 图像进行 AR 建模。该论文已被 CVPR'22 接收。

论文地址:https://arxiv.org/pdf/2203.01941.pdf
此外,该研究还提出了 RQ-Transformer 来预测 RQ-VAE 提取的编码。对于 RQ-Transformer 的输入,该研究首先将 RQ-VAE 中的量化特征映射转换为特征向量序列;然后,RQ-Transformer 预测下一个 D 编码,以估计下一个位置的特征向量。由于 RQ-VAE 降低了特征图的分辨率,RQ-Transformer 可以显着降低计算成本并轻松学习输入的远程交互。该研究还为 RQ-Transformer 提出了两种训练技术,软标签(soft labeling)和用于 RQ-VAE 编码的随机采样。通过解决 AR 模型训练中的曝光偏差(exposure bias)进一步提高了 RQ-Transformer 的性能。
值得一提的是,该研究近日发布了在 30M 文本图像对上训练的 3.9B 参数的 RQ-Transformer 。据了解,这是公共可用模型中最大的文本到图像 (T2I) 模型。不过这一结果没有出现在该论文中。具体内容可参考 GitHub。

代码地址:https://github.com/kakaobrain/rq-vae-transformer
如下图所示,该模型可以生成高质量的图像。

3.9B 参数的 RQ-Transformer 生成结果,画框里带着眼镜的猫:

生成沙漠上的埃菲尔铁塔:

方法概述
研究者提出了用于图像 AR 建模的 RQ-VAE 和 RQ-Transformer 两阶段框架,如下图 2 所示。RQ-VAE 使用编码簿将图像表示为 D 个离散码的堆叠图。然后,使用 RQ-Transformer 自回归预测下一个空间位置的下一个 D 码。他们还解释了使用 RQ-Transformer 解决 AR 模型训练中的曝光偏差问题。
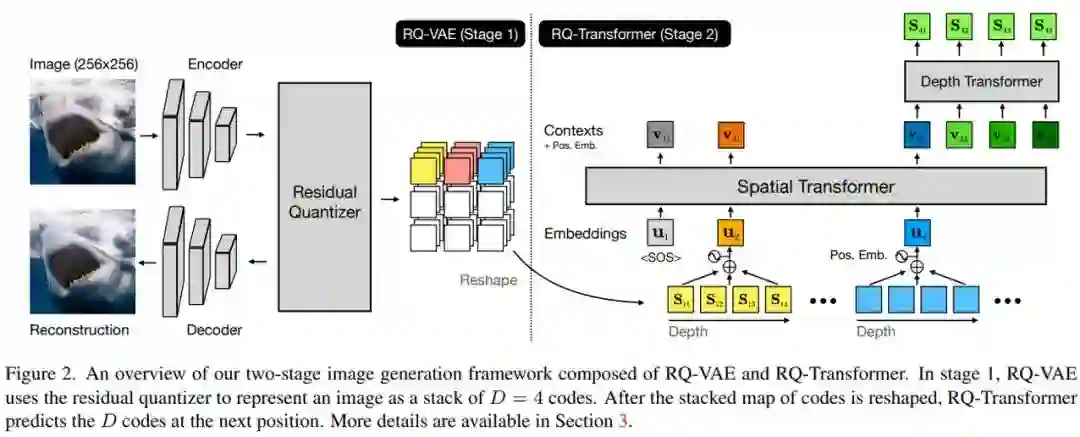
阶段 1:残差量化 VAE
研究者首先介绍 VQ 和 VQVAE 的表达方式,然后提出了 RQ-VAE,它可以在不增加编码簿大小的情况下精确地逼近特征图。他们解释了如何将图像表示为离散码的堆叠图。
和 -VAE 的表达。令编码簿C为一个有限集 , 它包含了成对的代码 和代码嵌 , 其中K是编码簿大小, 是代码嵌入的维数。
考虑到一个向量 表示 的 , 这个代码的嵌入离 最近, 如下公式 (1) 所 示。
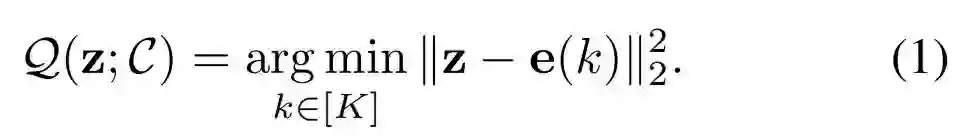
在将图像编码为离散码图后,VQ-VAE 从编码码图重建原始图像。
对于残差量化,研究者没有增加编码簿大小,而是采用残差量化(RQ)来离散化向量 z。给定一个量化深度 D,RQ 将 z 表示为一个有序的 D 码,如下公式(3)所示。
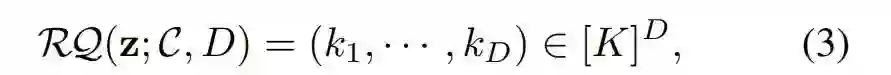
RQ-VAE。在上图 2 中,研究者提出 RQ-VAE 来精确量化图像的特征图。RQ-VAE 也是由 VQ-VAE 的编解码器架构组成,不过 VQ 模块被上面的 RQ 模块所取代。
具体而言,深度为 D 的 RQ-VAE 将特征图 Z 表示为代码 M ϵ [K]^H×W×D 的堆叠图,并提取了 ,成为 d ϵ [D]的深度为 D 的量化特征图,得到如下公式(5)。
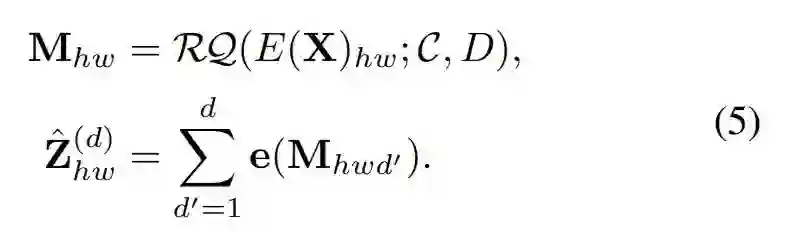
RQ-VAE 使 AR 模型以低计算成本有效地生成高分辨率图像。对于固定的下采样因子 f,RQ-VAE 可以产生比 VQ-VAE 更逼真的重建结果,这是因为 RQ-VAE 使用给定的编码簿大小精确地逼近特征图。
阶段 2:RQ-Transformer
研究者展示了 RQ-Transformer 如何自回归地预测 RQ-VAE 的代码堆栈。在对 RQVAE 提取的代码的进行 AR 建模之后,他们介绍 RQ-Transformer 如何有效地学习离散代码的堆叠图。此外,研究者还解释了 RQ-Transformer 的训练技术,以防止 AR 模型训练中出现曝光偏差。
深度为 D 的代码的 AR 建模。在 RQ-VAE 提取代码映射 M ϵ ^[K] H×W×D 后,光栅扫描顺序(raster scan order)将 M 的空间索引重新排列为代码 S ϵ [ K]^T ×D 的二维数组,其中 T = HW。也就是说,S_t 是 S 的第 t 行,并包含了 D 个代码,如下公式(8)所示。
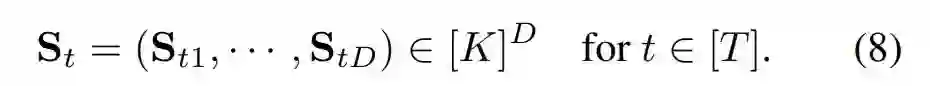
如上图 2 所示,RQ-Transformer 由空间 transformer 和深度 transformer 组成。空间 transformer 是带掩码自注意力块的堆叠,用于提取一个总结先前位置信息的上下文向量。给定上下文向量 h_t,深度 transformer 自回归预测位置 t 处的 D 个代码 (S_t1,····,S_tD)。
软标签和随机抽样。研究者提议对来自 RQ-VAE 的代码进行软标签和随机采样,以解决暴露偏差。
实验结果
无条件图像生成
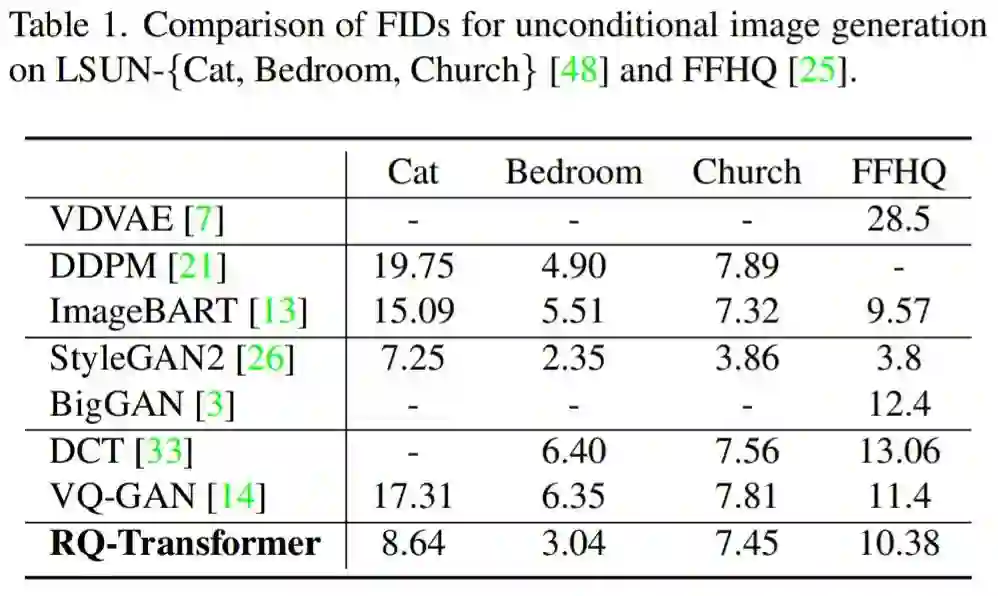
该研究在 LSUN-{cat, bedroom, church}和 FFHQ 数据集上评估了无条件图像生成的质量。表 1 显示,RQ-Transformer 模型在无条件生成图像方面优于其他 AR 模型。对于小规模数据集,如 LSUN-church 和 FFHQ,RQ-Transformer 小幅度优于 DCT 和 VQ-GAN。对于更大规模的数据集,如 LSUN-{cat, bedroom},RQ-Transformer 明显优于其他 AR 模型和基于扩散的模型。
该研究推测性能的提高来自于 RQ-VAE 较短的序列长度,因为 SQ-Transformer 可以很容易地在较短的序列长度内学习编码间的长程交互。图 3 前两行展示了 RQ-Transformer 可以无条件生成高质量图像。

有条件图像生成
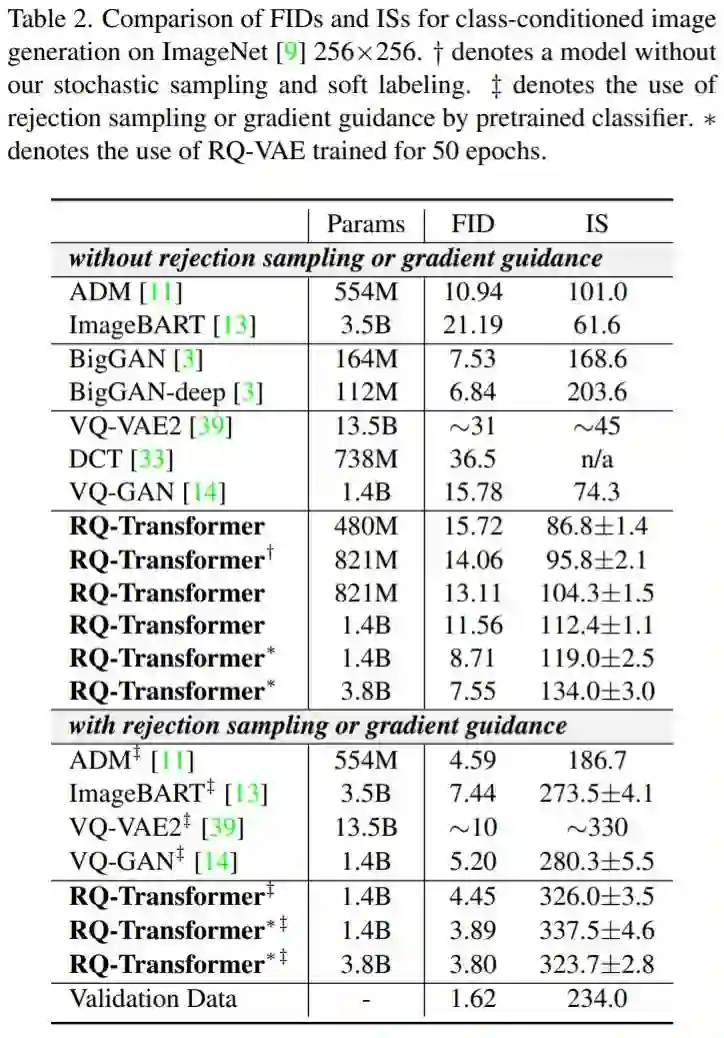
该研究分别使用 ImageNet 和 CC-3M 进行类和文本条件的图像生成。如表 2 所示,RQ-Transformer 在 ImageNet 上的性能明显优于以前的模型。RQ-Transformer(480M 参数)与以往 AR 模型具有竞争力,包括 VQ-VAE2, DCT,和 VQ-GAN,虽然 RQ-Transformer 比 VQ-GAN 少 3 倍的参数。此外,具有 821M 参数的 RQ-Transformer 在没有拒绝采样的情况下优于以往的 AR 模型。
具有 1.4B 参数的 RQ-Transformer 在没有拒绝采样的情况下达到 11.56 的 FID 分数。当将 RQ-VAE 的训练 epoch 从 10 增加到 50 时,1.4B 参数的 RQ-Transformer 进一步提高了性能,达到了 8.71 FID 分数 。此外,当研究者进一步将参数数量增加到 3.8B 时,RQ-Transformer 在没有拒绝采样的情况下达到了 7.55 的 FID 分数,并且可以与 BigGAN 竞争。
RQ-Transformer 还可以根据 CC-3M 的各种文本条件生成高质量图像。RQ-Transformer 在参数数量相似的情况下明显高于 VQ-GAN 的性能。图 3 显示在 CC-3M 上训练的 RQ-Transformer 可以使用各种文本条件生成高质量的图像。
RQ-Transformer 的计算效率
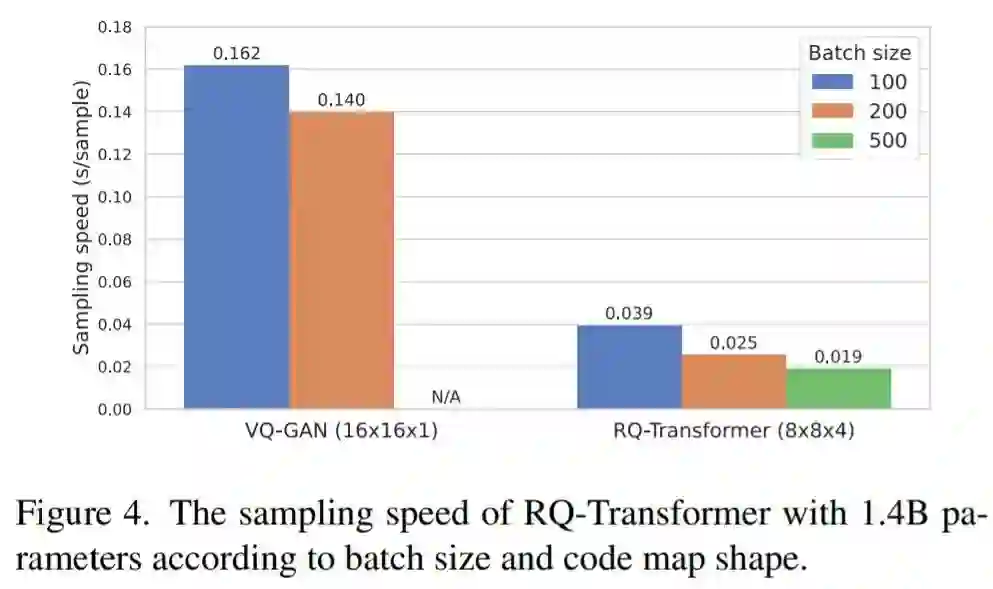
图 4 评估了 RQ-Transformer 的采样速度,并与 VQ-GAN 进行了比较,两种模型参数均为 1.4B。VQ-GAN 和 RQ-Transformer 的输入分别设置为 16×16×1 和 8×8×4。每个模型使用单块 NVIDIA A100 GPU 生成 5000 个样品,批量大小分别为 100、200 和 500。
对于 100 和 200 的批量大小,与 VQ-GAN 相比,RQ-Transformer 显示出 4.1 倍和 5.6 倍的加速。此外,由于 RQ-VAE 的短序列长度节省了内存,RQ-Transformer 可以将批量大小增加到 500,而 VQ-GAN 是不允许的。因此,RQ-Transformer 可以进一步加快采样速度,每张图像为 0.02 秒,比批量大小为 200 的 VQ-GAN 快 7.3 倍。因此,RQ-Transformer 比以前的 AR 模型在计算上更高效,同时实现高分辨率图像生成基准的最新结果。
公众号后台回复“数据集”获取90+深度学习数据集下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~




