周志华:Boosting学习理论的探索 —— 一个跨越30年的故事
机器之心转载
来源:CCF微信公众号 (CCFvoice)
中国计算机学会通讯 (CCCF)
作者:周志华
这篇文章尝试用通俗故事的方式讲述一个机器学习理论中重要问题的探索历程。读者或能从中感受到机器学习理论探索的曲折艰辛,体会到理论进展对算法设计的指引意义。

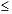 训练误差
训练误差
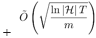 (
(
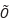 隐去了相对不太重要的其他项),这里的m是训练样本数,T是训练的轮数,
隐去了相对不太重要的其他项),这里的m是训练样本数,T是训练的轮数,
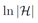 可以大致理解为基学习器的复杂度。因为AdaBoost每训练一轮就增加一个基学习器,所以
可以大致理解为基学习器的复杂度。因为AdaBoost每训练一轮就增加一个基学习器,所以
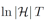 大致相当于最终集成学习器的复杂度。于是,这个理论结果告诉我们:训练样本多些好,模型复杂度小些好。
大致相当于最终集成学习器的复杂度。于是,这个理论结果告诉我们:训练样本多些好,模型复杂度小些好。
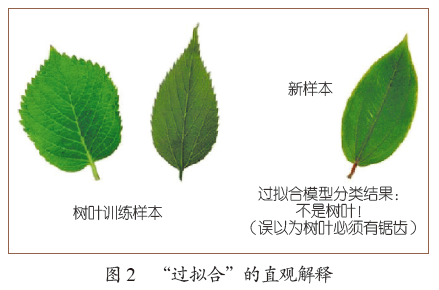
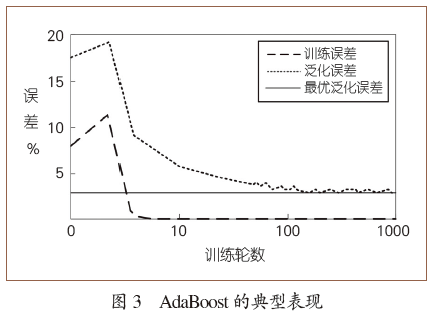
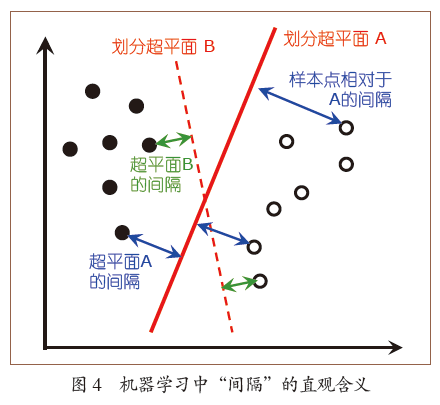

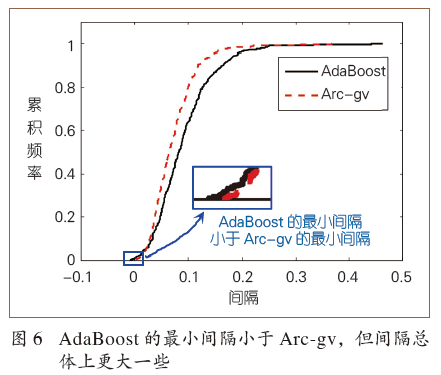



登录查看更多
相关内容

专知会员服务
35+阅读 · 2019年12月12日
Arxiv
5+阅读 · 2018年4月16日


相关VIP内容
专知会员服务
35+阅读 · 2019年12月12日
相关资讯
相关论文
Arxiv
5+阅读 · 2018年4月16日