开源自建/托管与商业化自研 Trace,如何选择?

为了搞清楚这个问题,我们需要从两方面入手,一是梳理线上应用的核心风险与典型场景。二是对比开源自建、托管与商业化自研三种 Trace 方案的能力差异。所谓“知己知彼,百战不殆”,只有结合自身实际情况,才能选择出最适合的方案。
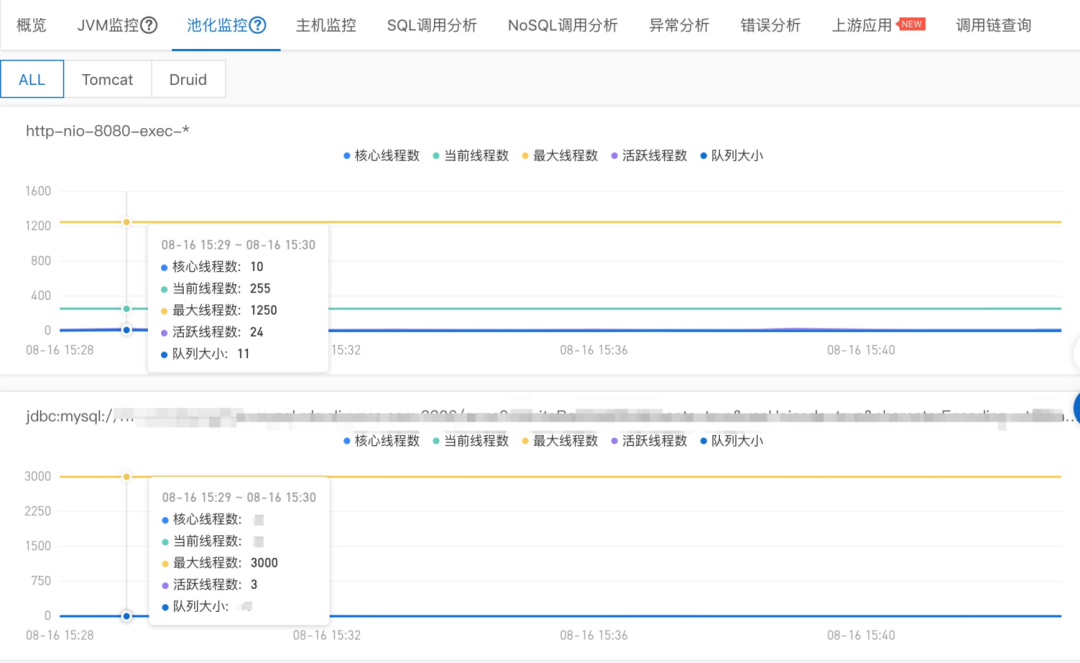
而商业化自研 Trace 提供的池化监控可以直接看到指定线程池的最大线程数、当前线程数、活跃线程数等,线程池耗尽或高水位风险一览无余。此外,还可以设置线程池使用百分比告警,比如设置 Tomcat 线程池当前线程数超过最大线程数 80% 就提前短信通知,达到 100% 时电话告警。
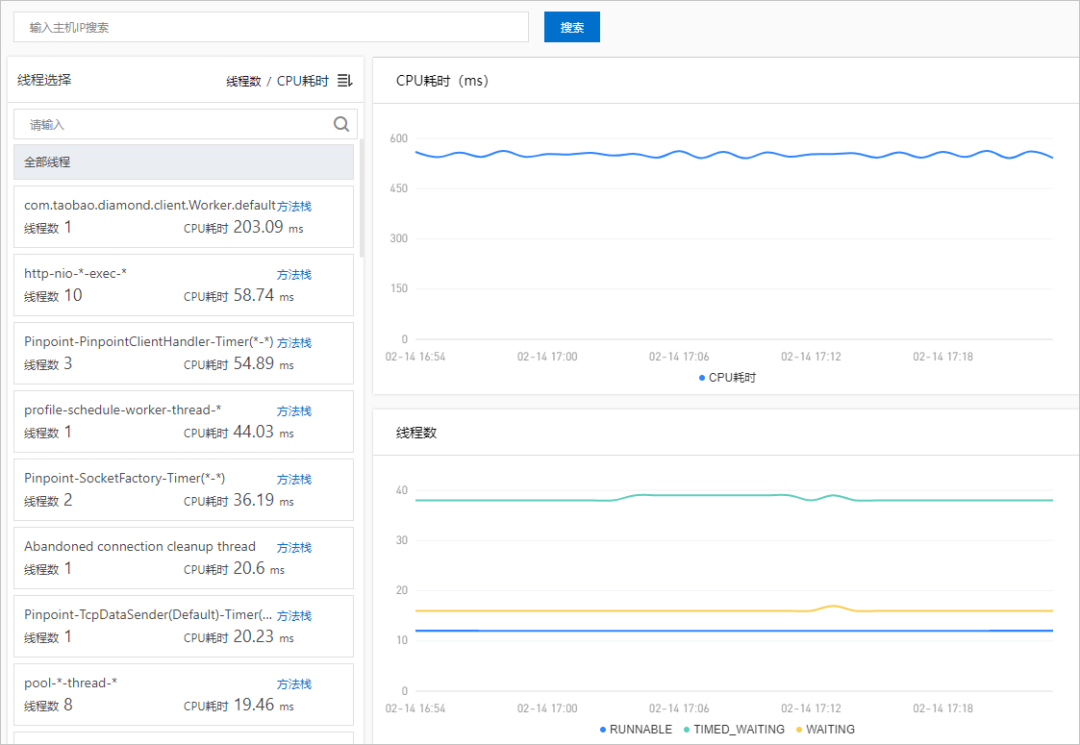
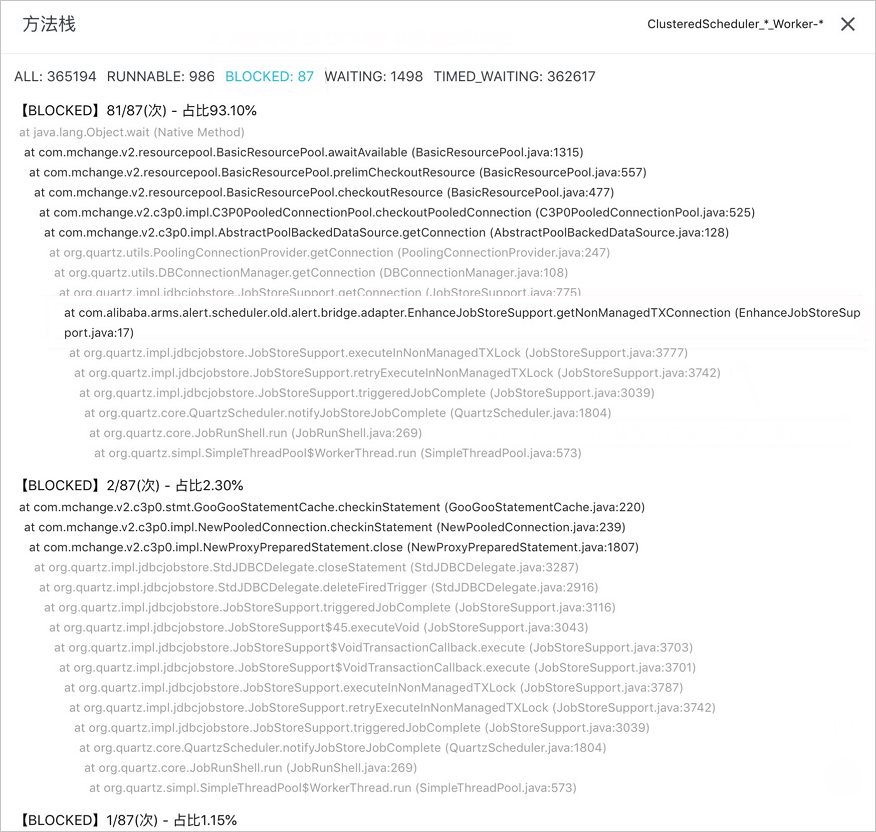
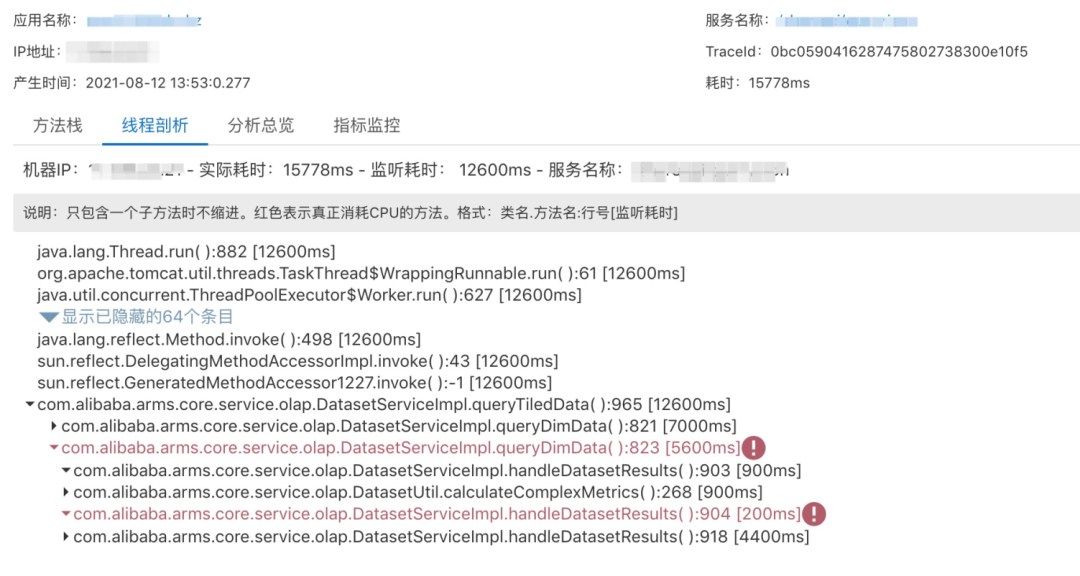
在这里,分享一个阿里内部发布系统的异常发布拦截实践,其中最重要的监测指标之一,就是 Java Exception/Error 的异常数比对。无论是 NPE(NullPointException),还是 OOM(OutOfMemoryError),基于全部/特定异常数的监控与告警,可以快速发现线上异常,特别是变更时间线前后要尤为注意。
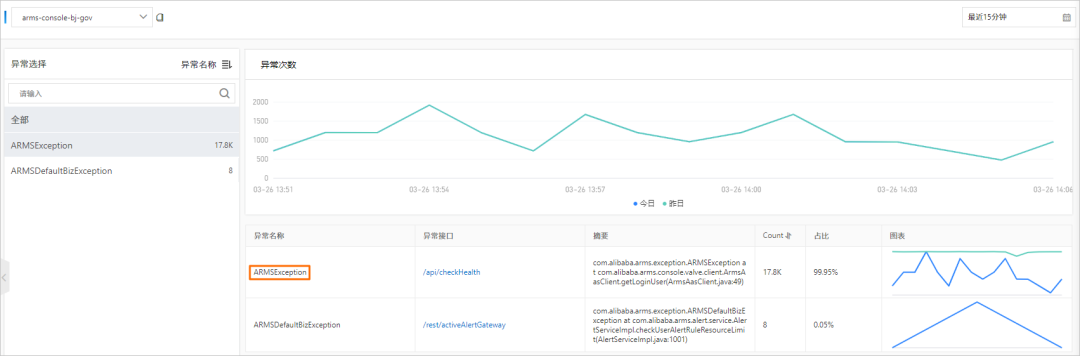
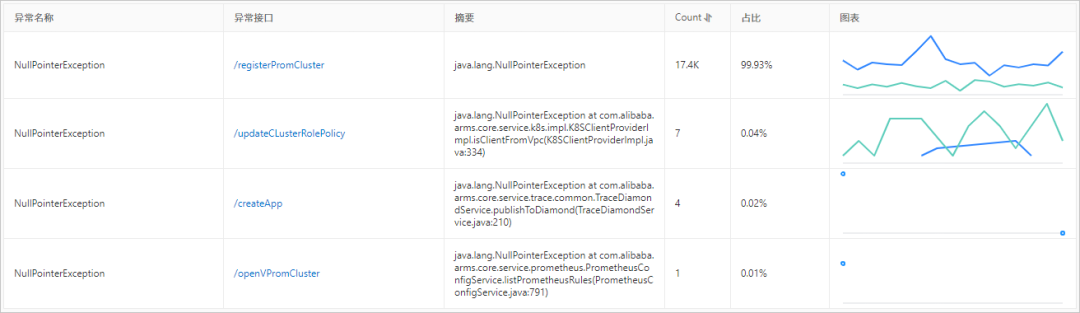
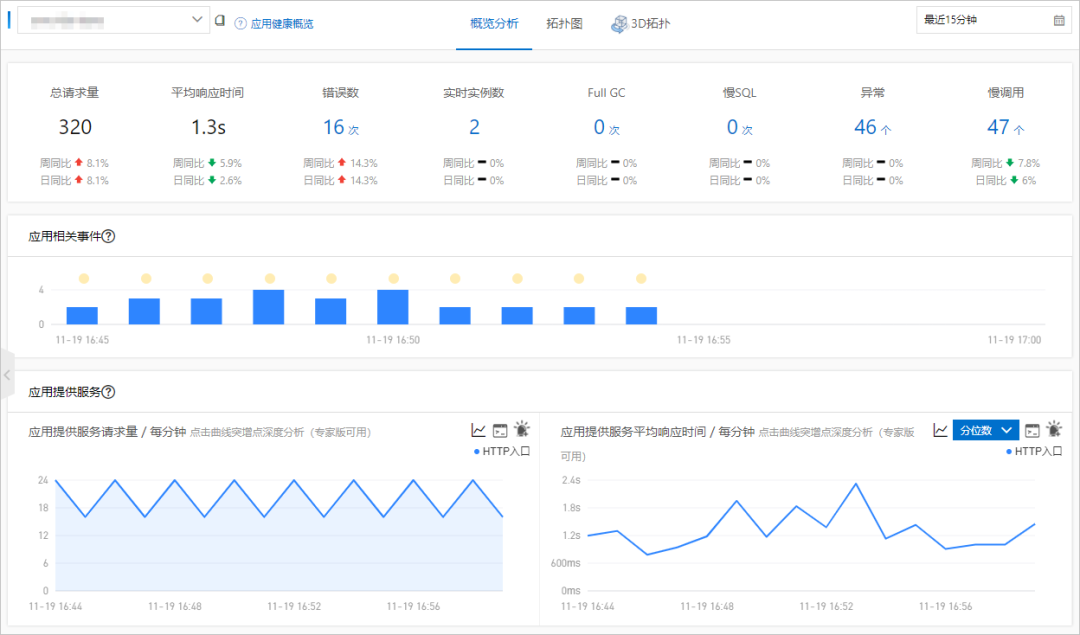
独立的异常分析诊断页面,可以查看每一类异常的变化趋势与堆栈详情,还可以进一步查看关联的接口分布,如下图所示。
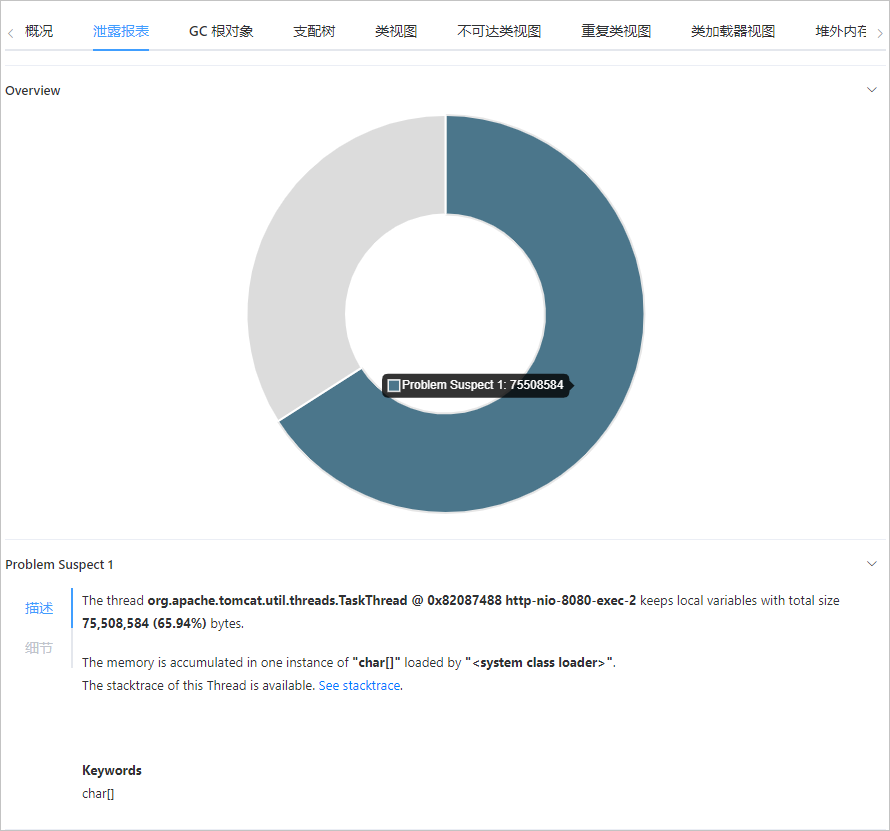
白屏化的内存快照功能,可以指定机器执行一键 HeapDump 与分析,大幅提升内存问题的排查效率,还支持内存泄漏场景下自动 Dump 保存异常快照现场,如下图所示:
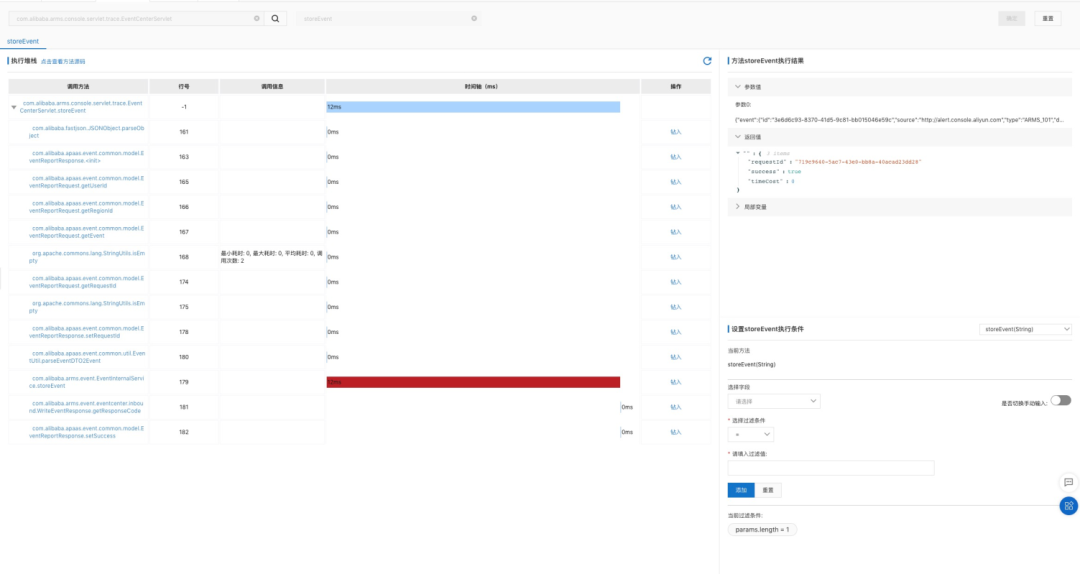
-
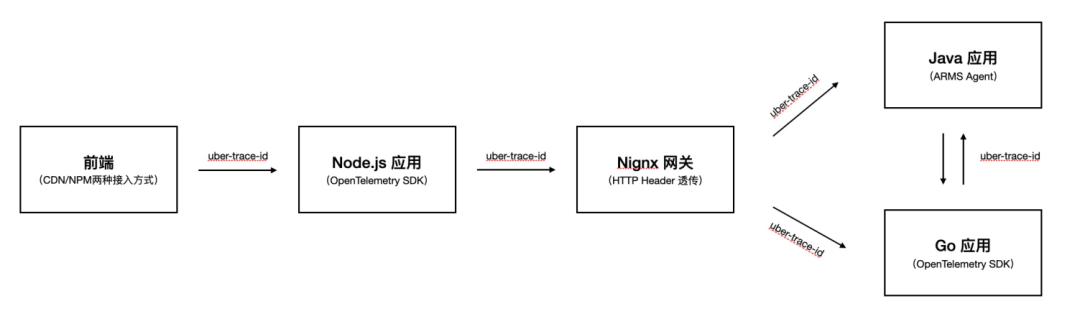
Header 透传格式:统一采用 Jaeger 格式,Key 为 uber-trace-id, Value 为 {trace-id}:{span-id}:{parent-span-id}:{flags} 。
-
前端接入:可以采用 CDN(Script 注入)或 NPM 两种低代码接入方式,支持 Web/H5、Weex 和各类小程序场景。
-
后端接入:
-
Java 应用推荐优先使用 ARMS Agent,无侵入式埋点无需代码改造,支持边缘诊断、无损统计、精准采样等高阶功能。用户自定义方法可以通过 OpenTelemetry SDK 主动埋点。
-
非 Java 应用推荐通过 Jaeger 接入,并将数据上报至 ARMS Endpoint,ARMS 会完美兼容多语言应用间的链路透传与展示。

为了解决上述问题,我们需要支持在客户端 Agent 进行无损统计,同一个指标在一段时间内(通常为15秒)不论请求多少次,都只会上报一条数据。这样统计指标的结果就始终是精准的,不会受到调用链采样率的影响。用户可以放心的调整采样率,调用链成本最多可降低 90% 以上。流量和集群规模越大的用户,成本优化效果越显著。
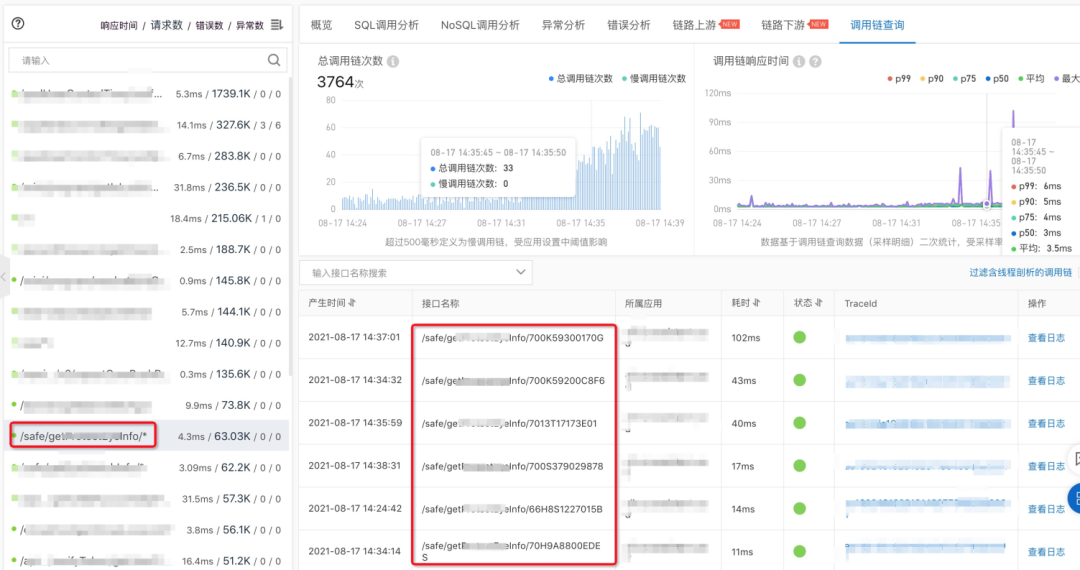
此时,我们需要提供一种针对接口名称的自动收敛算法,可以主动识别可变参数,将同一类接口进行聚合,观察类别变化趋势,更符合用户监控诉求;同时避免了接口发散导致的数据热点问题,提升了整体的稳定性与性能。如下图所示:/safe/getXXXInfo/xxxx 都会被归为一类,否则每一条请求都是一张只有一个数据点的图表,用户可读性会变的很差。
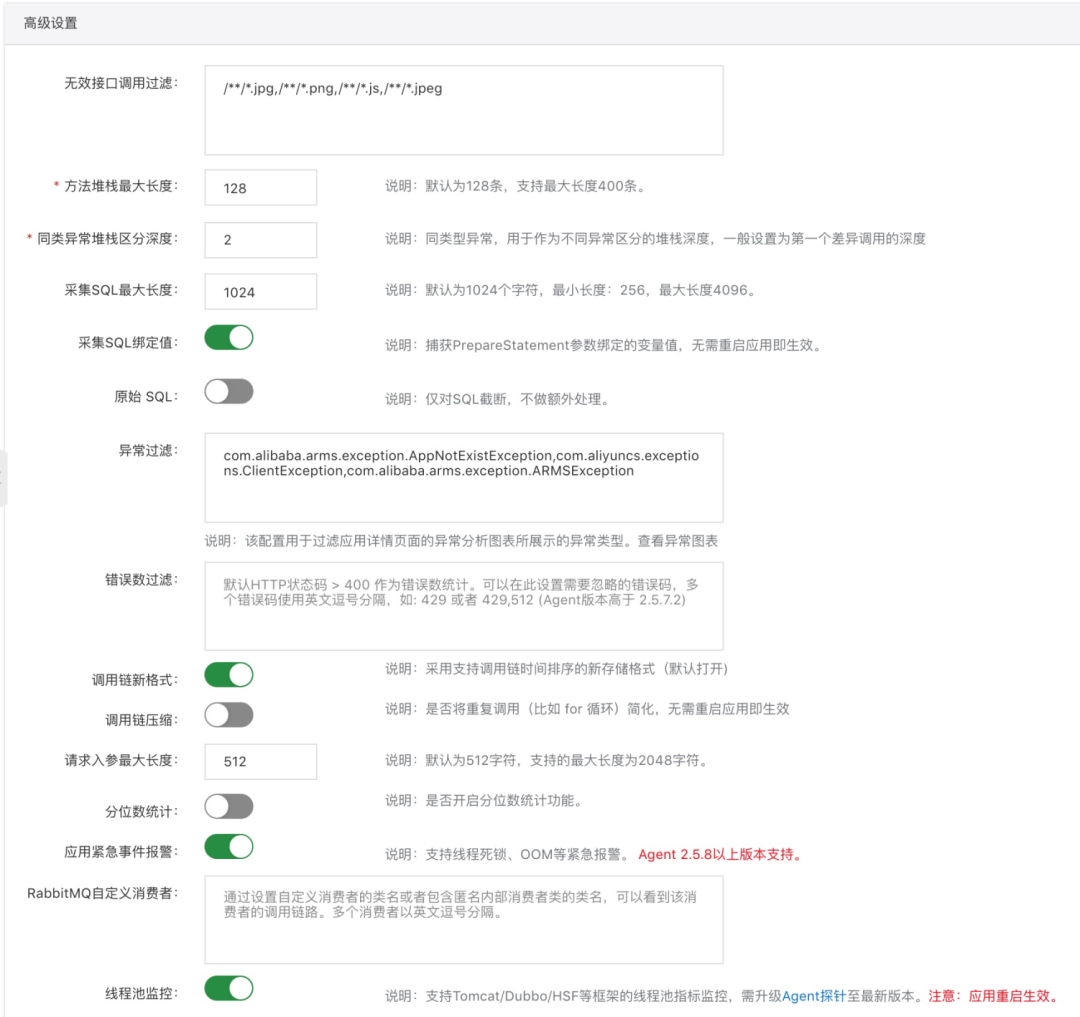
无论是动态降级还是动态开启,都需要在不重启应用的前提下进行动态配置下推。而开源 Trace 通常不具备这样的能力,需要自行搭建元数据配置中心并进行相应的代码改造。而商业化 Trace 不仅支持动态配置下推,还可以细化到每个应用独立配置,比如应用 A 存在偶发性慢调用,可以开启自动慢调用诊断开关进行监听;而应用 B 耗时对 CPU 开销比较敏感,可以关闭此开关;两个应用各取所需,互不影响。
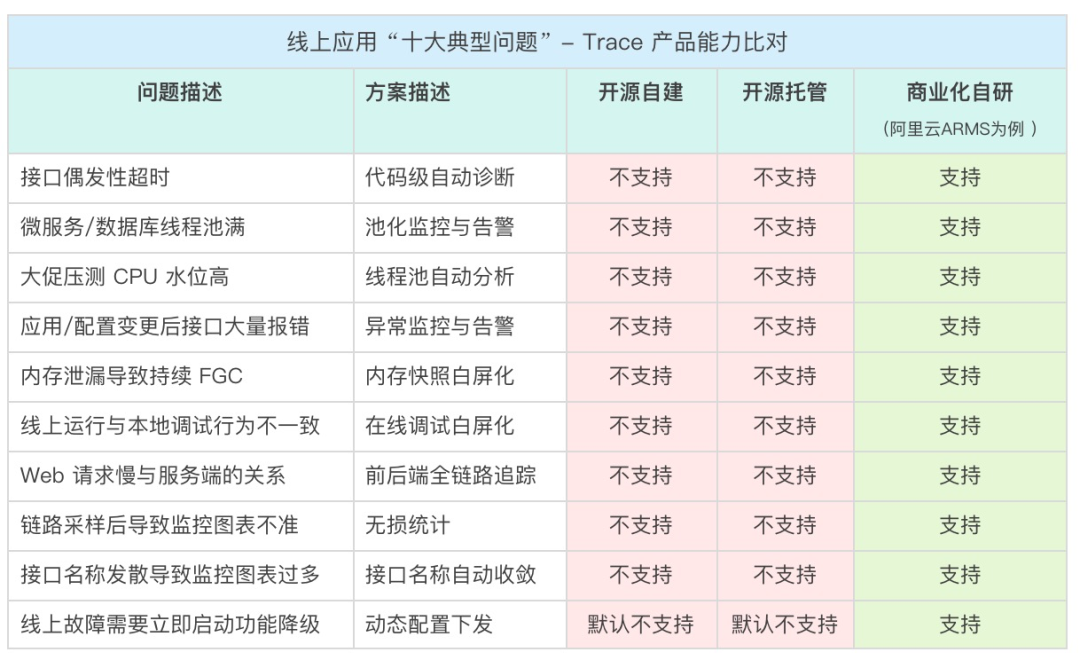
限于篇幅限制,本文仅通过 10个典型问题场景分析了开源自建/托管方案的不足,强调 Trace 并不简单,忽视了这一点,商业化自研产品踩过的坑,你可能会被迫重新体验。这就好比做互联网电商,不是在网上开个店铺就结束了,产品打磨、流量拓展、用户转化、口碑运营等等一系列复杂的环节隐藏在背后,贸然进入可能会赔的很惨。
那么开源自建/托管具备哪些优势?它们与商业化自研 Trace 产品在产品功能、资源/人力成本、二次开发、多云部署、稳定性、易用性等全方位的对比分析,就留待下一篇《开源自建、开源托管与商业化自研 Trace 产品全方位分析》,敬请关注。
【公开课】理解 Pod 和容器设计模式
登录查看更多
相关内容

Arxiv
0+阅读 · 2022年4月20日
Arxiv
1+阅读 · 2022年4月18日
Arxiv
1+阅读 · 2022年4月17日
相关主题


相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年4月20日
Arxiv
1+阅读 · 2022年4月18日
Arxiv
1+阅读 · 2022年4月17日