![]()
一 前言
2021年双十一刚刚落幕,已连续多年稳定支持双十一大促的云原生数据仓库AnalyticDB,今年双十一期间仍然一如既往的稳定。除了稳定顺滑的基本盘之外,AnalyticDB还有什么亮点呢?下面我们来一一揭秘。
二 长风破浪 | AnalyticDB再战双十一
今年双十一,AnalyticDB的战场横跨阿里数字经济体、公共云和混合云,三个战场都稳如泰山、成绩斐然。在阿里数字经济体内,AnalyticDB支撑的业务几乎覆盖了所有BU,诸如手淘订单搜索、菜鸟、淘特、盒马、飞猪、猫超、阿里云等近200个双11相关的核心业务;在公有云上,AnalyticDB支撑着数云、聚水潭等诸多电商相关的核心业务;在专有云上,AnalyticDB主要支持中国邮政集团的各类业务。今年AnalyticDB支撑的业务负载特别多元化,从单库百万级峰值TPS的实时数据写入到核心交易链路的高并发在线订单检索和关键字精准推荐,从各种业务场景下的复杂实时分析到各种人群和标签数据的大批量离线Batch&ETL任务以及数据导入导出任务,这种五花八门的业务负载,甚至离在线混合负载同时执行的场景,对AnalyticDB提出了巨大的挑战。
面对这些业务场景和技术挑战,AnalyticDB迎难而上,今年以来,全面拥抱云原生构建极致弹性,全面推进存储计算分离架构,通过冷热温分层存储大幅降低存储成本,通过升级向量化引擎和优化器框架大幅提升计算性能,全面推进离在线一体化架构,进一步提升在一套技术架构下同时稳定运行在线实时查询和离线批量计算任务的能力。正是有了这些技术积累和沉淀,AnalyticDB在今年的双十一战场上才能更加稳定从容,各项业务指标继续再创新高,今年双十一期间累计实时写入21万亿条数据,批量导入113万亿条数据,完成350亿次在线查询和2500万个离线任务,累计590PB数据参与计算。
不论是从支持业务场景的复杂度上看,还是从数据规模和计算规模上看,AnalyticDB作为离在线一体化架构下的新一代云原生数据仓库已经越来越成熟,可以为各种业务提供核心报表计算、实时分析决策、活动大屏与系统监控、智能营销等通用能力。同时,今年AnalyticDB重点结合手淘订单搜索和推荐、实时订单同步等核心业务场景,以技术创新为核心,帮助业务解决了不少长期困扰的棘手问题,助力业务在用户体验、绿色低碳、业务创新、安全稳定等方面取得新突破。
1 体验第一:看AnalyticDB如何优化手淘交易订单搜索
手淘订单搜索支持用户输入关键词或订单号查询历史订单,是通过历史订单关联商品和店铺从而产生复购的重要流量入口之一。不过由于用户的历史订单信息量非常大,达数千亿之多,而用户往往仅记得商品或店铺的模糊信息,导致用户输入的关键词要么不准确可能搜不到订单,要么关键字很短导致查找到订单很多响应时间很长,极大影响手淘用户的产品体验,长期为用户所诟病。
AnalyticDB基于新实时引擎+行存表+非结构化索引+宽表检索的在线能力,首次实现了在线和历史交易订单的统一存储、分析,赋能交易业务中台对全网用户十年全量的交易订单进行多维搜索,并根据用户的搜索关键字进行精准推荐。大促峰值期间用户反馈“订单查不到”的舆情同比大幅下降,查询性能也得到大幅提升,大大提升了手淘订单搜索的用户体验。
2 绿色低碳:看AnalyticDB如何助力业务降本增效
公共云客户数云赢家2.0全域CRM平台通过采用以云原生数据仓库AnalyticDB为核心的整体方案,在双11期间对客户洞察和细分、自动化营销等核心功能进行全面升级。基于云原生、资源池化和冷热数据分离能力,业务研发周期比往常缩短39%,整体成本下降50%,运营效率提升3倍,解决了采购实施成本过高难题,助力商家快速响应业务变化,降本增效成果显著。
阿里集团内部一个核心业务的数据分析服务每天需要执行大量ETL离线作业,同时需要支持大量实时数据写入,以满足准实时的人群圈选服务和在线人群透视服务需求,支持数据实时写入和离在线混合负载的AnalyticDB一直是该服务的不二之选。今年双十一期间,AnalyticDB 承担了该服务数十PB数据读写请求,数百万次的离在线混合查询,完成PB级数据量的ETL作业。得益于 AnalyticDB 3.0的云原生弹性能力,结合存储/计算/优化器 的全链路优化,成本同比去年双十一下降近50%。
3 唯快不破:看库仓一体化架构如何支持高吞吐实时业务
今年双十一首次采用AnalyticDB+DMS库仓一体化架构替换了DRC+ESDB实现全实时历史订单搜索等核心场景,快速搭建毫秒级延迟的实时数据链路和数据应用,让实时数据的价值得到充分发挥,助力业务在更加实时的数据应用场景和更加极致的用户体验上产生新变化、取得新突破。
在交易订单搜索业务中,根据交易业务特点搭建了多路数据同步链路并采用AnalyticDB主备容灾部署方案,双十一大促期间轻松支持RPS达数百万的峰值流量,全程毫秒级延迟。
三 常胜之秘 | AnalyticDB最新核心技术解析
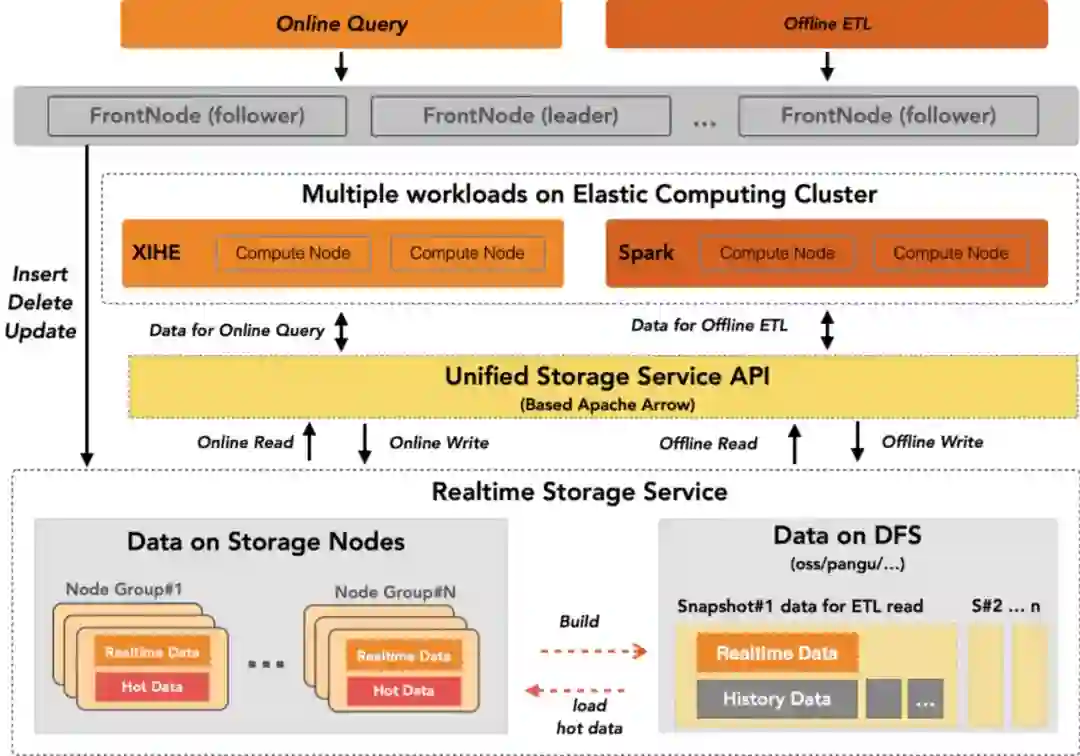
1 离在线服务化存储
AnalyticDB的存储层今年完成了服务化改造,具备一份数据、一套存储格式同时支持实时更新、交互式查询、离线ETL及明细点查多场景一体化能力。基于存储服务层、行列混存、分层存储、自适应索引等技术,可同时支持在线低延迟+强一致和离线高吞吐两种数据读写场景。
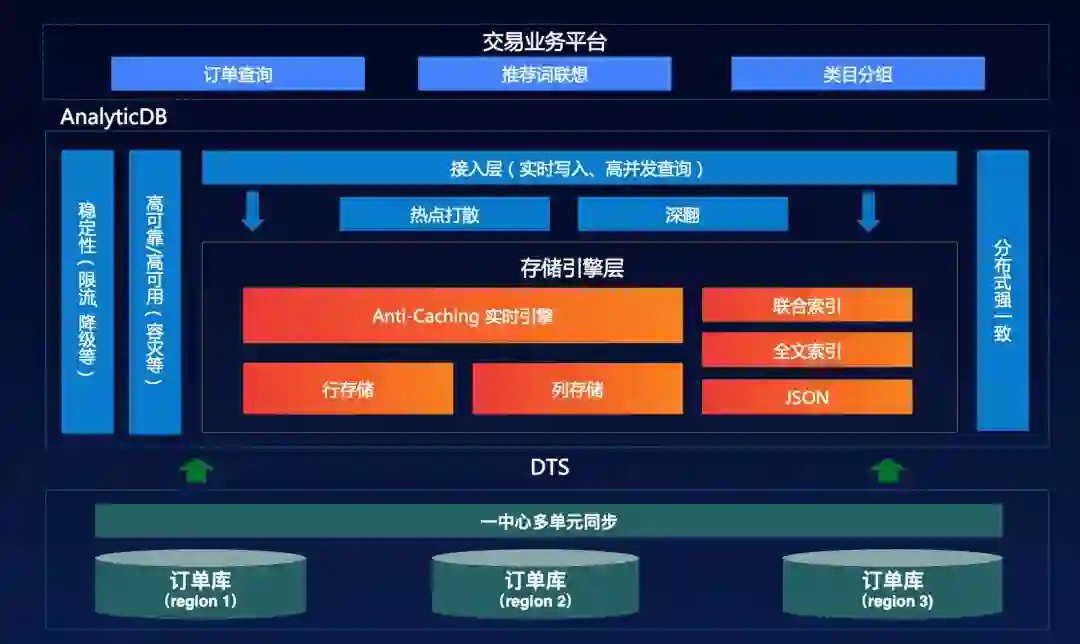
![]()
存储服务:离在线统一访问接口
接口层方面,AnalyticDB存储向上提供统一的数据访问接口,数据交互采用Apache Arrow[1]数据格式,基于零拷贝技术实现高效传输,计算层可以基于Arrow内存列式的接口进行CPU友好的向量化计算加速;元数据兼容Hive MetaService的Thrift交互协议,开源计算引擎可以无缝对接AnalyticDB存储系统。
服务层方面,AnalyticDB存储采用类LSM架构[2],把存储分为实时数据和历史数据两部分,实时数据存储在在线存储节点上,作为“热”数据,支持低延迟数据访问,且支持强一致CURD。历史数据存储在OSS或HDFS等低成本的分布式文件系统上,作为“冷”数据,支持高吞吐数据访问。同时,AnalyticDB存储服务层还支持谓词、投影、聚合、Top N等计算下推能力,减少数据的扫描和读取量,进一步加速查询。
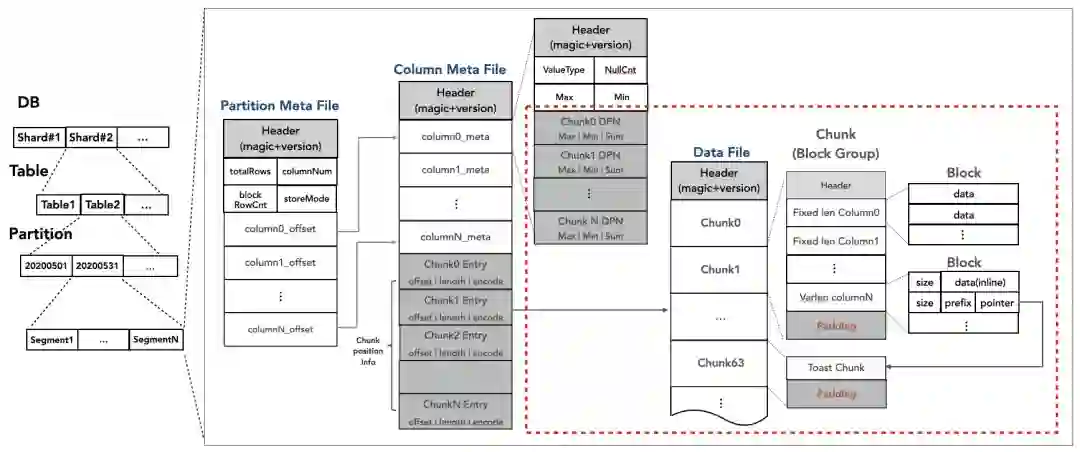
行列混存:离在线统一存储格式
既然提供了一体化的存储服务,必然会涉及到在线低延迟查询和离线高吞吐计算场景,AnalyticDB存储格式采用PAX格式[3]兼顾了离在线两种场景。
在线场景,与索引配合提供高效的检索查找能力。AnalyticDB的存储格式每个Chunk定长存储,能够和索引深度融合,可以基于行号随机查找,保证高效的随机读性能,可以很好地满足在线多维度筛选的场景。此外,还提供了丰富的统计信息,可以和索引配合做叠加优化,从而进一步加速查询。
离线场景,AnalyticDB的存储格式可以按照Chunk粒度切分数据读取的并行度,多Chunk并行访问,提高离线读的吞吐性能。AnalyticDB的一张表支持多个分区,且分区内支持多Segment,可以通过切分Segment来提高数据写入的并行度,从而提高离线写的吞吐性能。此外,每个Chunk提供了Min/Max等粗糙集索引信息,可以利用这些索引信息减少离线读的数据扫描量和IO资源消耗。
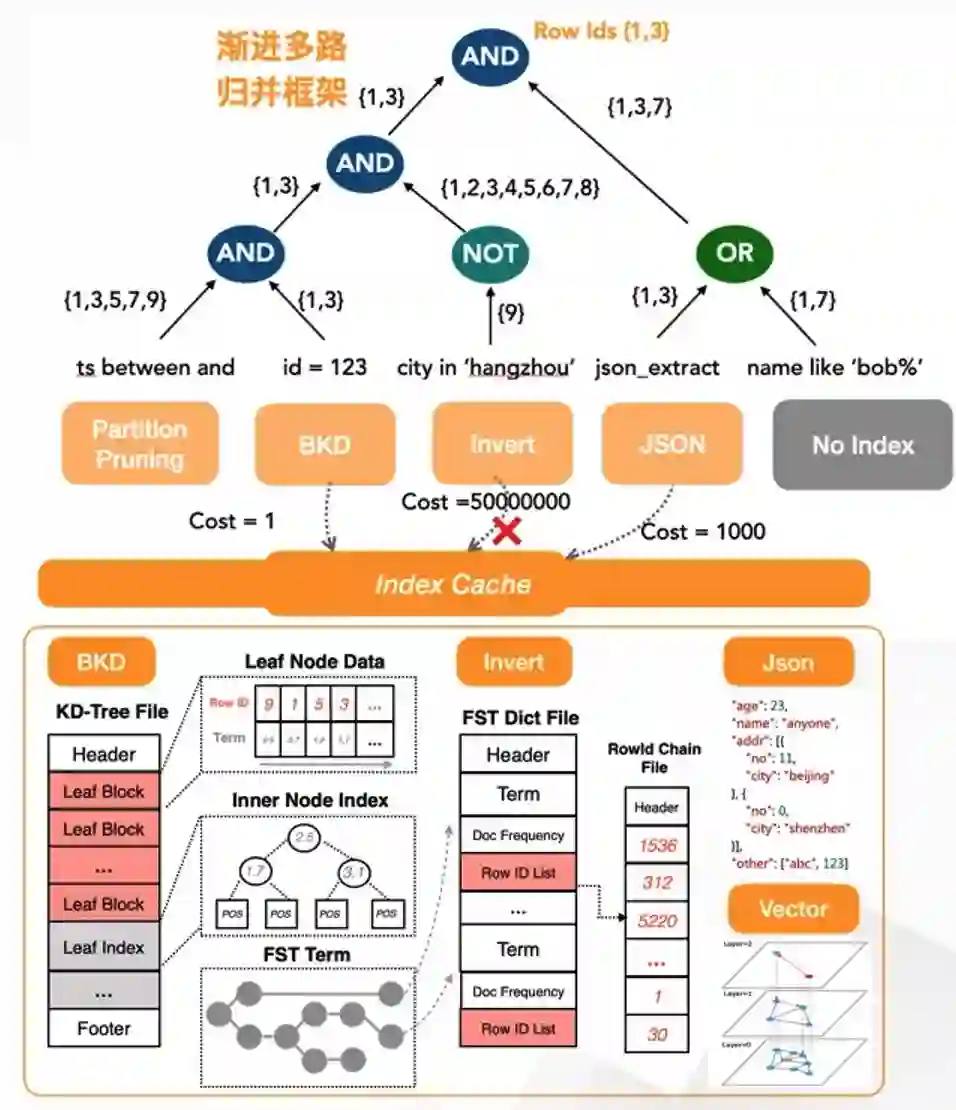
自适应索引
AnalyticDB另一个特色之一是自研自适应索引框架,支持五种索引类型:字符串倒排索引、Bitmap索引、数字类型KDTree索引、JSON索引和向量索引;不同类型的索引可以支持多种条件(交、并、差)下列级索引的任意组合;相较于传统数据库,AnalyticDB的优势在于,无需手工构建组合索引(组合索引需要精巧的设计、且容易引起索引数据的空间膨胀)、且支持OR/NOT等更多条件的索引下推。为了降低用户使用门槛,AnalyticDB在建表时可以一键自动开启全列索引,查询时通过Index CBO自适应动态筛选索引下推,确定下推的索引链会通过谓词计算层进行流式渐进多路归并输出。
冷热分层:降低用户成本、按量计费
AnalyticDB提供的冷热分层存储能力[4][5]可以为用户带来更高性价比的体验。用户可以按表粒度、表的二级分区粒度独立选择冷、热存储介质,比如指定用户表数据全部存储在热存储介质,或指定表数据全部存储在冷存储介质,或指定表的一部分分区数据存储在热存储介质,另一部分分区数据存储在冷存储介质,完全可以按业务需求自由指定,并且冷热策略可以自由转换。同时,热数据和冷数据的空间使用是按量计费的。业务可以根据自己的业务特点,基于AnalyticDB的冷热存储分层技术管理业务数据的生命周期,需要频繁访问的数据分区指定为热数据存储在热存储介质以加速查询,不需要频繁访问的数据分区指定为冷数据存储在冷存储介质以降低存储成本,通过数据分区的生命周期管理机制自动清理过期的数据。
2 离在线混合负载
在线场景的计算负载(比如在线查询)对响应时间要求高,对数据读取和计算引擎的要求就是快;而离线场景的计算负载(比如ETL任务)对响应时间不敏感,但对计算吞吐有较高要求,不仅数据计算量大,数据读取和写入量也可能很大,任务执行时间长。离在线两种完全不同场景的负载要在一套系统、一个平台上同时执行一直以来都是一个巨大的挑战。目前业界的主流解决方案仍然是:离线任务运行在离线大数据计算平台(比如hadoop/spark/hive)上,在线查询运行在另外一个或多个单独的OLAP系统(比如ClickHouse/Doris)上。不过在这种架构下,多个系统内部的数据存储和格式不统一,计算逻辑表示(比如SQL标准)也不统一,导致数据需要在多个系统之间相互导入导出,计算逻辑也需要分别适配对应的系统,数据链路冗长,数据计算和使用成本高,数据的时效性也不好。
为了解决此类问题,AnalyticDB今年全面升级离在线混合负载能力,除了存储层提供离在线统一存储格式和统一访问接口用以解决离在线混合负载的数据读取和写入问题,计算层也完成了全面升级,相同的SQL查询可以同时支持Interactive和Batch两种执行模式,通过资源组、读写负载分离、多队列隔离和查询优先级等机制对不同类型的负载进行资源隔离和管控,通过分时弹性满足不同负载的扩缩容和错峰需求。同时,计算引擎全面升级为向量化引擎,大幅提升计算性能。
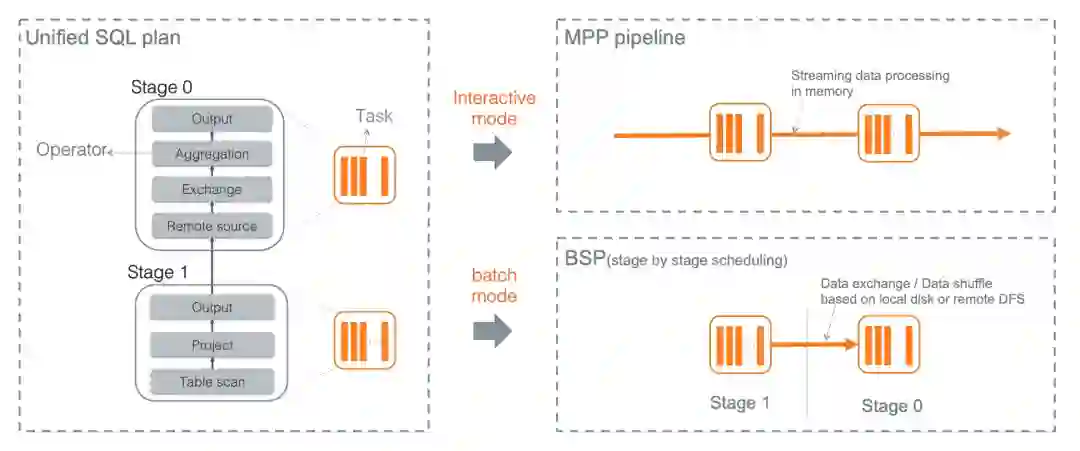
相同SQL两种执行模式
AnalyticDB支持Interactive和Batch两种执行模式,以分别满足在线查询和离线计算的不同场景需求。Interactive模式下,查询以MMP(Massive Parallel Processing)方式执行,所有Task同时调度启动,流式读取数据并计算输出结果,所有计算都在内存中进行,尽可能减少查询执行时间,适合在线场景负载。Batch模式下,计算任务以BSP(Bulk Synchronous Parallel)方式执行,整个任务会根据语义切分成多个阶段(Stage),根据Stage间的依赖关系进行调度和执行,上游Stage执行完才会执行下游Stage,Stage之间的数据传递需要落盘,计算过程中内存不足时也会将中间状态落盘,因此任务整体的执行时间会较长,但对CPU和内存等计算资源的需求相对较少,适合数据大、计算资源相对有限的离线场景。
在AnalyticDB内部,不论是Interactive模式还是Batch模式,表达计算逻辑的SQL是统一,产生的逻辑执行计划也是完全一样的,只是根据不同的模式生成不同的物理执行计划,且计算引擎中绝大部分的算子实现也是相同的,也为统一升级到向量化计算引擎奠定架构基础。
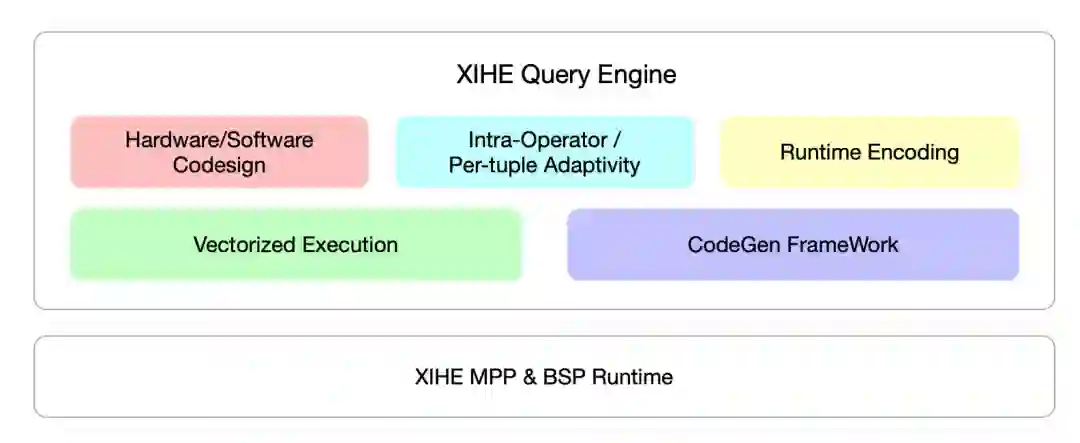
全新向量化查询引擎
向量化是当代查询引擎优化查询性能的热点技术之一,相关思路最早可以追溯到Array programming在科学计算领域的研究,在数据库领域的探索则缘起于MonetDB/X100[6]。目前工业界各主流系统都拥有自己的向量化实践,但仍缺乏标准的形式化定义。一般来讲,它被认为是查询引擎面向CPU microarchitecture一系列优化方案的统称,涉及Batch based iterator model[7],CodeGen,Cache-awareness算法[8]以及SIMD指令集应用等技术应用,以及计算/存储一体化的架构设计。而探索并识别这些技术间正交/依赖的关系是利用好向量化技术取得显著性能提升的关键问题。
AnalyticDB实现了核心算子的全面向量化,包括Scan,Exchange,Group-by/Agg,以及Join算子;方案里结合应用了Batch Processing,Adaptive Strategy,Codegen以及Cache-awareness算法,并通过与JVM团队共建,基于AJDK intrinsic能力[9]创新地实现了算法关键路径上SSE2,AVX512等指令集的应用。显著提升查询执行过程中CPU IPL和MPL,热点算子Agg/Join的吞吐性能提升2x-15x。
混合负载隔离和稳定性保障
多种负载在同一架构下运行,甚至在同一时刻运行,不可避免存在资源竞争、相互影响的问题。AnalyticDB有一套较为完整的的机制和策略来保证集群的稳定性,并且尽可能满足不同业务负载的SLA要求。
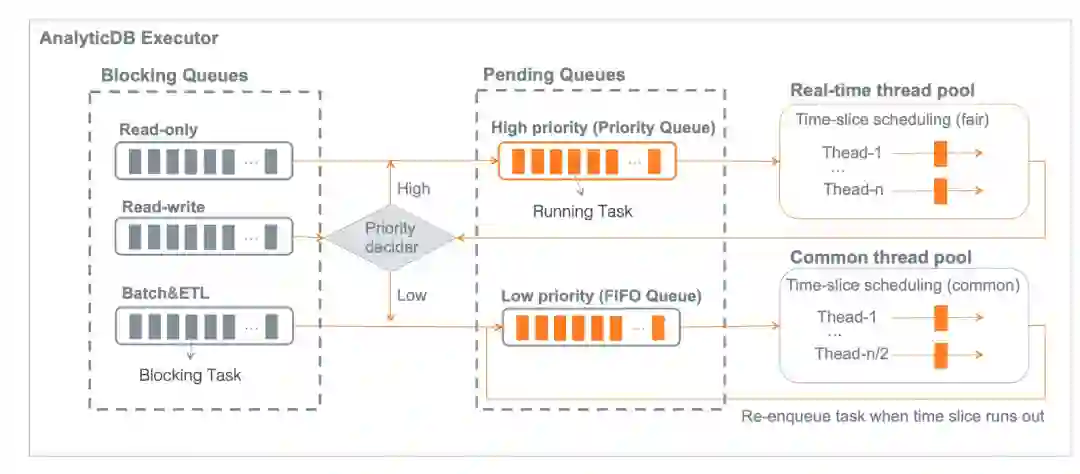
首先,在混合负载场景或实例内部多租户场景下,可以通过资源组进行有效的业务负载隔离。不同资源组之间的计算资源在物理上完全隔离,避免不同类型或业务的负载之间产生相互影响。不同的业务可以通过绑定账号、提交查询时指定资源组等多种方式指定运行在对应的资源组上。
其次,AnalyticDB内部会自动区分写入负载(部分insert和delete)、查询负载(比如select查询)和读写负载(部分insert/update/delete),不同类型的负载任务自动分派到不同的队列上,且分配不同的执行优先级和计算资源。具体来看,写入请求有单独的加速写入链路和资源保证,查询负载默认有较高的执行优先级,而读写负载则默认是较低的执行优先级。另外,在执行过程中,AnalyticDB会根据集群的当前负载情况和查询任务已运行的时长,动态降低运行时间较长的查询任务的执行优先级,以缓解Slow Query或Bad Query对其它查询产生的不利影响。
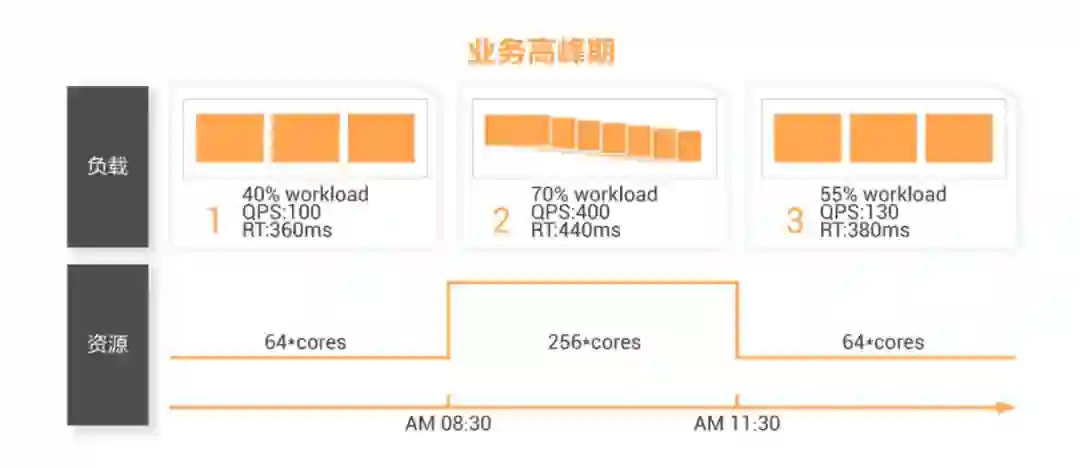
最后,很多业务都有非常明显的呈现周期性的波峰波谷,特别是离线计算任务往往是周期性进行调度和执行的,业务高峰期时资源需求暴增可能导致业务不稳定,业务低峰期时资源闲置又导致额外的成本。AnalyticDB提供分时弹性功能,可以帮助用户在业务高峰期资源不足时扩容资源以保证业务负载稳定执行,在业务低峰期时缩减资源以节约成本。通过合理的业务规划和资源组管理,用户甚至可以让某些资源组在低峰期时释放所有资源,极大地节约成本。
![]()
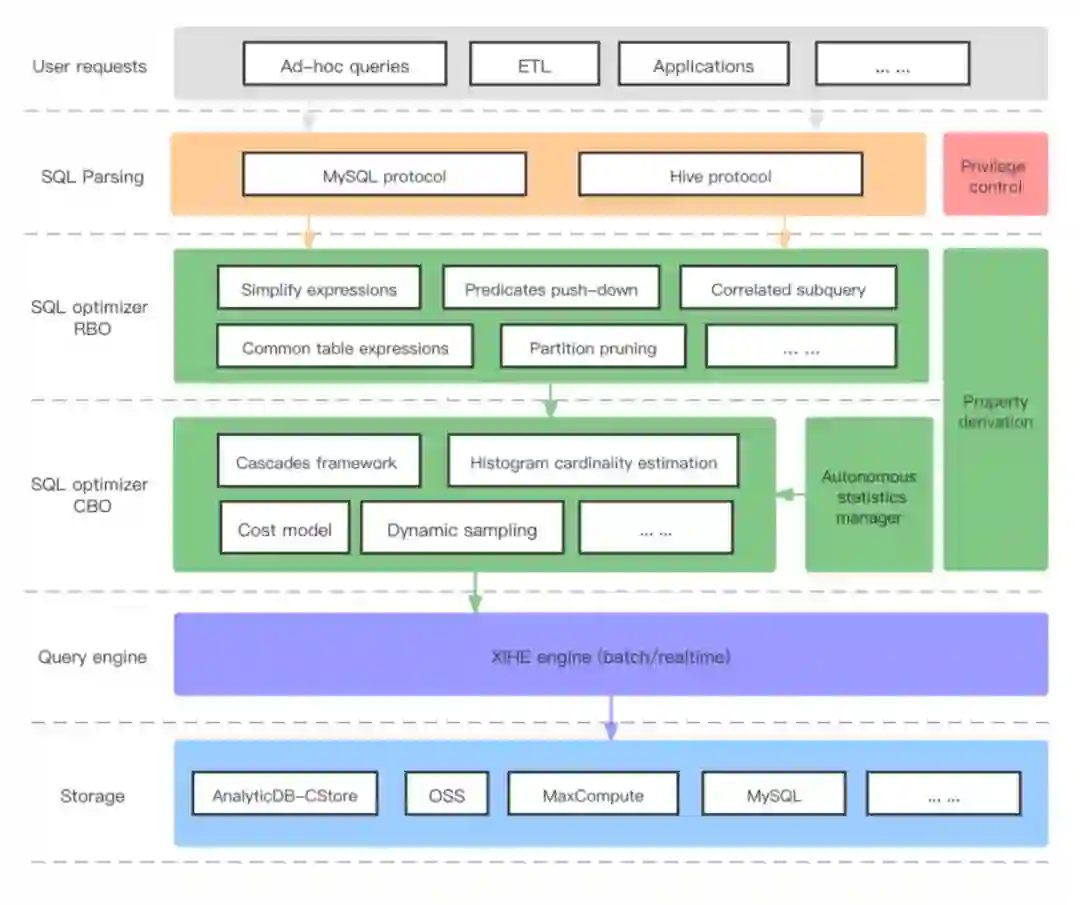
3 全新优化器框架
近年来,自治(Autonomous)能力已经成为数据库发展的重要方向和趋势。与传统数据库相比,云数据库提供一站式托管服务,也对自治能力提出了更高的要求。为此,AnalyticDB 研发了全新的优化器架构,向更加智能化的自治数据库方向迈进,为用户带来更好的体验。
![]()
AnalyticDB 优化器进行了大面积的重构升级,主体上拆分成 RBO (Rule-based optimizer) 和 CBO (Cost-based optimizer)。RBO 负责做确定性的优化。比如,将过滤条件尽可能下推,以减少后续算子的运算量。CBO 负责做不确定性的优化。比如,调整 JOIN 运算的顺序。调整的收益是不确定的,所以需要通过代估模块来决策。为了让这两大模块更好的工作,给予用户更好的体验,AnalyticDB 引入了全新的四大特性。
特性1:Histogram
直方图的引入,可以有效提升代估的质量,让 CBO 选出更好的计划。直方图可以有效解决用户数据值的分布不均问题,有效解决代估中“均匀分布假设”问题。为了验证直方图效果,AnalyticDB还构建了一套代估质量评价系统。在灰度实例中,代估综合错误率降幅可达50%以上。
特性2:Autonomous statistics
如何管理好表的统计信息,也是一个非常头疼的问题。如果把这个问题抛给用户,让用户执行命令去收集统计信息,会给用户带来巨大的困扰。为此,AnalyticDB引入了统计信息自治框架,来管理这个事情。AnalyticDB会尽可能降低收集动作对用户的影响,带来最好的体验。AnalyticDB会识别出每一列需要收集的统计信息等级,不同等级收集开销不同。同时也会识别出统计信息是否过期,来决定是否要重新收集。
特性3:Incremental statistics
传统的统计信息收集方式,需要进行全表扫描。全表扫描开销大,对用户影响大,不符合提升用户体验的初衷。为此,AnalyticDB引入了增量统计信息框架,可以只更新单个分区的统计信息,然后通过全局合并技术,得到整个表全局的统计信息。这样可以大幅降低收集的开销,减少对用户的影响。
特性4:Property derivation
如何让计划变得更优,属性推导对此有着重要的意义。它就像电影中的彩蛋,需要你去发掘。我们通过这个特性可以发掘SQL中隐含的信息,从而进一步优化计划。比如,用户 SQL 写了 “A=B” 条件,之后又做了一次 “GROUP BY A,B”,那么其实是可以简化成 “GROUP BY A” 或 “GROUP BY B”。因为我们通过属性推导,知道了A等价于B。
4 智能诊断和优化
智能诊断
AnalyticDB的智能诊断功能融合逻辑执行计划和物理执行计划,从「Query级别」,「Stage级别」,「算子级别」三个层次诊断分析,帮用户快速定位问题Query、Stage和算子,直接给出直观的问题分析,如数据倾斜、索引不高效、条件没下推等,并给出对应的调优建议。目前已经有20+诊断规则上线,涉及查询相关的内存消耗、耗时、数据倾斜、磁盘IO以及执行计划等多个方面,后续还有更多诊断规则陆续上线。
智能优化
AnalyticDB的智能优化功能提供针对数据库、表结构的优化功能,为用户提供降低集群使用成本、提高集群使用效率的调优建议。该功能基于SQL查询的性能指标以及使用到的数据表、索引等信息进行算法统计分析,自动给出调优建议,减少用户手动调优的负担。智能优化目前提供三种类型的优化建议:
1) 冷热数据优化:分析数据表的使用情况,对长期未使用的数据表,建议将其迁移至冷盘存储,约60%的实例可以通过该建议的提示,将 15 天未使用的数据表移至冷存,节省 3 成以上的热存空间;
2)索引优化:分析数据索引的使用情况,对长期未使用的数据索引,建议将其删除,约50%的实例可以通过该建议的提示,将 15 天未使用的索引进行删除,节省 3 成以上的热存空间;
3)分区优化:分析数据查询实际需要使用的分布键与数据表定义的分布列之间的差异,对设计不合理的分布键,建议变更该数据表的分布键,以提高数据的查询性能。
四 总结和展望
经过多年双十一的淬炼,AnalyticDB不仅抗住了一年高过一年的的极端负载和流量,也在不断丰富的业务场景中逐步成长,不断赋能到集团内外各种新老业务和场景中,逐步成长为新一代云原生数据仓库的佼佼者。接下来AnalyticDB将继续以“人人可用的数据服务”为使命,进一步拥抱云原生,构建数据库+大数据一体化架构,建设极致弹性、离在线一体、高性价比、智能自治等企业级能力,进一步赋能用户挖掘数据背后的商业价值。
参考文献
[1] Apache Arrow. https://arrow.apache.org.
[2] O'Neil P , Cheng E , Gawlick D , et al. The log-structured merge-tree (LSM-tree)[J]. Acta Informatica, 1996, 33(4):351-385.
[3] Ailamaki A , Dewitt D J , Hill M D , et al. Weaving Relations for Cache Performance. 2001.
[4] Kakoulli E , Herodotou H . OctopusFS: A Distributed File System with Tiered Storage Management[C]. ACM, 2017.
[5] Herodotou H , Kakoulli E . Automating Distributed Tiered Storage Management in Cluster Computing[J]. Proceedings of the VLDB Endowment, 2019.
[6] Boncz P A , Zukowski M , Nes N J . MonetDB/X100: Hyper-Pipelining Query Execution[J]. CIDR, 2005.
[7] Zhou J , Ross K A . Buffering database operations for enhanced instruction cache performance. SIGMOD, 2004.
[8] S. Manegold, P. A. Boncz, and M. L. Kersten. Optimizing database architecture for the new bottleneck: Memory access. The VLDB Journal, 9(3):231-246, 2000.
[9] JVM intrinsic. https://www.baeldung.com/jvm-intrinsics.
云原生&乘风者联合征文活动——说出你和「阿里云云原生」的故事
年末最重磅的征文活动正式启动了!!!阿里云云原生团队联合阿里云开发者社区共同发布的“云原生乘风者计划”,邀请广大技术人,写下你与阿里云云原生的故事。
参与即可免费获得价值350元的云原生大会门票,还有阿里云精美奥运礼盒,苹果Air pods pro任你挑选呦。赶紧点击阅读原文参与进来!福利多多!