利用上下文常识,让AI读懂不完整人类指令 | 一周AI最火论文

大数据文摘专栏作品
作者:Christopher Dossman
编译:笪洁琼、conrad、云舟
呜啦啦啦啦啦啦啦大家好,本周的AI Scholar Weekly栏目又和大家见面啦!
AI Scholar Weekly是AI领域的学术专栏,致力于为你带来最新潮、最全面、最深度的AI学术概览,一网打尽每周AI学术的前沿资讯。
周一更新,做AI科研,每周从这一篇开始就够啦!
本周关键词:强化学习、深度学习、不完整自然语言处理
本周热门学术研究
九大实际应用中的强化学习挑战
为了缩小RL研究与实际应用之间的差距,研究人员最近提出了实际应用RL的9大挑战。目前面临的一些挑战包括有限样本,离线训练,高维连续状态和行动空间,未指定的、多目标的或风险敏感的回报函数等等。
该研究指出了一种可以解决上述挑战的深入研究方法。一旦完成,找到的方法和解决方案就可以实现部署特定的可实际应用系统。
如果您是ML社区的一员,您一定知道RL让我们能够构建许多工业应用程序的自动化、人工智能系统。例如,实际应用中的RL可以用于个性化动态推荐系统、多渠道营销、自动化购买、药物定制、机器人控制、供应链优化、自动机器校准等等领域。
原文:
https://arxiv.org/pdf/1904.12901v1.pdf
100万个用于几何深度学习方法和应用的CAD模型
学者们引入了一个新的、庞大的ABC数据集——包括100万个用于研究几何深度学习方法和应用的计算机辅助设计(CAD)模型。
每个模型都通过一组简单的参数化曲线和曲面来表示,这些曲线和曲面为微分量、patch分割、几何特征检测和形状重建提供了依据。
研究人员对平面法线的估计进行了大规模的基准测试,比较了现有的数据驱动方法,并将其性能与平面真实值和传统的法线估计方法进行了比较。
这是人工智能社区向前迈的一大步,这种新的3D数据集可以实现数据驱动的处理和几何数据的应用。
数据集和相关信息:
https://deep-geometry.github.io/abc-dataset/
原文:
https://arxiv.org/abs/1812.06216v2
用于产品表示学习的高质量新数据集
受ImageNet数据集成功的激励,为了能够了解客户如何理解产品,研究人员采用了数据第一和质量第一的方法,通过开发ProductNet来促进产品表示学习。这是一个高质量的标记产品数据集集合。
该框架是构建产品标签和构建高质量数据集的一种快速可靠的方法。主模型可以为产品列表、产品索引和分区键等提供可接受的业务标签;所得到的产品嵌入可以支持各种产品建模任务和业务应用。评估已经证实,高质量的数据集可以促进高质量的产品嵌入。
利用标记数据,主模型分类精确度可以达到94.7%(1240类)。这可以被用作机器学习模型的搜索索引、分区键和输入特性。此外,针对特定业务任务的、优化后的主模型可用于各种迁移学习任务。
原文:
https://arxiv.org/abs/1904.09037
如何用常识性推理使机器人理解不完整的自然语言
LMCR是一种新的常识性推理方法,利用上下文背景使机器人能够聆听人类的自然语言指令。根据观察周围的环境,自动填补指令中缺失的信息。
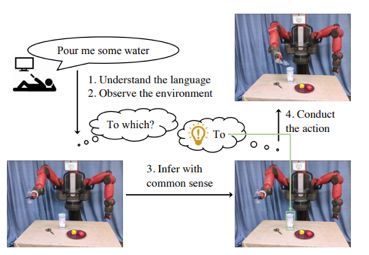
输入的语音是一个无限制自然语言的指令,该方法首先将指令进行转换,将其解析为机器人的动词框架能理解的形式。然后它通过观察指令周围的对象,并利用常识性推理来填补指令中缺失的信息。
为了自动学习常识性推理,LMCR通过训练语言模型(LM),从大型非结构化文本语料库中提取知识。测试和评估结果证明了机器人从网络的文本语料库中自动学习常识性知识的可行性。
使用LMCR,机器人可以执行自然语言指令指定的任务,并解决指令中缺少的信息。这一方法对于促进机器人在真实场景中的交互具有很大的潜力。
原文:
https://arxiv.org/abs/1904.12907v1
你需要的,只有分割(Segmentation)
由于所有提出的区域检测方法都高度要求使用非最大抑制(NMS)或其变体,因此研究人员提出了弱监督分割多模式标注,以便在不使用NMS的情况下实现高鲁棒的目标检测性能。
它们在复杂环境下利用带弱注释的边界框执行了对对象的识别。它们还避免了与锚定框和NMS相关的所有超参数。
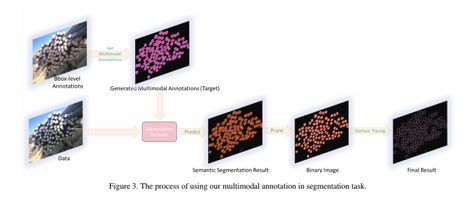
运用多模注释分割任务的过程
为了证明所提出的NMS和锚定框自由范式的优势,该方法在Rebar Head Detection Challenge Dataset1、WiderFace Dataset2和MS COCODetection Dataset上进行了测试。结果证明该模型简单易用,性能优于传统的基于锚点的单级和多级探测器。
该方法所提出的多模态注释实现了基于非NMS方法的实例感知解决方案,具有较强的鲁棒性。
通过引入分割,模型可以利用经过再训练的特定的标注拓扑结构来缓解遮挡问题。此外,像素级标注可以很好地描述场景中的小对象,能显著降低模型噪声。
原文:
https://arxiv.org/abs/1904.13300v1
其它爆款论文
可穿戴技术帮助视障人士进行环境感知
https://arxiv.org/abs/1904.13037v1
基于移动设备快速、有效检测人脸的新框架
https://arxiv.org/pdf/1904.12094v1.pdf
如何使用单个参数来匹配任何数据集
https://arxiv.org/pdf/1904.12320v1.pdf
如何利用神经网络提高图像识别的收敛性,降低训练复杂度
https://arxiv.org/ftp/arxiv/papers/1904/1904.13204.pdf
通过算法识别趋同的社会和技术趋势,从而引导社会监管
https://arxiv.org/ftp/arxiv/papers/1904/1904.13316.pdf
AI新闻
英伟达解释了人工智能(AI)的真正应用是如何产生影响的
https://www.artificialintelligencenews.com/2019/04/26/nvidia-how-adoption-ai-impact/
科学家利用基于机器学习的发现来帮助开发新的、可替代的磁性材料
https://spectrum.ieee.org/at-work/innovation/algorithms-and-autonomous-discovery
人工智能(AI)能教会银行哪些关于客户的事
https://www.forbes.com/sites/crowe/2019/04/29/what-ai-can-teach-banks-about-their-customers/#6cdd1a436076

Christopher Dossman是Wonder Technologies的首席数据科学家,在北京生活5年。他是深度学习系统部署方面的专家,在开发新的AI产品方面拥有丰富的经验。除了卓越的工程经验,他还教授了1000名学生了解深度学习基础。
LinkedIn:
https://www.linkedin.com/in/christopherdossman/
志愿者介绍
后台回复“志愿者”加入我们