Google Brain推出语音识别新技术、面部表情识别助力商业再发展|AI一周学术

大数据文摘专栏作品
作者:Christopher Dossman
编译:fuma、云舟
呜啦啦啦啦啦啦啦大家好,本周的AI Scholar Weekly栏目又和大家见面啦!
AI Scholar Weekly是AI领域的学术专栏,致力于为你带来最新潮、最全面、最深度的AI学术概览,一网打尽每周AI学术的前沿资讯。
周一更新,做AI科研,每周从这一篇开始就够啦!
本周关键词:语音识别、环境声音分类、CNN、面部表情识别
本周热门学术研究

语音自动识别技术:SpecAugment
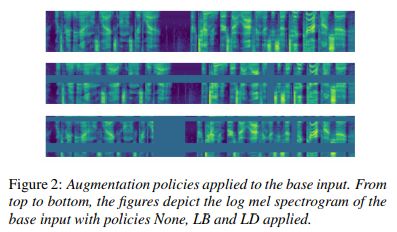
受先前语音和视觉领域增强成功的启发,Google Brain最近提出了SpecAugment,一种数据增强方法,它操作输入音频的对数mel光谱图,而不是原始音频本身。
SpecAugment方法不但非常简单,计算成本也很低,因为它直接作用于对数mel光谱图,而不需要额外的数据。这种简单的方法非常有用,并使研究人员能够训练端到端的监听参与和拼写ASR网络。
通过使用简单的手工策略增加训练集,即使没有语言模型的帮助,研究人员也能够在端到端的LAS网络上获得librispeech 960h和Switchboard 300h超越混合系统的性能。它优于复杂的混合系统,通过使用更大的网络和更长的训练时间,SpecAugment能够达到最先进的效果。
潜在效果及应用
全球自动语音识别(ASR)市场预计在2016年至2024年间以超过15%的复合年增长率增长。随着先进电子设备的飞速使用,人们对开发尖端功能和效率的需求越来越大,这样的功能和效率提高了应用的ASR精度。
SpecAugment显著提高了ASR的性能,并可能成为人工智能工程师驱动下一代ASR应用程序所需的必要条件,这些应用程序包括机器人、交互式语音响应、自定义词典、视频游戏、语音验证、家用电器等。
原文:
https://arxiv.org/pdf/1904.08779.pdf
使用一维CNN的端到端环境声音分类模型
加拿大的一组研究人员最近提出了一个端到端的一维CNN环境声音分类模型。根据音频信号的长度,该模型由3-5个卷积层组成。与许多传统方法实现二维表示的传统模型不同,这一模型是直接从音频波形中学习分类器。
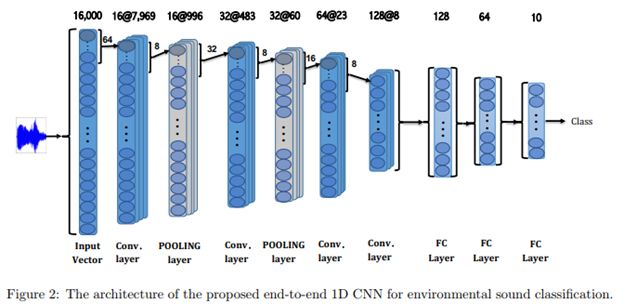
在对包含8732个音频样本的数据集进行评估时,新方法演示了几种相关的分类器表示,其结果超越了现有的基于二维实例和二维CNN的最优效果。
此外,在环境声音分类方面,该模型比大多数其他CNN体系结构的参数都要少,与传统的二维体系结构相比,平均精度要高出11%到27%。
潜在应用及效果
根据这篇论文的评价结果,该方法在提供高度鲁棒的环境声音分类应用上具有很好的应用前景。
对于初学者来说,它的效率很高,与传统的2D CNN相比,它只需要很少的训练数据(后者需要数百万个训练参数)。它还实现了最先进的性能,可以通过实现滑动窗口处理任意长度的音频信号。最后,它紧凑的体系结构大大降低了计算成本。
原文:
https://arxiv.org/abs/1904.08990v1
基于深度学习的面部表情识别研究
研究人员最近开发和训练了一种基于面部表情识别的CNN,并探讨了其分类机制。这一方法采用反卷积可视化方法,将CNN的极值点投影回原始图像的像素空间。他们还设计了距离函数来测量面部特征单元的存在与CNN特征图上最大响应值之间的距离。
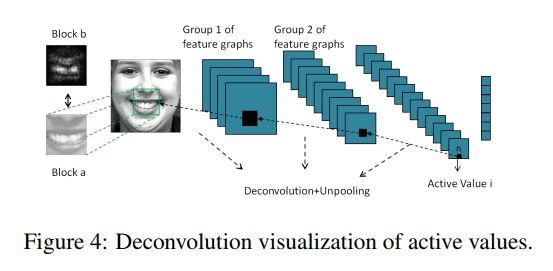
CNN特征图是通过比较特征图中所有面部特征元素的最大距离和面部特征元素之间的映射关系来确定的,如果距离较大,则对面部特征变得敏感。在训练过程中,研究人员验证了该方法对人脸动作单元的检测能力,实现了人脸表情识别。
潜在应用及效果
面部表情识别是测试任何内容、产品或服务的最佳方法之一,这些内容、产品或服务可能引起情绪唤醒和面部反应,因此,该方法可以应用于即时检测面部表情、编码面部表情和识别情绪状态。
包括消费者神经科学、神经营销、多媒体广告、心理学研究、临床心理学、心理治疗、人工社会代理(avatar)工程在内的许多应用都可以从研究中受益匪浅。
原文:
https://arxiv.org/abs/1904.09737v1
机器学习在网络安全上的应用 – 当今问题,挑战和数据集
新发布的研究提出了一些机器学习的挑战,研究人员需要处理这些挑战才能成功地将机器学习应用于网络安全。
其中一个重要问题是对恶意软件的分类和检测。识别恶意程序并不容易,因为攻击者常常会使用多态,模拟,压缩和混淆来逃避检测。不仅如此,一些其他同样严峻的问题也引起了广泛担忧,比如说该领域专家过少,导致标记样本不够,大量标签错误,数据集不平衡,识别恶意来源非常困难等等。
获取数据集:由于解决网络安全问题的一个主要障碍是缺乏适当的数据集,研究人员提供了获得数据集的途径,使学术界能够调查问题并提出应对挑战的方法。他们还提出了一种通过旋转生成标签的方法,为网络安全中缺乏标签的常见问题提供了解决方案。
潜在应用及效果
研究人员认为,机器学习在网络安全中的应用可以提升。他们还认为,网络社区有责任帮助机器学习社区在这一领域变得更加活跃。
目前,我们还是缺乏足够合格且经验丰富的网络安全分析师来最大限度地减少全球网络攻击。
为了获得对可用数据集的访问权限,研究人员只需要联系data-sets@paloaltonetworks.com并附上“访问数据请求”。
原文:
https://arxiv.org/abs/1812.07858v3
用于连续图分类的新模型
ML学者提出了一种简单、灵活但功能强大的方法来处理ML中的图,该方法使用扩展的持久性图来实现高效的图结构编码。具体来说,这一方法在计算扩展持久性图中使用热核特征以快速、有效地进行图结构总结。
此外,他们建立在最近的神经网络点云结构之上定义了扩展持久性图的架构,该架构集成性强且易于使用。
他们通过在几个图形数据集上验证它证明了新方法的有效性。虽然所提出的架构比其对应的架构简单得多,但结果表明它可以在几个图形分类任务上实现最先进的结果。
潜在应用及效果
这对于许多真实世界的图表分类数据集来说确实是个好消息,例如网络链接数据,社交网络,分子结构,地理地图等。此外,该架构对非结构化数据非常有用,包括用于进一步分析所可能需要的图像和文本图形表格建模。
原文:
https://arxiv.org/abs/1904.09378v1
其他爆款论文
一种新的基于深度学习的模型证明了它对去噪数据的有用性,并允许从噪声数据中精确逼近导数。
https://arxiv.org/pdf/1904.09406v1.pdf
BERT令人惊讶的跨语言效果。
https://arxiv.org/abs/1904.09077v1
一种简单,易于实现但有效的方法,不需要进行广泛的重新训练,并且可以跨域进行良好的泛化,以实现少数自然语言生成(NLG)。
https://arxiv.org/pdf/1904.09521v1.pdf
使用BERT生成文本的自动评估指标,可以更好地与人类判断相关联,并优于现有指标。
https://arxiv.org/abs/1904.09675v1
基于点云检索的上下文信息三维注意力图学习新模型。
https://arxiv.org/abs/1904.09793v1
AI新闻
AI能帮我们写出更好的法律吗?
https://www.forbes.com/sites/kalevleetaru/2019/04/24/could-ai-help-us-write-better-laws/#153d0ec95529
推荐算法主宰世界。
https://www.wired.com/story/how-recommendation-algorithms-run-the-world/
这个机器可以读心,也可以交谈
https://www.wired.com/story/machine-reads-your-mind-talks/
TensorFlow推出了MLIR来加快编译速度,简化机器学习模型的硬件优化。
https://www.infoworld.com/article/3390659/tensorflow-unveils-mlir-for-faster-machine-learning.html
2019-2025医疗保健应用全球人工智能市场报告。
https://www.marketwatch.com/press-release/artificial-intelligence-for-healthcare-applications-market-2019-global-trends-size-share-status-swot-analysis-and-forecast-to-2025-2019-04-24?mod=mw_quote_news

Christopher Dossman是Wonder Technologies的首席数据科学家,在北京生活5年。他是深度学习系统部署方面的专家,在开发新的AI产品方面拥有丰富的经验。除了卓越的工程经验,他还教授了1000名学生了解深度学习基础。
LinkedIn:
https://www.linkedin.com/in/christopherdossman/
志愿者介绍
后台回复“志愿者”加入我们