新任务&数据集:视觉常识推理(VCR)
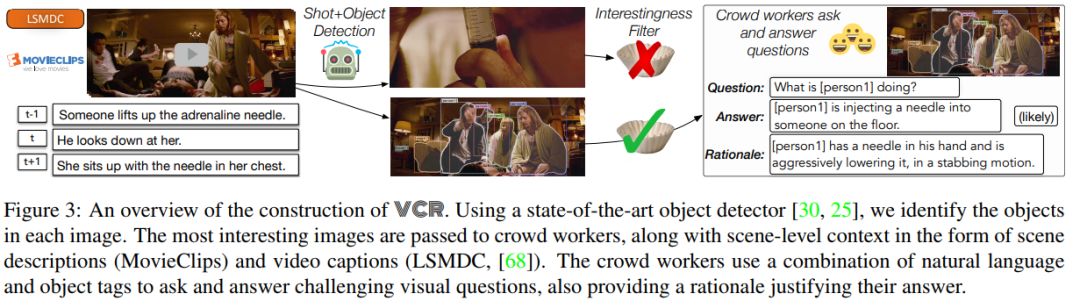
【导读】视觉理解远远超出了对象识别。只需一瞥图像,我们就可以毫不费力地想象超出像素的世界:例如,我们可以推断人们的行为,目标和心理状态。虽然这项任务对于人类来说很容易,但对于今天的视觉系统来说,这是非常困难的,需要更高阶的认知和关于世界的常识推理。在近期华盛顿大学和AI2推出的一篇论文中,将此任务形式化为Visual Commonsense Reasoning。除了回答用自然语言表达的具有挑战性的视觉问题之外,模型必须解释为什么做出这样的回答。我们引入了一个新的数据集VCR,它包含源自110k电影场景的290k多项选择问题。大规模生成非平凡和高质量问题的关键方法是对抗性匹配,这是一种将丰富注释转换为具有最小偏差的多项选择题的新方法。为了实现认知水平的图像理解,我们提出了一种新的推理引擎,称为识别网络识别(R2C),它为接地,情境化和推理建立必要的分层推理。实验结果表明,虽然人类发现VCR很容易(准确度超过90%),但最先进的模型仍然很困难(约45%)。我们的R2C有助于缩小这一差距(约65%);仍然,挑战远未解决,我们提供分析,为未来的工作提供了途径。


论文链接:
https://arxiv.org/abs/1811.10830
网站地址:
http://visualcommonsense.com/
-END-
专 · 知
人工智能领域26个主题知识资料全集获取与加入专知人工智能服务群: 欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

PC登录www.zhuanzhi.ai或者点击阅读原文,可以获取更多AI知识资料!

加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)可以其他同行一起交流~ 请加专知小助手微信(扫一扫如下二维码添加),

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知


