引入Powerball 与动量技术,新SGD优化算法收敛速度与泛化效果双提升 | IJCAI


论文地址: https://www.ijcai.org/Proceedings/2020/0451.pdf
开源地址:https://github.com/HAIRLAB/pbSGD
前言
在这篇论文中,我们提出了一种新的基于SGD的优化方法(pbSGD)用于训练神经网络。
具体而言,基于[1]中作者提出的在梯度下降法中应用Powerball函数的基本思想,本文将其推广到了SGD的情形,得到了一类简单且通用的改善深度神经网络训练效率的方法。在pbSGD中,Powerball函数作用于SGD中的随机梯度项,其作用机制与[1]中一致。该方法在迭代过程中对随机梯度做了简单的幂函数变换改善了SGD方法的性能,通过只引入一个额外的超参数即幂指数项。我们进一步提出了结合动量(momentum)的pbSGD,即pbSGDM,并给出了两种方法的收敛性理论分析。
实验表明,提出的pbSGD和pdSGDM方法,可以实现与其他自适应梯度方法相比更快的收敛速度,以及与SGD方法的相近的泛化效果,同时该方法可以保持[1]中方法的优点,主要包括在初始迭代时的训练加速、算法性能对超参数的鲁棒性,以及有效地改善梯度消失问题。
研究背景
随机优化是深度学习研究中非常重要的一环。基于SGD方法,近些年提出了许多其他能有效训练深度神经网络的优化方法,例如结合动量的SGD方法(SGD with Momentum,SGDM)、RMSProp和Adam等。自适应算法(比如AdaGrad、RMSProp、Adam)通常在前期可以获得较好的收敛性能,然而最近研究表明自适应算法在优化中容易收敛到局部极小值,在测试集上泛化性能较差。因此许多计算机视觉与自然语言处理方面的研究仍然采用SGD用于训练网络。另一方面,相比于自适应方法SGD在收敛速度方面有所欠缺。因此,如何使得SGD可以在非凸条件下有效逃离鞍点并取得更好的收敛效果成为了热点研究领域。
针对SGD的设计思路目前主要有两种:动量法和自适应学习率。SGDM从物理角度出发引入了一个动量项,并在实际应用中取得了比SGD更快的收敛效果,动量可以看作是指数滑动平均的一个特例。自适应算法通常采用自适应学习率的思路,通过积累历史的二阶与一阶梯度信息来动态修改学习率,最早应用于AdaGrad方法中,Adam结合了AdaGrad与RMSProp算法成为目前最为常用的优化器之一。
与目前的主流思路(自适应学习率或者动量法)不同,我们提出了一种新方法,采用Powerball函数对梯度项作非线性变换来改善SGD在非凸情况下的表现,即pbSGD方法。本文的主要贡献如下所示:
我们基于SGD提出了一种简单易用的优化方法pbSGD,给出结合了动量的pbSGD变体即pbSGDM。
我们在多种数据集与任务上进行了详尽的实验对比,实验结果表明本文提出的方法能在训练前期取得比自适应算法更好的收敛速度,同时在测试集上与SGD和SGDM的泛化效果相近。
我们提供了在非凸条件下pbSGD和pbSGDM的收敛速度的理论分析。
算法介绍
我们这里给出所提两种算法的思路和推导,其中pbSGD把Powerball优化方法和传统的随机梯度下降法相结合,pbSGDM是pbSGD引入动量项以后的延伸。
1、pbSGD
训练一个含有n个自由参数的DNN网络,可以被建模为一个无约束的优化问题:
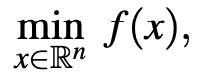
这里f是一个有下界的函数,SGD已经被证明是高维优化问题的一个有效且高效的求解方法。它通过迭代地更新参数向量对f进行了优化,这个更新是朝着随机梯度g的反方向进行的。这里的随机梯度是通过训练数据集的第t个小批次计算而来。SGD的参数更新策略如下所示:
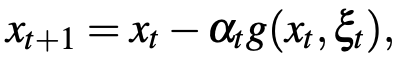
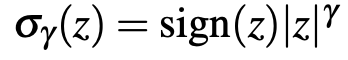
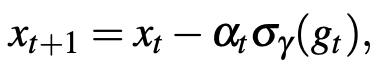
2、pbSGDM
动量技术是从物理过程中获取的灵感,已将其成功地应用于SGDM,并在大多数情况下可以获得神经网络的更佳训练结果。我们这里同样提出pbSGD的动量加速形式,即pbSGDM,其参数更新规则为:
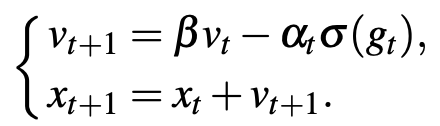

实验对比
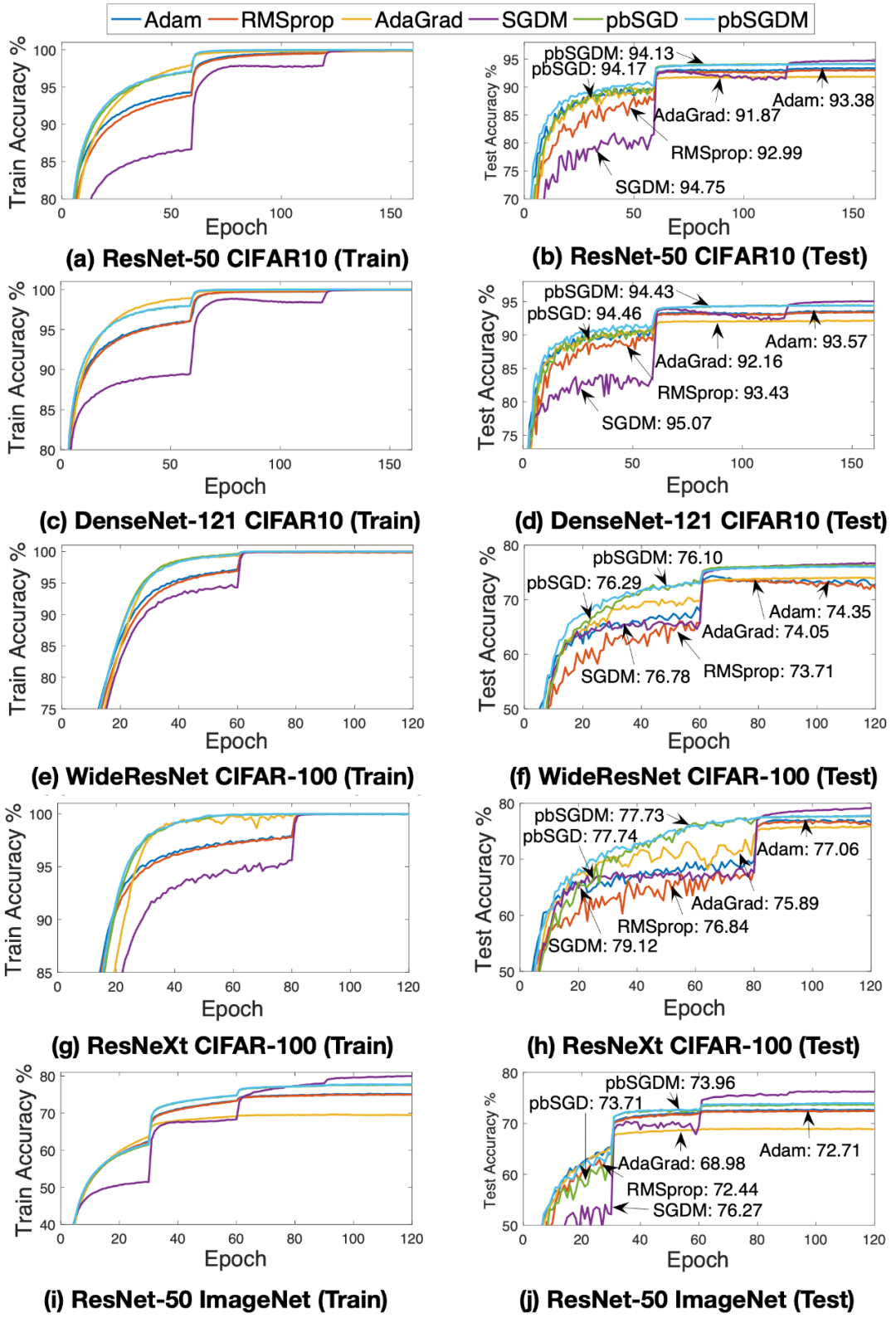
在三个公开数据集CIFAR-10、CIFAR-100和ImageNet上,我们分别使用了几种不同的模型来比较算法的收敛速度和泛化效果,其中CIFAR-10用于训练模型ResNet-50和DenseNet-121、CIFAR-100用于训练ResNet-29和WideResNet、ImageNet用于训练ResNet-50。另外我们构建了一个13层的全连接神经网络来验证pbSGD缓解梯度消失的能力。
1、收敛和泛化对比实验
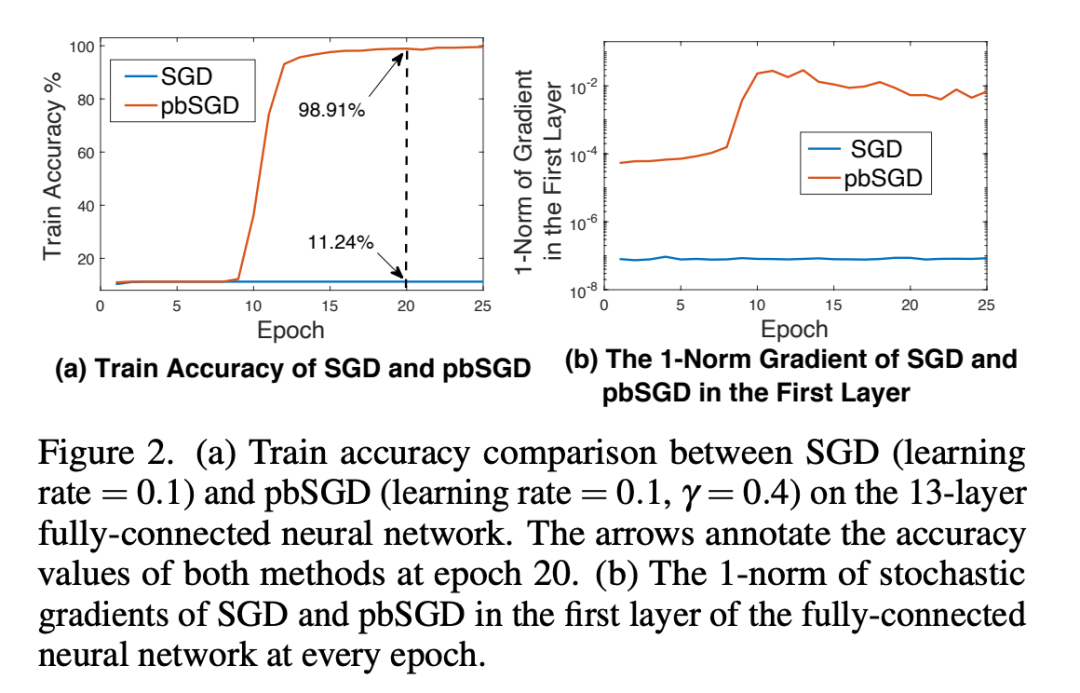
2、梯度消失
Powerball函数的引入重新缩放了梯度向量,因此在深度神经网络中还可以缓解梯度消失的问题。我们设计了一个13层的全连接网络,激活函数选择为ReLU,分别使用SGD和pbSGD来训练,学习率仍然采用网格搜索选取。通过实验我们发现SGD无法训练该网络结构,而pbSGD在缩放梯度向量后可以正常训练模型。
3、鲁棒性改善
在实验中我们发现,超参数gamma的引入不仅可以加速收敛,同时可以改善对测试集准确率和收敛性的鲁棒性。(gamma=1.0时pbSGD变为了SGD算法)
1)改善学习率对准确率的鲁棒性
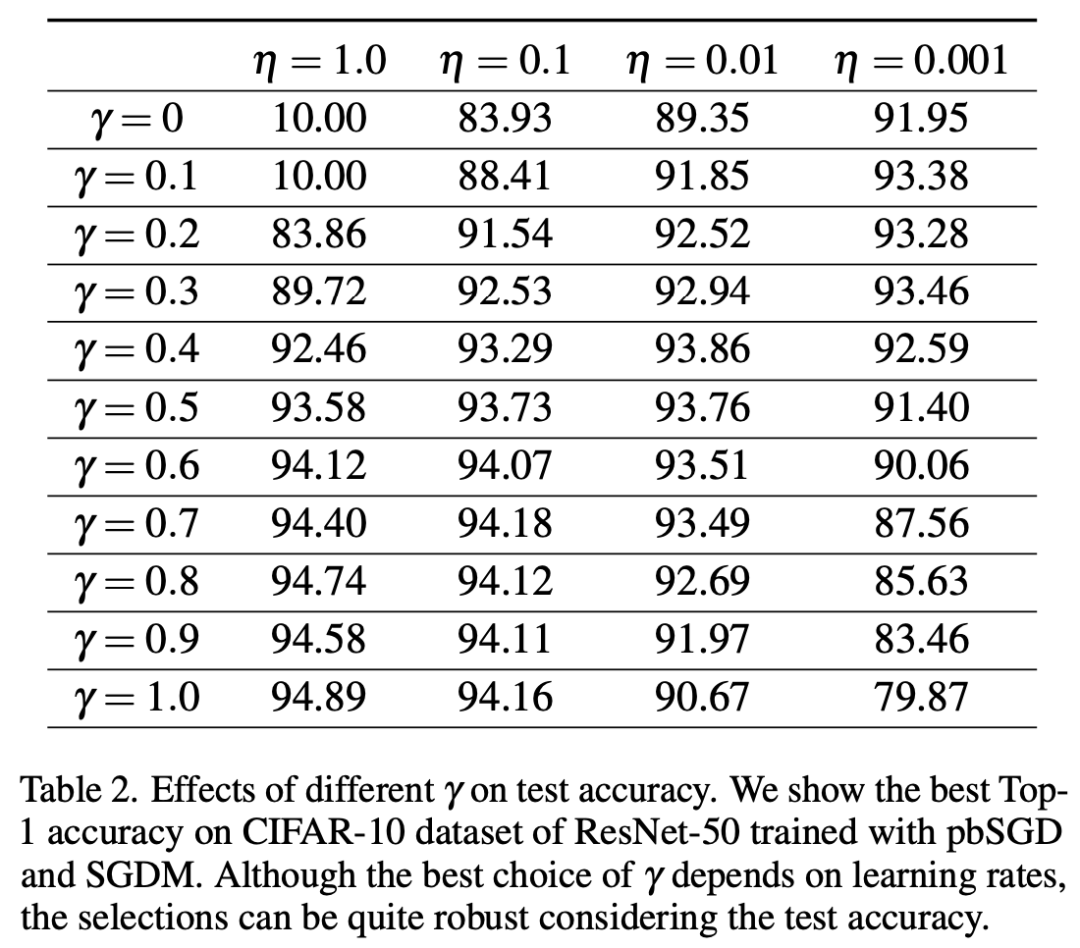
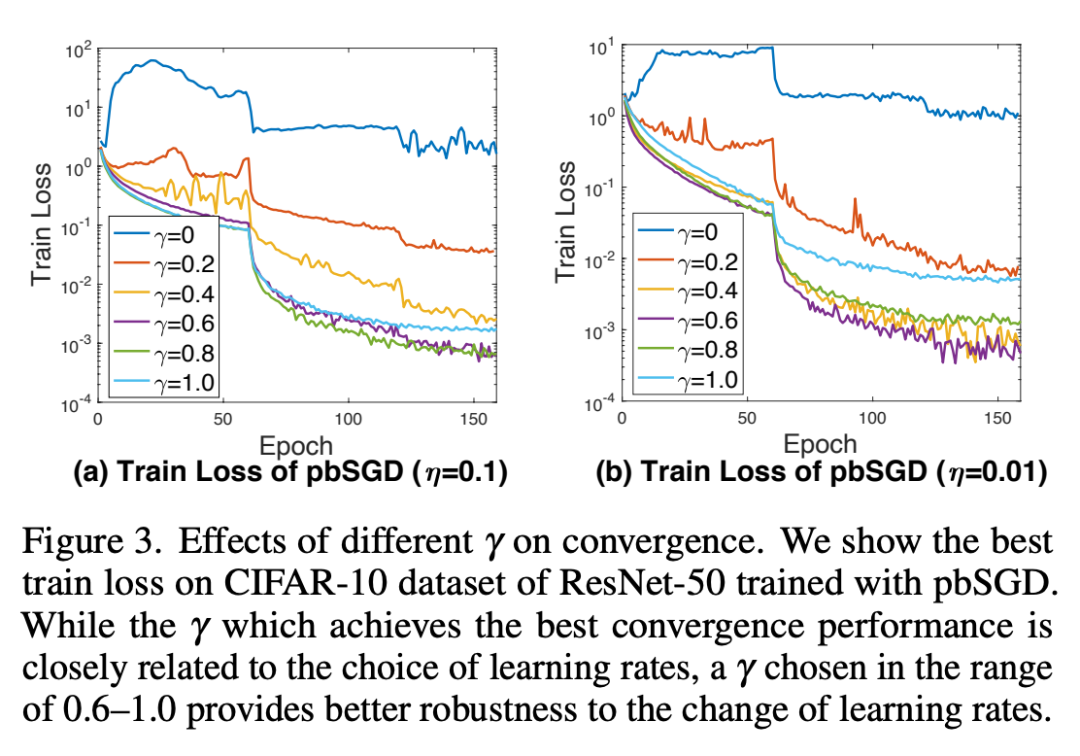
2)改善学习率对收敛的鲁棒性
超参数gamma同样可以改善学习率对收敛的鲁棒性,在学习率设置的不太合适时pbSGD仍然能取得较好的收敛表现。
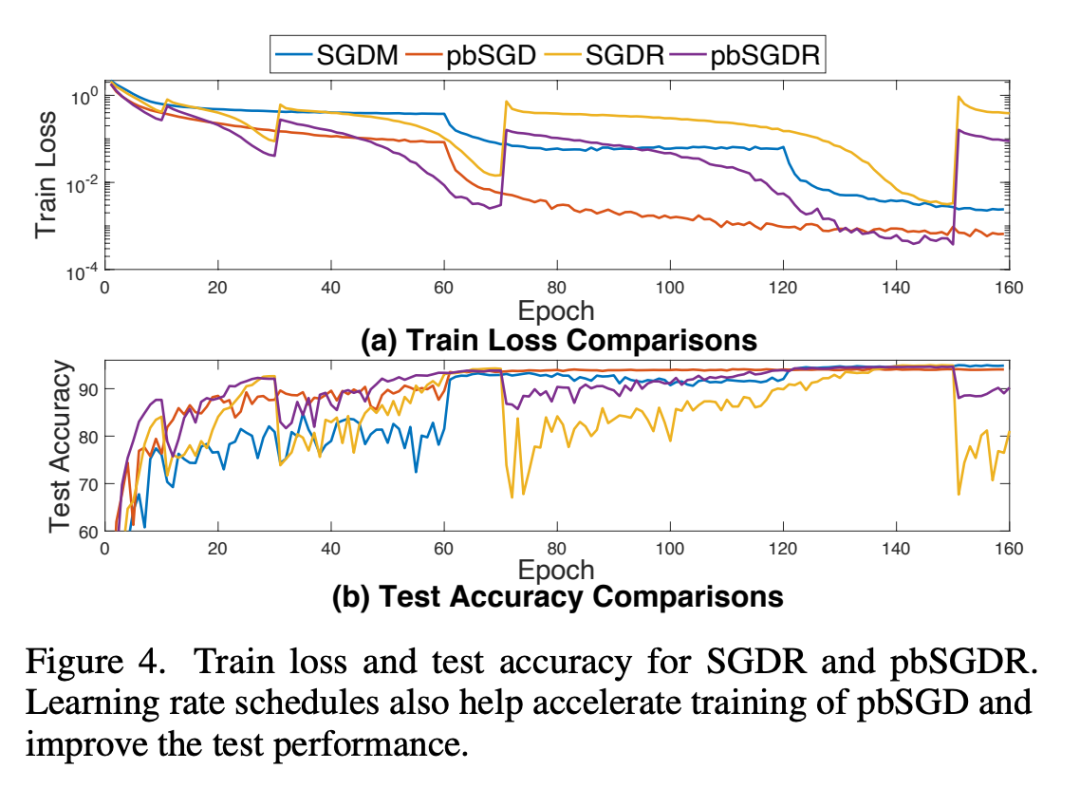
4、与学习率策略相结合
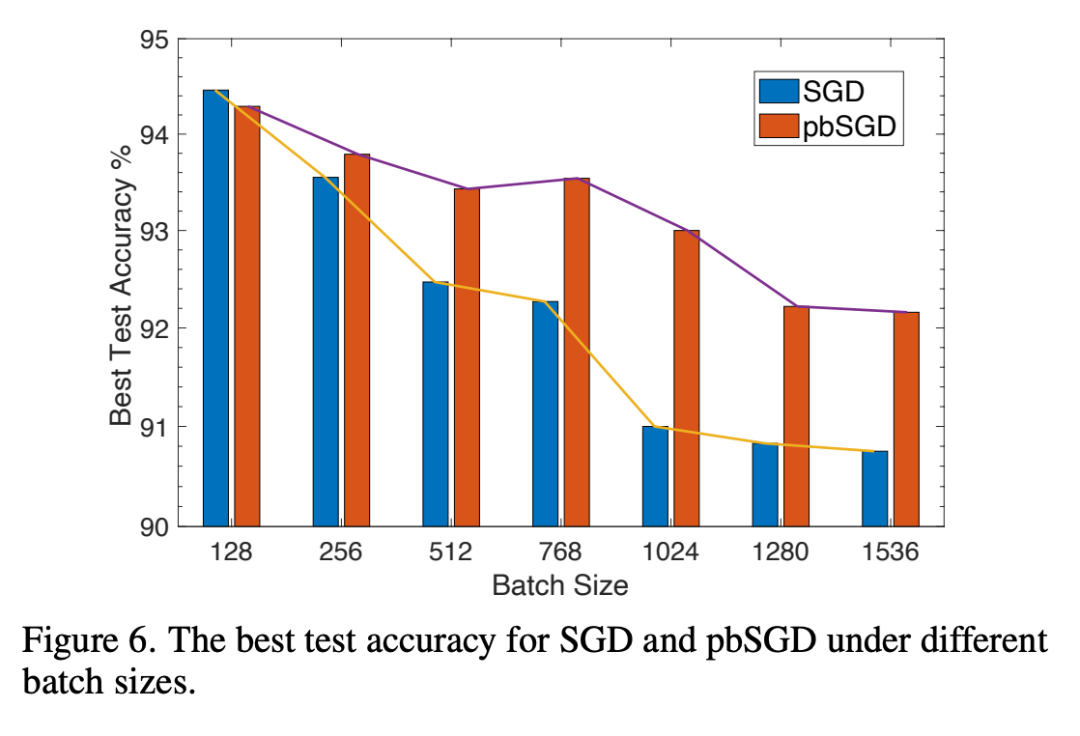
5、对batch size的鲁棒性
总结
AI 科技评论希望能够招聘 科技编辑/记者
办公地点:北京/深圳
职务:以跟踪学术热点、人物专访为主
工作内容:
1、关注学术领域热点事件,并及时跟踪报道;
2、采访人工智能领域学者或研发人员;
3、参加各种人工智能学术会议,并做会议内容报道。
要求:
1、热爱人工智能学术研究内容,擅长与学者或企业工程人员打交道;
2、有一定的理工科背景,对人工智能技术有所了解者更佳;
3、英语能力强(工作内容涉及大量英文资料);
4、学习能力强,对人工智能前沿技术有一定的了解,并能够逐渐形成自己的观点。




