AI综述专栏 | 目标检测简明综述
本文是对目标检测领域的一个简洁明了的综述,意在使读者可以快速浏览并获取object detection领域的重要发展历程和最新进展。
一
Detection简介
目标检测的任务是找出图像中所有感兴趣的目标(物体),确定它们的位置和大小,是机器视觉领域的核心问题之一。由于各类物体有不同的外观,形状,姿态,加上成像时光照,遮挡等因素的干扰,目标检测一直是机器视觉领域最具有挑战性的问题。下面是一张图像的人脸检测结果。

二
面临的挑战
准确率:如何使定位更准
实时性:计算复杂度高,不适合试试计算,如何使速度更快。
三
检测方法
(一)two-stage 两步走的框架
先进行region proposal(selective proposal,region proposal network等,找出可能是目标区域的bbox),再进行目标分类,和bbox回归
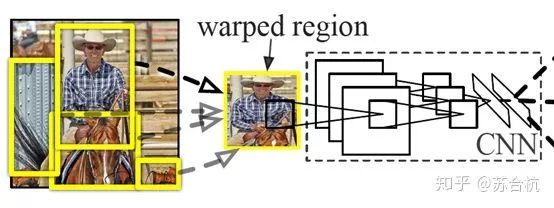
1、传统算法
Viola和Jones于2001年提出的VJ框架,使用滑动窗口 + ( 计算Haar特征 + Adaboost )
Adaboost (adaptive boosting自适应提升算法,1995年提出), OpenCV adaboost使用滑动窗口+图像金字塔生成region proposal
用多个分类器合作完成对候选框的分类,这些分类器组成一个流水线,对滑动窗口中的候选框图像进行判定,确定它是人脸还是非人脸。
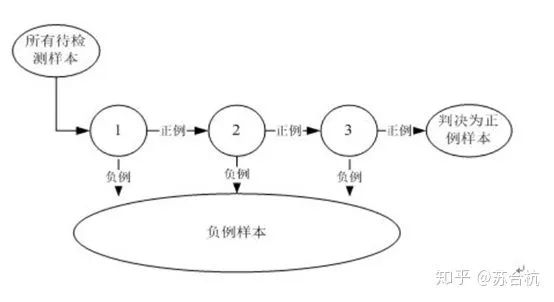
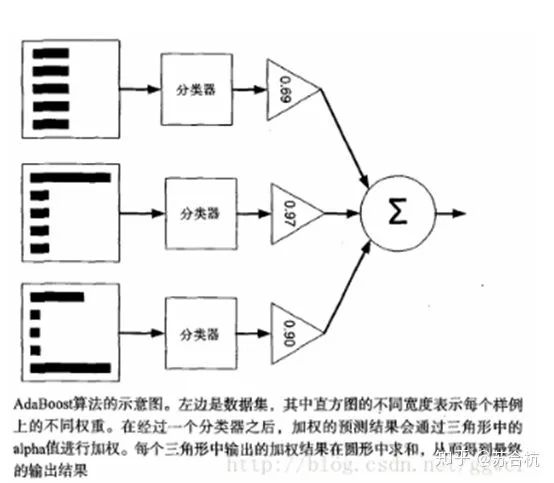
adaboost强分类器:
Adaboost的原理是,多个分类器组合在一起分类loss的上限,是各个分类器误差之积的函数。
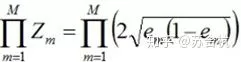
括号内的数值<1, 这样随着分类器的增加,loss的上限不断被压缩,到最后趋近于0

优点:而且弱分类器构造极其简单; 可以将不同的分类算法作为弱分类器,集成学习后作为1个强分类器。
缺点:训练时间长,执行效果依赖于弱分类器的选择(如果弱分类器每次误差都在0.5附近,类似于瞎猜,这时loss值很难下降,需要迭代很多次)
2、深度学习(CNN-Based)
VJ是2001年提出来的,此后业界也没有多少进展。2012年AlexNet在ImageNet举办的ILSVRC中大放异彩,此后人们就开始尝试将卷积引入cv的各种任务里面。我们看到Adaboost分类器的输入是haar特征,这个特征是按照明确的规则,显式提取出来的。
有了CNN后,我们可以将特征提取交给卷积神经网络完成。
14年uc berkerly的Girshick提出了rcnn算法,第一次将cnn引入detection领域,开启了检测领域1片新的天地。

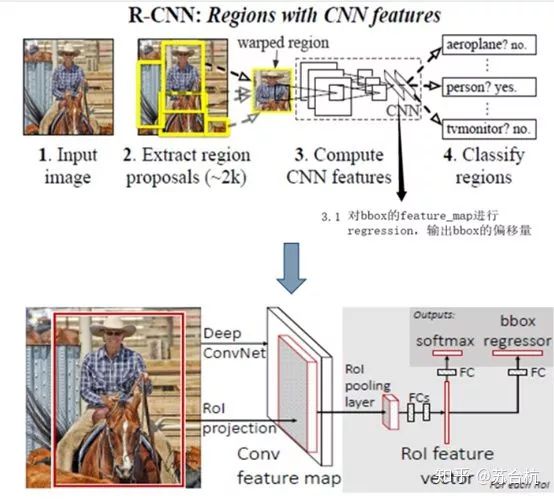
(1)RCNN
网络结构如图所示,先用selective search进行region box的选择,选完后送入backbone,进行回归和分类。
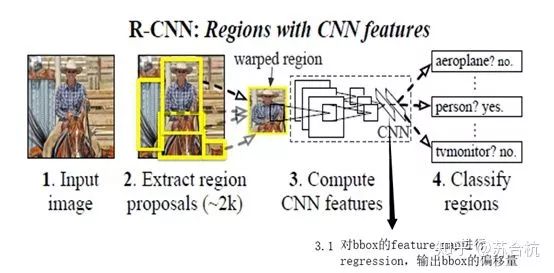
首先介绍一下selective search的原理
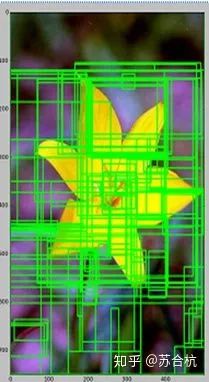
用selective search找到proposal,即比较可能是物体的一个区域
我们首先将每个像素作为一组。然后,计算每一组的纹理,并将两个最接近的组结合起来。我们首先对较小的组进行分组。我们继续合并区域,直到所有区域都结合在一起。
下图第一行展示了如何使区域增长,第二行中的蓝色矩形代表合并过程中所有可能的 ROI。

具体过程如下:
a.用selective search找到proposal,即比较可能是物体的一个区域
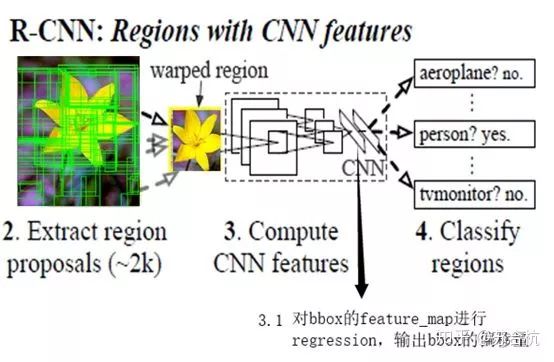
b.特征提取
对每个候选区域,使用深度卷积网络提取特征 (CNN),这里的基础网络backbone采用VGG,将输入图片传入VGG,经过卷积, 池化, 全连接提取特征,得到4096维特征。
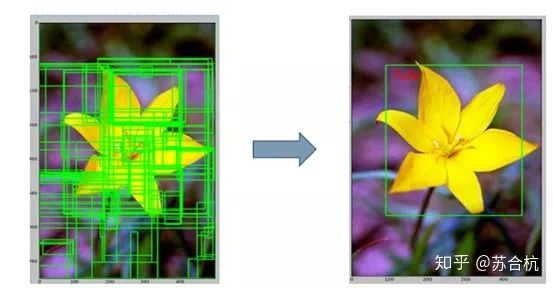
c.学习bbox regression回归
利用卷积网络计算bbox位置修正信息,detection面临的一个问题是带标记的数据少,当时可用的公开数据集不足以训练大型CNN来计算bbox位置修正,paper中提出以VGG网络中参数为基础,用PASCAL VOC 2007数据集,在原网络基础上bbox regression训练
(以VGG现成的参数为基础训练regression,这种思想类似于迁移学习, PASCAL VOC 2007数据集,每张图片中,带有物体的类别和位置,如下图所示)

d.类别判断
利用多个svm分类器(object的种类+1),判别区域属于哪个特征,或者是background。
e.输出结果
Regression部分训练完毕后,输入由ss提出的区域,输出修正候选框位置。结合cls信息做NMS,最后输出detection结果。
RCNN是将cnn引入到目标检测领域的开山之作,预测精度相比VJ的haar+adaboost框架,map从40%提高到60%,但也存在不足。
RCNN网络的不足:
产生大量的region proposals ,它为每个bbox对应的区域进行卷积神经网络正向传递,计算量巨大。很难达到实时目标检测(1张图片的计算要50S)
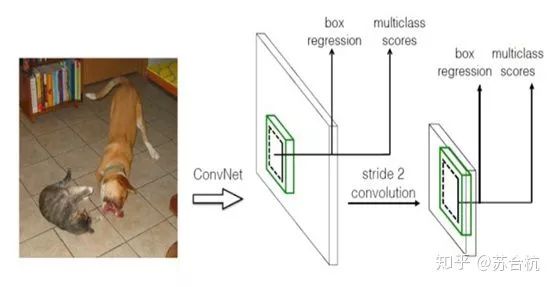
(2)Fast-RCNN
针对rcnn存在的问题,Ross Girshick相应的提出了fast-rcnn网络。
R-CNN把一张图像分解成大量的bbox,每个bbox拉伸形成的图像都会单独通过CNN提取特征. 实际上这些bbox之间大量重叠,特征值之间完全可以共享,rcnn那种运算方式造成了计算的浪费.
Fast-RCNN,只送1张图片进卷积,运算量大大减少。
最后一层卷积层后加了一个ROI (region of interset)池化层。这个层可以将所有的bbox,映射到的feature maps的相应位置,并输出1个固定尺寸的特征图(论文中以7*7为例)
相比于RCNN,减少大量的计算。
RCNN网络中,cls和bbox regression分2步进行(SVM + cnn)
fast-rcnn将边框回归直接加入到CNN网络中,损失函数使用了多任务损失函数(multi-task loss),和cls融合到一起训练。更简练。
(3)Faster-RCNN
Fast-rcnn相比于rcnn在bbox的生成上快了25倍,但是用selective search生成bbox还是很费时间
16年亚研院的任少卿与kaiming he联合Girshick提出来faster-rcnn结构(任少卿和kaiming he 5年还联合提出了resnet)
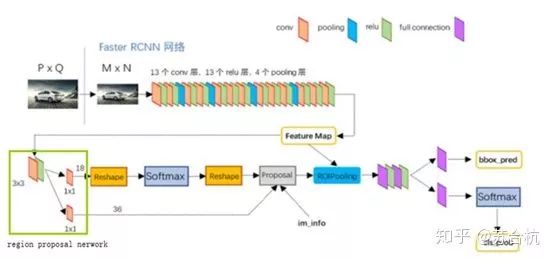
FASTER-RCNN引入1个小型网络rpn(region proposal network)
利用已经生成好的feature map,来产生更少,更精准的bbox
(rcnn 和fast-rcnn用selective search产生的Region Proposal有2000个,FASTER-RCNN产生的Region Proposal有300个)
下面我们来了解下RPN的工作原理
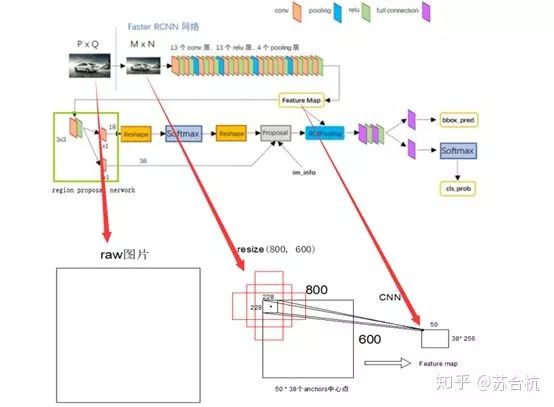
Backbone以vgg16为例,原始图resize成800*600,经过VGG,输出特征图50*38*256,每张图Feature map上1个点,对应的感受野为228 * 228,以这个感受野的中心为锚点,生成9个固定尺寸(128^2, 256^2,512^2)的bbox(例图只画了3个示意)
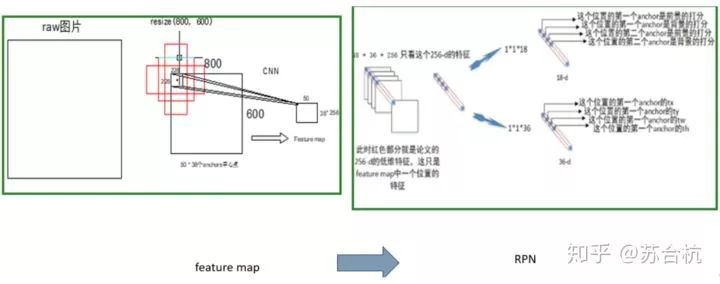
a.将feature map上的1个像素点的256channels信息,送入RPN的cls和bbox regression网络,计算cls和bbox位置修正。(此时,input是228 * 228的感受野,此感受野是9个anchor的共有区域,以此为输入,预测9个anchor代表区域的cls和bbox regression)
b.此时一张图上有50*38 = 1900个anchor,每个anchor有9个同心的bbox,初始产生17100个bbox,对图像提取(取cls score最大的300个)Region Proposal
anchor确定的9个区域的cls标签,由其与Ground Truth的IOU确定,Bbox标签,由Ground Truth确定。
以上面2个数据为基础,训练RPN
Resized image中的一个cell是228*228区域,过rpn网络后生成9个anchor的cls和回归结果。
但是我们观察网络,输入信息为原来图上228*228大小的区域,anchor的覆盖的区域包含感受野外的部分,那么一个有限的输入,如何对其外部的anchor做出cls和回归呢?
通过源码和论文,作者实现的过程如下图右面部分所示:
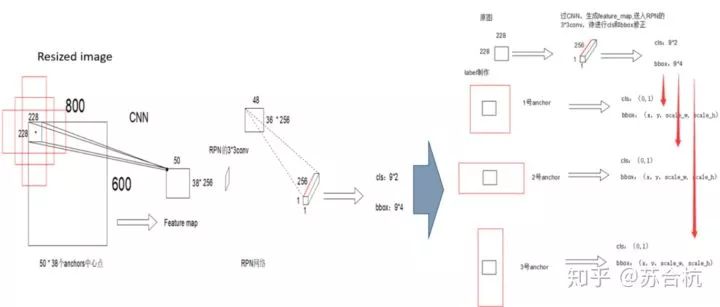
输入的256Dtensor对于原图中的228*228区域,在制作label的时候,计算好各个感受野对应的9个anchor,算好每个anchor对应的cls和回归值。
通过神经网络,让228*228去拟合9个anchor的cls和回归信息,以此实现对9个区域的预测。(做label告诉网络去预测什么)
通过训练过程强制拟合,深度学习可以逼近任意拟合函数(深度学习黑盒所在)
对这3种Region Proposal的方法,可以做下面一个小游戏来说明
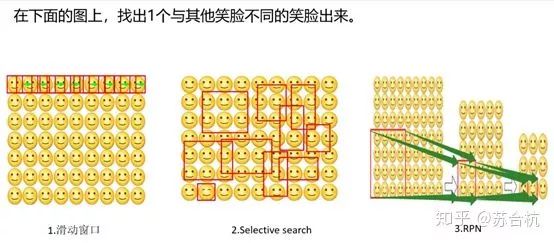
1.滑动窗口 ,遍历图像进行查找。
2.过滤掉很多子区域,大大提升效率。
3.RPN算法(将图片一层层在自己的脑海中进行融合缩小,最后在一张浓缩的小图上快速定位了目标)
RCNN系列总结
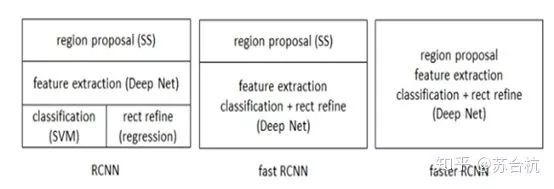
RCNN:首次将CNN引入目标检测,准确率获得大幅提升。
Fast-RCNN:因为加入了ROI (region of interset)pooling layer,完成了各bbox到feature map的映射,输入整张图片进卷积,运算量大大减少。同时将cls和bbox regression join在一起训练。
Fastern-rcnn:就是将ss换成了rpn,运算复杂度降低。
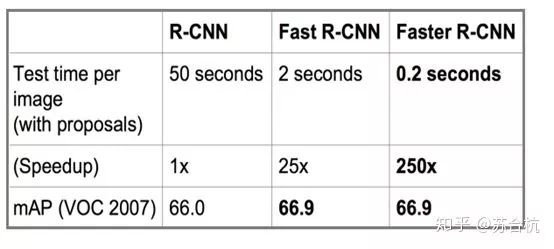
单张pic的处理时间,可以看出运行时间得到明显提高。
一点感想:
1.数据集不够时,先进行数据增强,如果数据集还是太少,可以拿现成的,性能比较好的网络,以此为基础进行训练(类似于迁移学习的思想),会获得较好的score
2.Join训练,fast_cnn将cls和bbox回归join在一起训练,score提高,mtcnn将cls,bbox和alignmen join在一起,score提高,faster-rcnn之后,何凯铭又提出mask-rcnn,在Faster-RCNN 的基础上添加一个分支网络做segmentation,在实现目标检测的同时,把目标像素分割出来。这样loss在cls + bbox 基础上,又加了个分割的loss,性能进一步获得提升。
(二)one-stage
1、YOLO(CVPR2016)
单步法,将之前Selective search或RPN省略,直接在截图上进行cls和bbox regression
1.YOLO的backbone参考GoogleNet
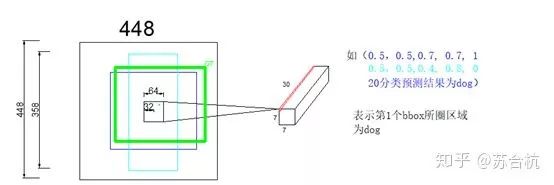
测试图片resize之后,进入backbone,产生1个7*7*1024的feature map, 这个上面的一共有49个1*1*1024的tensor,每1个tensor对应resized image上面一个区域。将这个feature map过全连接,输出7*7*30的output,每个1*1*30的tensor,就对应resized image上面1个grid cell
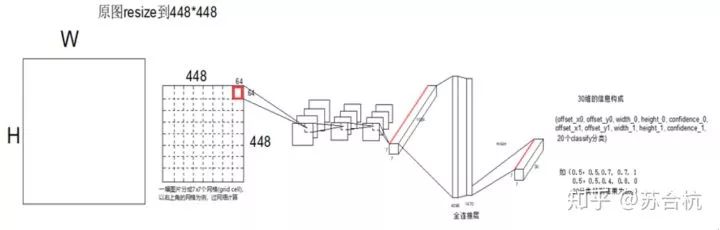
1.这个1*1*30的tensor,表示生成的2个bbox信息,如图左上角比较细的蓝色框框,和青色框框
Offset指的是bbox中心点,相对于感受野尺寸左上角点的偏移值 / receptive field的比值, width,height是bbox高宽 / 原始图片高宽的比值。
2.confidence代表了,当前grid cell含有object的可能性(0,或者1),有object的话,bbox与GT的IOU是多少,两重信息,由possibility * iou计算得来
比如说output第2行,青色的5维信息,对应左图中青色的bbox,其中心点相对于grid cell左上角的Offset是32, receptive field的size64,所以第一个参数是0.5
这里我们观察一下label的维度维25维,与yolo输出的shape不同,那么loss应该怎么计算?,怎样让网络去拟合label里面的数据?
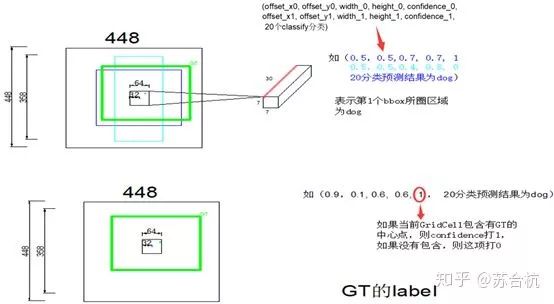
实际采用的方法是,预测的2个bbox,只取IOU较大的那个计算。
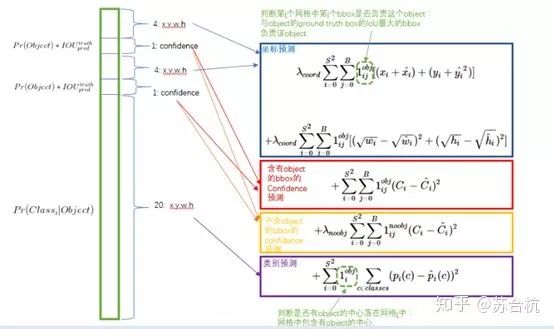
1.这里可以看出来,对于bbox的预测,如果grid cell,里面有object,那么示性函数为1,计入此项的loss(如果2个bbox中心点都在有object的grid cell里面,则取IOU较大的那个bbox,计算loss),如果grid cell没有object,那么示性函数为1则bbox的loss就不用叠加到总的loss上了。(ij表示第i个grid cell里面的第j个bbox)
2,3项根据grid cell里面含不含object,只计算1个,在这里计算第5维confidence的损失。
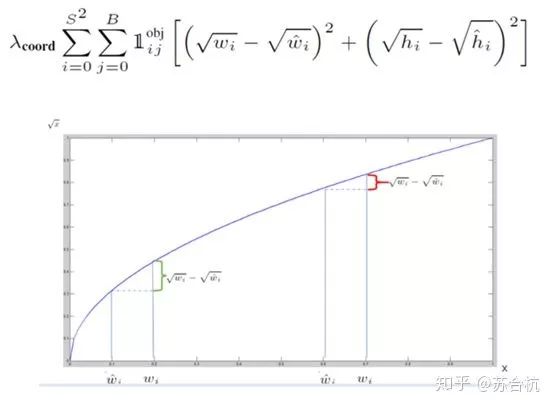
4,计算分类的loss。算bbox的loss时,用了(x^(0.5) – x’(0.5))^2,因为GT里面是10,预测结果是20,跟Gt是100,预测结果是110,虽然差值都是10,但是精准程度显然不一样。引入这种loss计算方法,前者的loss就比后者要大
直接输出的5维信息里面有bbox和confidence信息,但是confidence信息是对bbox所属区域,先计算有没有object的possibility,再计算IOU后得来的,我们看到图上同时输出了bbox和confidence的结果,这是如何做到的呢?
网络采用预训练模型,用ImageNet1000分类数据集Pretrain卷积层,训练完成后,将Pretrain卷积层,加4层conv,和2层fc,组成backbone,直接对输入图像做回归
,输出bbox和的cls计算结果(拟合label里面bbox,和label里面根据bbox计算的confidence)
特点:
a1. 因为没有复杂的检测流程,YOLO将目标检测重建为一个单一的回归问题,从图像像素直接到边界框坐标和分类概率,而且只预测49*2个bbox,运算速度超级快,YOLO在Titan X 的 GPU 上能达到45 FPS
a2. R-CNN看不到更大的上下文,在图像中会将背景块误检为目标。YOLO的feature map要会再过2个全连接层,这样最终的output能get到图像的整体信息,相比于region proposal等方法,有着更广阔的“视野”。YOLO的背景误检数量少了一半。
YOLO是直接预测的BBox位置,相比于预测物体的偏移量, 不太好收敛。虽然速度快,但是相对于faster-rcnn,检测精度较低。同时,由于每个grid cell只预测1个object,对于靠的近的物体的预测效果不好。。另外YOLO对小物体检测效果也不好,推测可能是因为Loss函数在设置中,offset误差是权重高,成为影响检测效果的主要原因,bbox的width和height的loss在总的loss中占比不大。
疑问:每个 1*1*30的维度对应原图7*7个cell中的一个,过完fc层之后,可以解决特征图上含有全局信息,但是过完全连接层,感受野就对不上了啊, 每个 1*1*30的维度对应原图7*7个cell中的一个
2、SSD( Single Shot MultiBox Detector )
Yolo对小物体的检测效果不好,我们发现,同样size的一个区域,把这个区域套到网络前部的feature map上,这个区域对应的感受野就比较小,正好用来检测小物体,而后部的feature map,这个区域对应的感受野比较大,用来检测大物体,由此思想提出了SSD算法
Single shot指明了SSD算法属于one-stage方法,MultiBox指明了SSD是多框预测,
他利用不同尺度的特征图来做检测
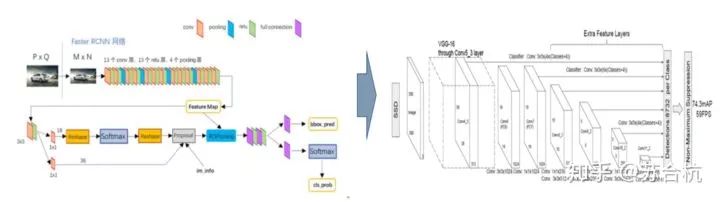
网络结构如下图所示,backbone为VGG16,第一张图是SSD的架构,第二张图是YOLO架构。
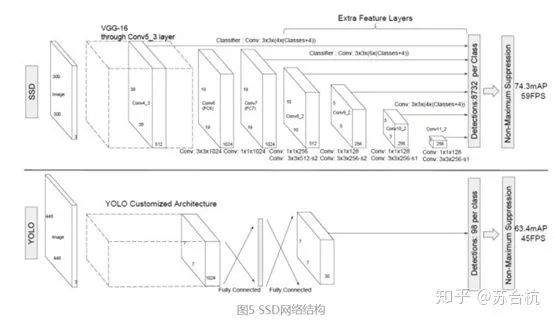
可以看到,SSD相比yolo,在back bone后面多了几个卷积层,多出来的几个卷积层,可以获得更多的特征图以用于检测
最后用了共提取了6个特征图,feature map的size是38*38, 19*19, 10*10, 5*5, 3*3, 1*1)
各个特征图的每一个cell,的感受野分别为30*30, 60*60, 111*111, 162*162, 213*213, 264*264
SSD将不同的特征图汇集在一起,来做检测任务
另一个改动是yolo一个cell上采用2个bbox,而SSD在每个cell上采用了不同尺度和长宽比的prior boxes(在Faster R-CNN中叫Anchors)
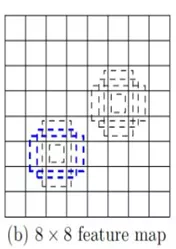
每1个prior bbox的面积,按照公式指定,各个feature map上对应的bbox的边长,线性增加,aspect ratio是(1, 2, 3, 0.5, 1/3,1’),最后1个1’是 以feature_map当前一个小格(cell)的感受野边长 * 与feature map上一个小格(cell)的感受野边长 ,开方后的数值为边长的bbox
以5*5的feature map为例,对feature map每个cell,生成6个bbox(第一层feature map和最后2层feature map生成4个bbox),计算回归和cls。
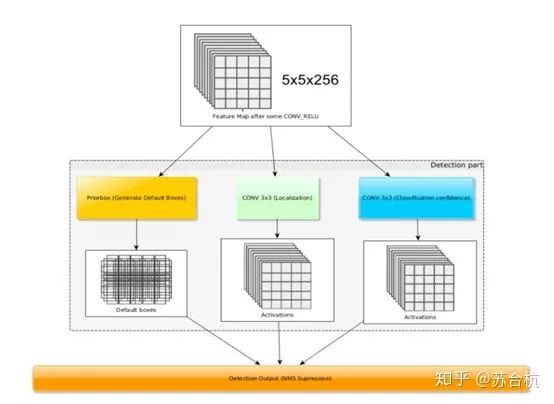
1个1*1*256的tensor,经过检测模块后最后输出这个cell对应原图上,6个prior box的回归和cls结果。
预测的时候跟faster-rcnn的region proposal network一样,也没有将bbox做输入进行cls,而是直接拿feature map的点进行计算。
训练:label的制作.
我们的网络,是想拟合什么样的数据?
数据集中给与的GT,如何转换为训练中可用的label,使之与每个prior box对应的predict结果相对应?
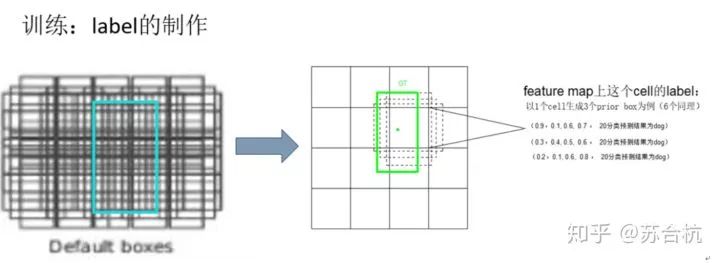
prior bbox的label的值(x, y, width, height),x,y是GT的中心点,相对于prior bbox的偏移/prior bbox的width,height。width, height指GT宽、高与prior bbox宽高之比的log值。
众多prior bbox,并不是每个bbox都做回归,做label时,将与GT的IOU高于threshold的bbox做如右图所示的标签,低于threshold的区域就不算了.
SSD是Faster-rcnn与Yolo的结合,其中Prior bbox提取的过程跟Anchor的设计理念极其相似。
那么为什么Faster-rcnn是two-stage,而SSD是one-stage?
因为faster-rcnn中rpn需要另行训练,而在SSD中直接预测bounding box的坐标和类别的object detection,没有生成proposal的过程, one-stage中完成。
四
最新进展
低层次的包含更多纹理的特征,高层次的包含更多上下文的特征,低层级特征被用于检测尺寸较小的人脸,高层级特征被用于检测尺寸较大的人脸。
FPN(特征金字塔网络)只聚合高级和低级输出层之间的层次结构要素图, 其实上两者之间有关联

前部feature map对应的感受野如上图所示,图分辨不出是人脸还是其他物体,但是随着feature map感受野的逐步扩大,后面的图像可以看到这个区域是人脸。将不同尺度的feature map联合在一起进行训练,会检测出第一张人脸出来。
(1)PyramidBox
百度18年3月份在WIDER Face数据集上取得第一名
利用Low-level Feature Pyramid Layers将feature map整合,解决小图像,姿势,角度等检测难题。
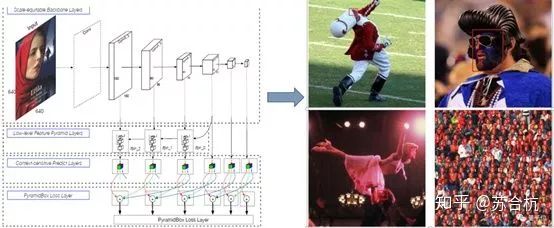
(2)Dual Shot Face Detector
腾讯优图(CVPR2019),将当前feature map与高层feature map做了特征融合。
下面的feature enhance module其实是将本层feature map和上一层的frature map做了1个特征融合
-----END-----
@苏合杭
版权声明
本文版权归《苏合杭》,转载请自行联系。


点击文末阅读原文 或 扫描上方二维码报名
历史文章推荐
AI综述专栏 | 多模态机器学习综述
深度学习中不得不学的Graph Embedding方法
旷视研究院新出8000点人脸关键点,堪比电影级表情捕捉
何恺明团队最新研究:3D目标检测新框架VoteNet,直接处理点云数据,刷新最高精度
打开阿兹海默之门:华裔张复伦利用RNN成功解码脑电波,合成语音 | Nature
图嵌入(Graph embedding)综述
半天2k赞火爆推特!李飞飞高徒发布33条神经网络训练秘技
再也不用担心我的公式写不出来了:一款公式输入神器实测
【深度学习】一文看尽深度学习各领域最新突破
2019 年 12 个深度学习最佳书籍清单!值得收藏
你正在看吗?👇




