赛尔原创 | EMNLP 2019融合行、列和时间维度信息的层次化编码模型进行面向结构化数据的文本生成
论文名称:Table-to-Text Generation with Effective Hierarchical Encoder on Three Dimensions (Row, Column and Time)
论文作者:龚恒,冯骁骋,秦兵,刘挺
原创作者:龚恒
下载链接:https://www.aclweb.org/anthology/D19-1310/
转载须注明出处:哈工大SCIR
1.任务
2.背景和动机
3.方法
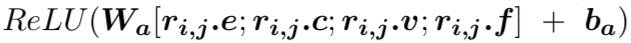 ,
,
其中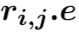
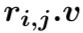
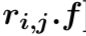
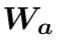
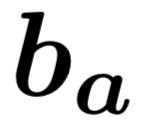
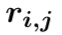
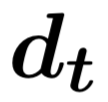
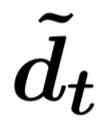
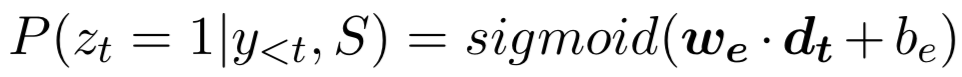
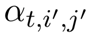
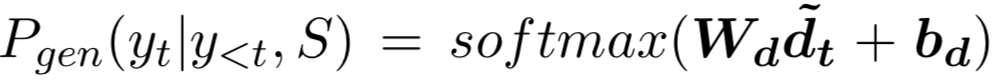
3.2 三层层次化编码器
(1) 第一层:分别采用自注意力机制表示一个三元组数据与和它同行数据之间的关系、同列数据之间的关系以及和历史数据之间的关系。由于历史数据具有时序性,所以在对历史数据建模的时候,我们加入了Position Embedding。
以行维度的表示为例:
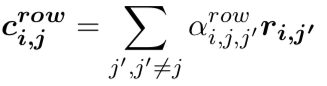
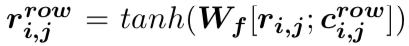
(2) 第二层:我们采用了一个融合门机制将三元组来自行、列和时间维度的信息进行融合。首先通过多层感知器得到三元组来自行、列和时间维度的总体表示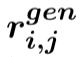
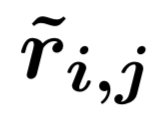
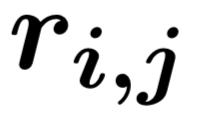
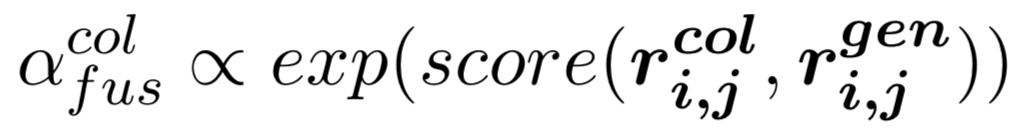
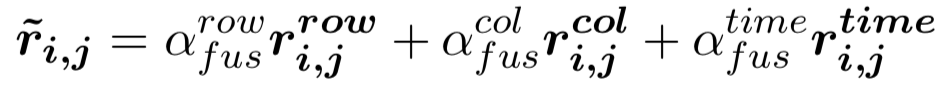
(3) 第三层:我们通过三元组表示的池化以及门机制[5],得到表格中每一行(球队/球员)的表示。
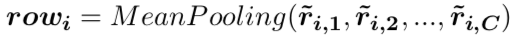
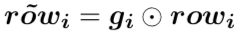
3.3 双注意力机制
由于层次化解码器提供了每一行(球队/球员)的表示,以及每一个三元组数据的表示,解码阶段,首先通过注意力机制从每一行(球队/球员)的表示中找到重要的信息,然后对每一行对应的数据通过注意力机制找到重要的具体三元组信息进行生成。
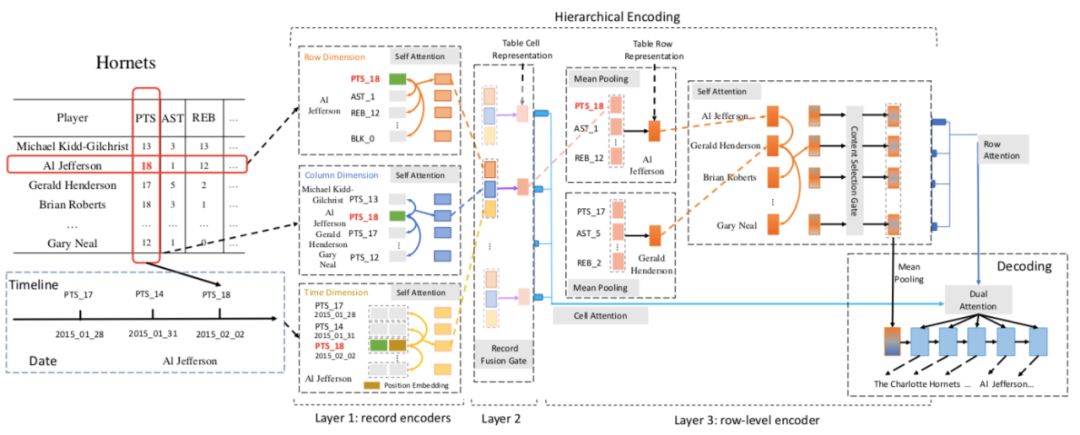
图2 融合行、列和时间维度信息的三层层次化编码器框架图
4. 实验
4.1 数据集
4.2 评价指标
4.3 自动化评价结果
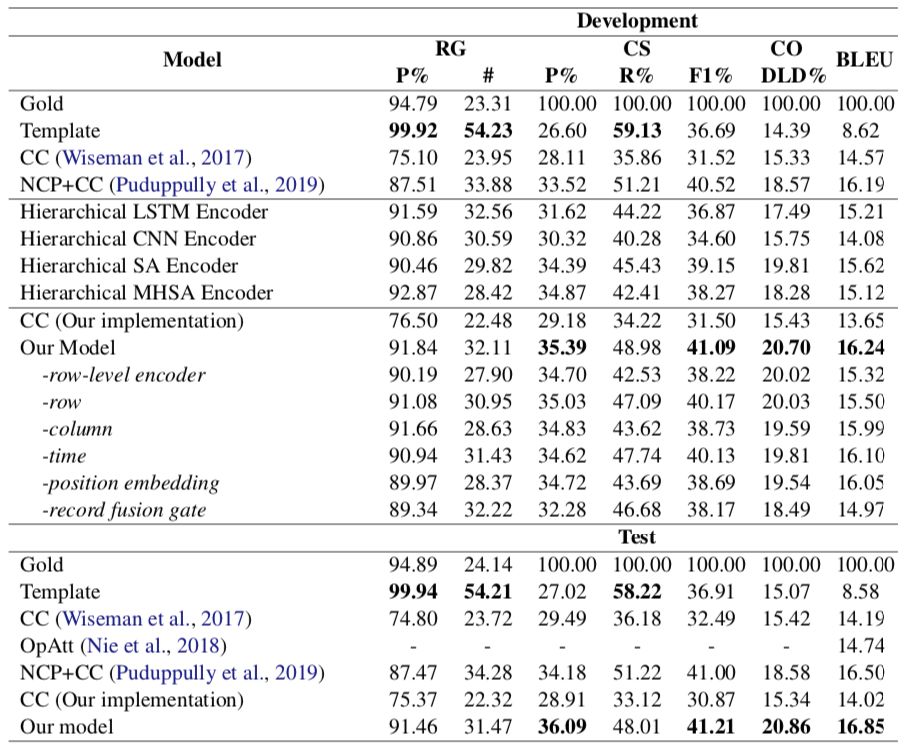
图3 自动化评价结果
4.4 人工评价结果
我们对比了我们的模型和基线模型(CC)、SOTA NCP+CC模型、基于模版生成的结果和参考文本生成的结果,发现:
(1) 相比于另外两个基于神经网络的模型,我们的模型生成更少的错误信息。
(2) 相比于另外两个基于神经网络的模型,我们的模型在语法(Gram),连贯性(Coher)和简明性(Conc)上表现更好。
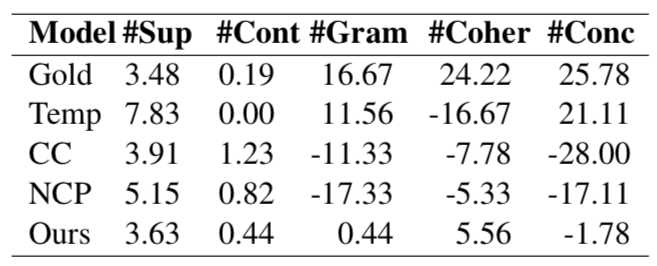
图4 人工评价结果
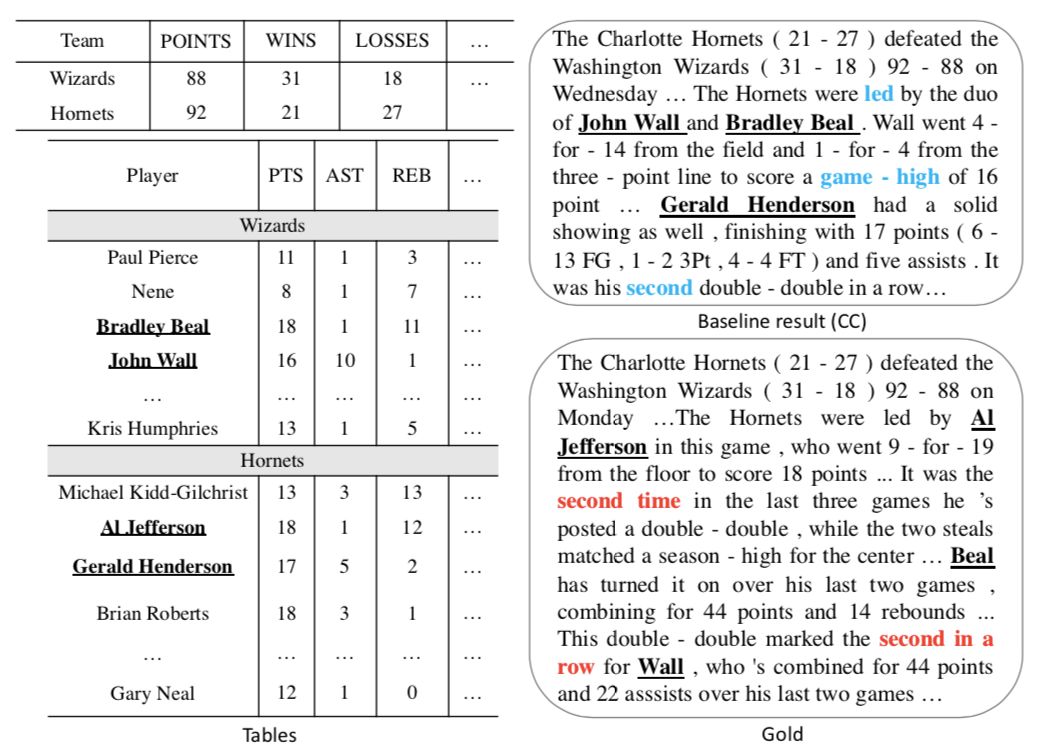
4.5 生成案例
图5生成的案例体现了我们模型生成的文本中的一些优势:
(1) 正确的选出了图1所示基线模型没能选出的重要的球员Al Jefferson,这需要模型正确理解不同球员之间表现水平的关系(列维度的信息)。
(2) 正确提到了Al Jefferson拿到了“两双”,这需要模型捕捉这个球员各项数据之间的关系(行维度的信息)。
(3) 正确提到这是他三场比赛中第二次拿到这样的数据,这需要模型建模历史数据(时间维度的信息)。

图5 生成案例
5. 结论
参考文献
[1]Albert Gatt, Francois Portet, EhudReiter, James Hunter, Saad Mahamood, Wendy Moncur, and Somayajulu Sripada.2009. From Data to Text in the Neonatal Intensive Care Unit: Using NLGTechnology for Decision Support and Information Management. AI Communications, 22:153-186.
[2]Sam Wiseman, Stuart Shieber, andAlexander Rush. 2017. Challenges in data-to-document generation. In Proceedingsof the 2017 Conference on Empirical Methods in Natural Language Processing,pages 2253–2263. ACL.
[3]Liunian Li and Xiaojun Wan. 2018. Pointprecisely: Towards ensuring the precision of data in generated texts usingdelayed copy mechanism. In Proceedings of the 27th International Conference onComputational Linguistics, pages 1044–1055. ACL.
[4]Feng Nie, Jinpeng Wang, Jin-Ge Yao,Rong Pan, and Chin-Yew Lin. 2018. Operation-guided neural networks for highfidelity data-to-text generation. In Proceedings of the 2018 Conference onEmpirical Methods in Natural Language Processing, pages 3879–3889. ACL.
[5]Ratish Puduppully, Li Dong, and MirellaLapata. 2019. Data-to-text generation with content selection and planning. InProceedings of the AAAI Conference on Artificial Intelligence, pages 6908–6915.Association for the Advancement of Artificial Intelligence.
[6]Ratish Puduppully, Li Dong, and MirellaLapata. 2019. Data-to-text Generation with Entity Modeling. In Proceedings ofthe 57th Annual Meeting of the Association for Computational Linguistics, pages2023-2035. ACL.
[7]Hayate Iso, Yui Uehara, TatsuyaIshigaki, Hiroshi Noji, Eiji Aramaki, Ichiro Kobayashi, Yusuke Miyao, NaoakiOkazaki, and Hiroya Takamura. 2019. Learning to Select, Track, and Generate forData-to-Text. In Proceedings of the 57th Annual Meeting of the Association forComputational Linguistics, pages 2102-2113. ACL.
[8]Thang Luong, Hieu Pham, and ChristopherD. Manning. 2015. Effective approaches to attention-based neural machinetranslation. In Proceedings of the 2015 Conference on Empirical Methods inNatural Language Processing, pages 1412–1421. ACL.
赛尔原创 | EMNLP 2019 基于上下文感知的变分自编码器建模事件背景知识进行If-Then类型常识推理
赛尔原创 | EMNLP 2019 跨语言机器阅读理解
本期责任编辑:丁 效
本期编辑:冯梓娴
本文转载自公众号:哈工大SCIR,作者哈工大SCIR
推荐阅读
Google工业风最新论文, Youtube提出双塔结构流式模型进行大规模推荐
T5 模型:NLP Text-to-Text 预训练模型超大规模探索
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLP君微信(id:AINLP2),备注工作/研究方向+加群目的。




