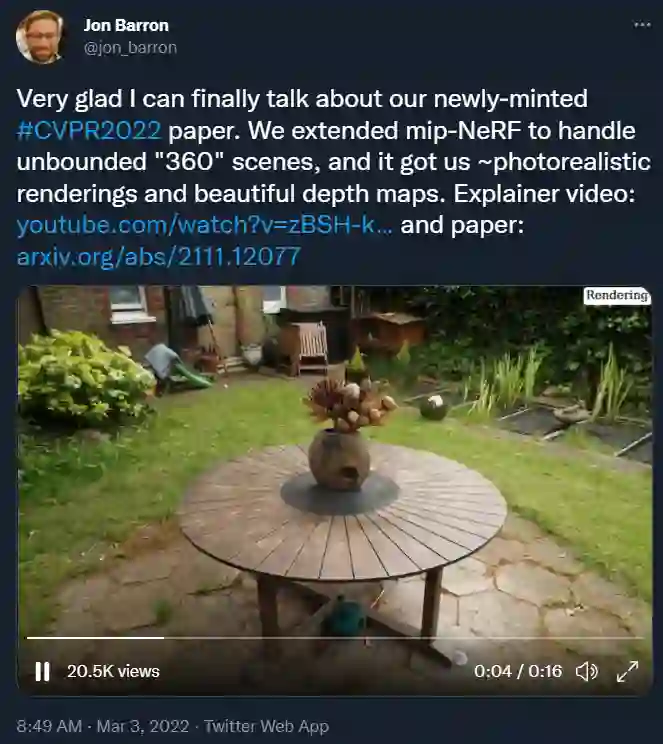
NeRF 家族的 360° 全景 3D 效果真是越来越丝滑了。
前段时间,CVPR 2022 公布了今年的论文接收结果,同时也意味着投稿的论文终于熬过了静默期。不少作者都感叹:终于可以在社交媒体上聊聊我们的论文了!
今天要介绍的论文来自谷歌研究院和哈佛大学。谷歌研究科学家、论文一作 Jon Barron 表示,他们开发了一种名为 Mip-NeRF 360 的模型,该模型能够生成无界场景的逼真渲染,给我们带来了 360° 的逼真效果和漂亮的深度图。
![]()
![]()
![]()
![]()
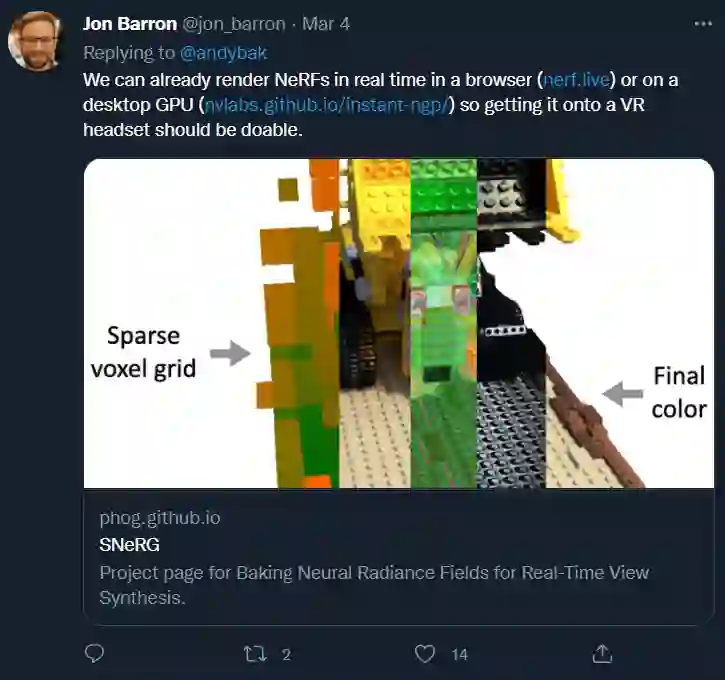
作者回答说,「我们已经可以在浏览器 (http://nerf.live) 或桌面 GPU (https://nvlabs.github.io/instant-ngp/) 上实时渲染 NeRF,所以把它放到 VR 头盔上应该是可行的。」
![]()
神经辐射场 (NeRF) 通过在基于坐标的多层感知器 (MLP) 的权重内编码场景的体积密度和颜色,来合成高度逼真的场景渲染。这种方法在逼真的视图合成方面取得了重大进展 [30]。然而,NeRF 使用 3D 点对 MLP 的输入进行建模,这在渲染不同分辨率的视图时会导致混叠。
基于这个问题,Mip-NeRF 扩展了 NeRF ,不再对沿锥体的体积截头体进行推理 [3]。尽管这样做提高了质量,但 NeRF 和 mipNeRF 在处理无界场景时会遇到挑战,无界场景中的相机可能面向任何方向并且场景内容可能位于任何位置。
在这篇论文中,研究者提出了对 mip-NeRF 的扩展 ——mip-NeRF 360,它能够生成这些无界场景的逼真渲染(图 1)。
![]()
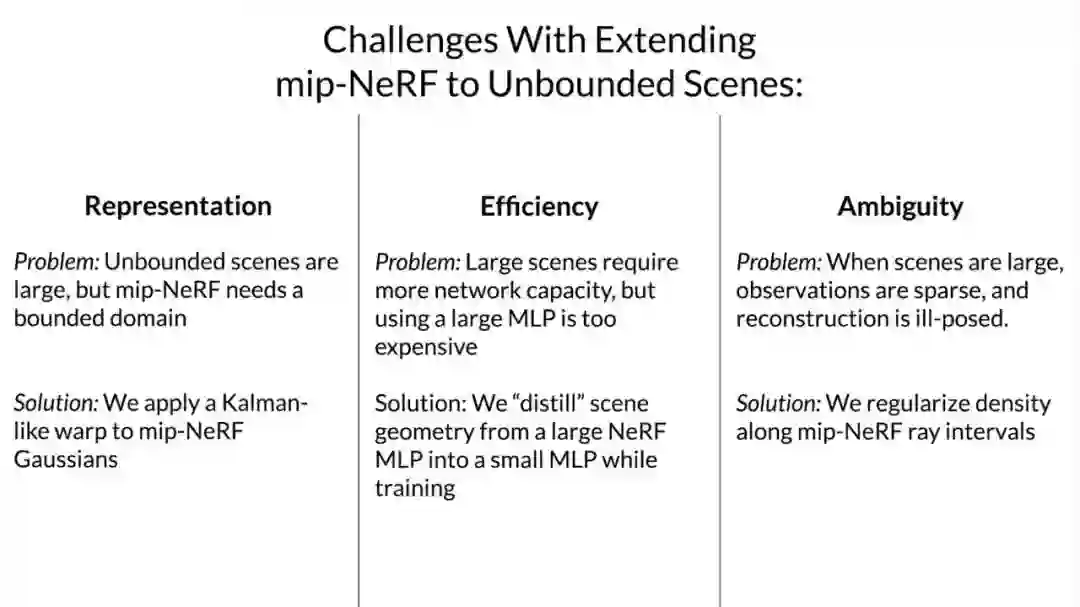
将类似 NeRF 的模型应用于大型无界场景会引发三个关键问题:
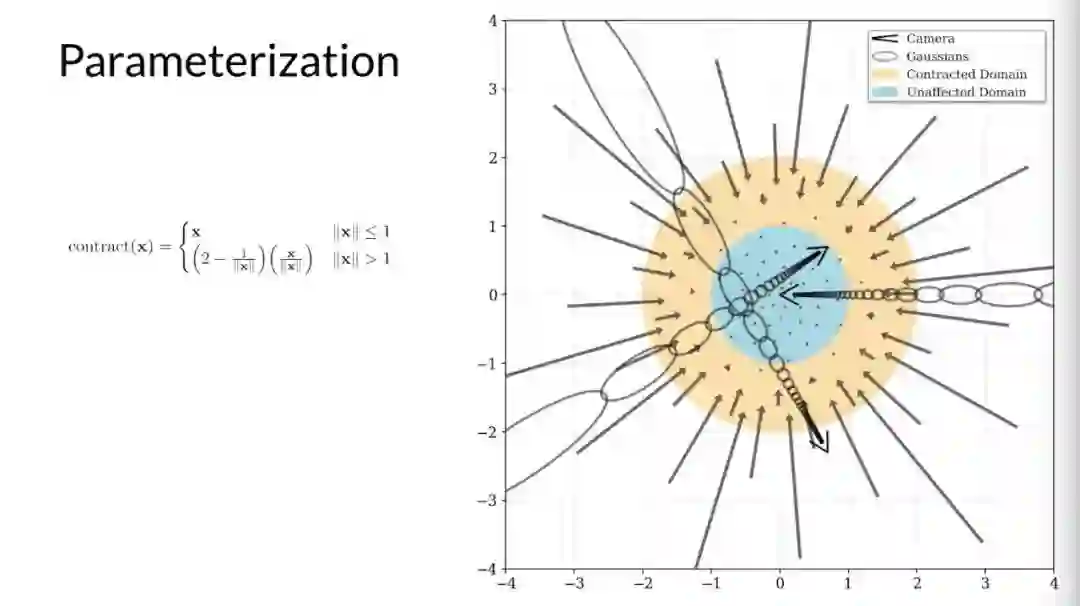
参数化问题。mip-NeRF 要求将 3D 场景坐标映射到有界域,所以无界的 360 度的场景会占据无穷大的欧式空间区域。
效率问题。巨大且细节化的场景需要巨大的网络容量,所以在训练期间,频繁地沿每条射线去查询巨大的 MLP 网络会产生巨大的消耗 。
歧义问题。无界 360 度场景的背景区域明显比中心区域的光线稀疏。这种现象加剧了从 2D 图像重建 3D 内容的固有模糊性。
基于上述问题,研究者提出了 mip-NeRF 的扩展模型,它使用非线性场景参数化、在线蒸馏和新颖的基于失真的正则化器来克服无界场景带来的挑战。新模型被称为「mip-NeRF 360」,因为该研究针对的是相机围绕一个点旋转 360 度的场景,与 mip-NeRF 相比,均方误差降低了 54%,并且能够生成逼真的合成视图和详细的深度用于高度复杂、无界的现实世界场景的地图。
![]()
让 mip-NeRF 在无界场景中正常工作存在三个主要问题,而本文的三个主要贡献旨在解决这些问题。接下来,让我们结合作者给出的解读视频来了解一下。
![]()
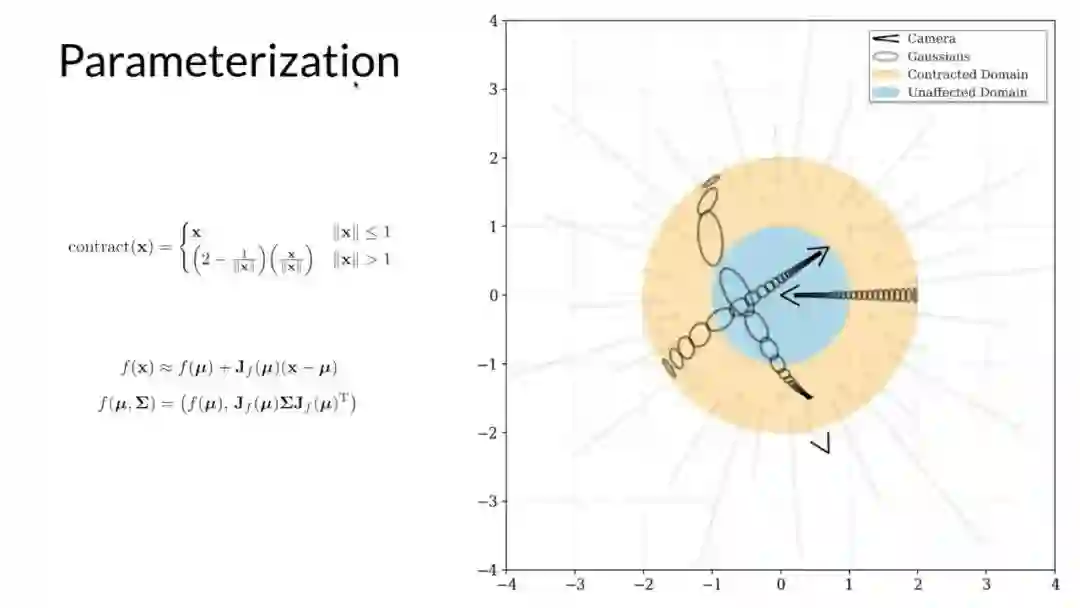
第一个问题是在表示方面,mip-NeRF 适用于有界坐标空间中,而非无界场景,研究者使用一种看起来很像是一种扩展版的卡尔曼滤波器将 mip-NeRF 的高斯函数扭曲到非欧式空间中。
第二个问题是,场景通常是细节化的,如果想将 mip-NeRF 用于无界场景,可以将网络变得更大,但是这样会让训练速度变慢。所以,在优化阶段,研究者提出训练一个较小的 MLP 来限制空间大小,这可以让训练速度变快三倍。
第三个问题是,在更大的场景下,3D 重建的结果会变得较为模糊,产生伪影。为了解决这个问题,研究者引入了一种新型正则化器,专门用于 mip-NeRF 中的射线间隔。
首先来谈第一个问题,以一个有着三个摄像头的平地场景为例,在 mip-NeRF 中,这些相机将高斯函数投射到场景中。在一个大的场景,这导致高斯函数逐渐远离原点并且被拉长。这是因为 mip-NeRF 需要基于有界的坐标空间并且高斯函数在某种程度上是各向同性的。
![]()
为了解决这个问题,研究者定义了一个扭曲函数,来平滑地将蓝色圆(Unaffected Domain)外部的坐标映射到橙色圆(Contracted Domain)内。扭曲函数旨在消除 mip-NeRF 中的高斯非线性间距的影响。
![]()
为了将这种扭曲应用于 mip-NeRF 中的高斯函数,研究者使用了一个扩展版的卡尔曼滤波器,这样一来,没有边界的场景就可以被约束到橙色圆内,橙色圆内是一个非欧式空间,其中的坐标就是 MLP 的输入。
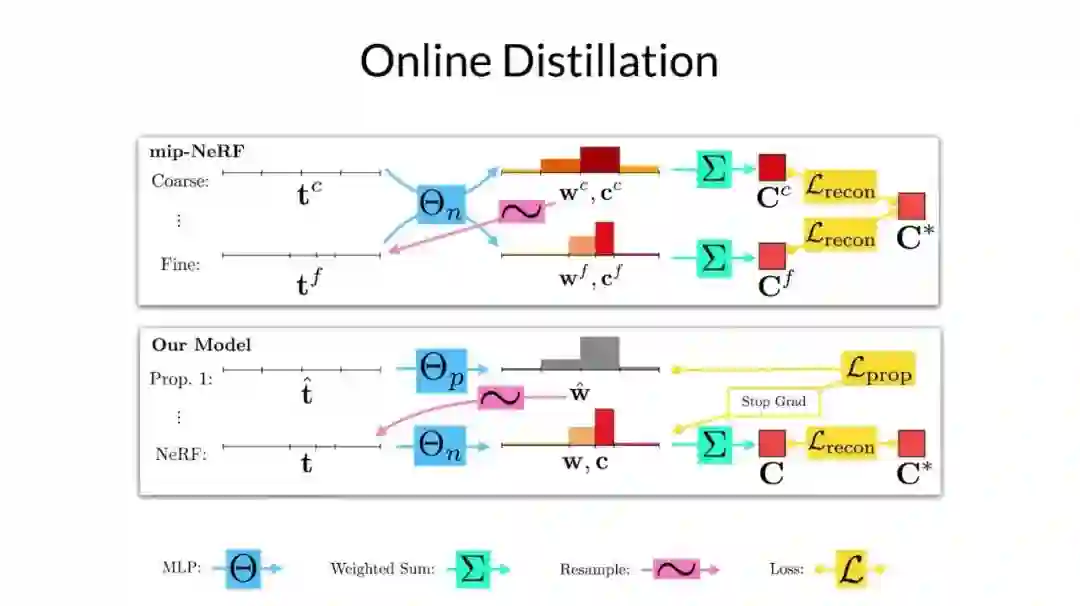
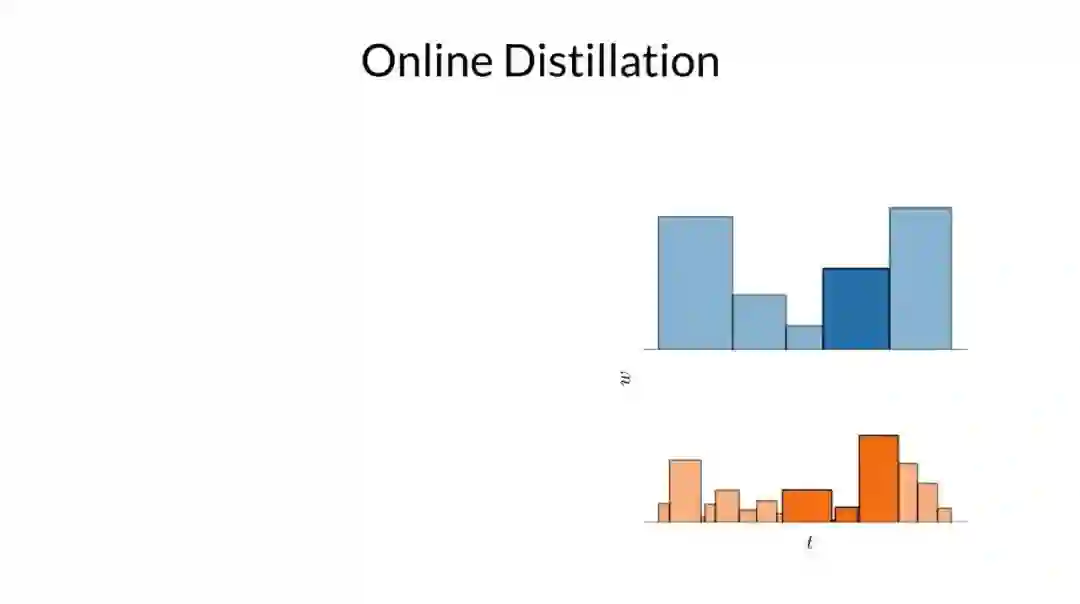
为了能理解论文中的在线蒸馏模型,我们首先需要介绍 mip-NeRF 是如何训练以及采样的。在 mip-NeRF 中,首先需要定义一组大致均匀分布的区间,可以理解为直方图中的端点。如图所示,每个间隔的高斯都被送入 mlp,并且得到直方图权重 w^c 和颜色 c^c。然后将这些颜色加权后得到像素点的颜色 C^c。之后这些权重被重采样,并得到一组新的区间,并且在场景中有内容的地方,端点就会较为聚集。
![]()
这个重采样可以多次进行,但为了方便在这里只显示一个。这个新的区间中的数据被送入同一 MLP 来得到一组新的权重和颜色,然后再通过加权得到像素点的颜色 C^f。mip-NeRF 只是最小化所有渲染像素值和输入图像真实像素值之间的重构损失。只有精细的颜色被用来渲染最终的图像是非常浪费的。
粗略渲染需要有监督学习来完成的唯一原因是帮助指导精细直方图的采样,这一观察激发了文中模型的训练和采样过程。研究者从一组均匀分布的直方图开始,将它们送入提出的 MLP 以产生一组权重,但不产生颜色。
这些权重会被重新采样,同样这个过程可以重复多次,但他们在视频中只展示了一个重采用过程。他们提出的 mlp 产生的最后一组区间被送入另一个 mlp,该 mlp 的行为与 mip-NeRF 中的完全相同,他们将其称为 NeRF mlp。NeRF mlp 为他们提供了一组可以用于渲染像素颜色的权重和颜色。
研究者将通过监督学习的方式,使得像素渲染得到的颜色接近真实图片中的颜色。他们让监督输出权重与 NeRF mlp 的输出权重一致,而不是监督文中提出的 mlp 来重建图像。这种设置意味着只需要经常去访问一个较小的 mlp,而较大的 NeRF mlp 则不需要太多的访问次数。
![]()
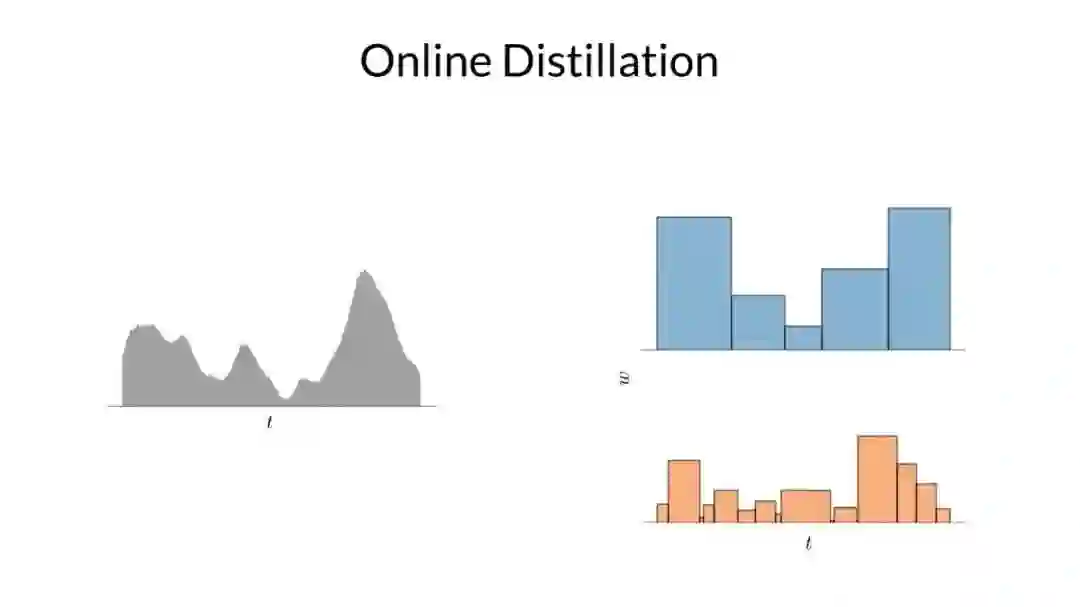
为了使模型起效,他们需要一个损失函数来鼓励具有不同区间划分的直方图彼此一致。为了说明这一点,如上图所示,他们在左侧构建了一个真实的一维分布,在右侧的是两个该真实分布的直方图。
![]()
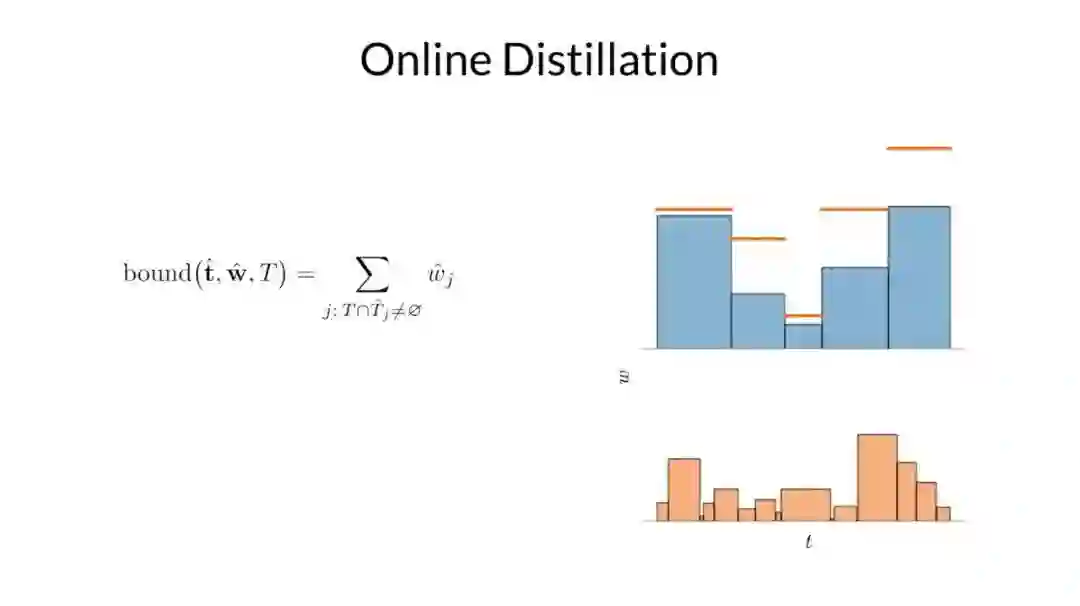
因为这两个直方图刻画同一个分布,研究者可以对它们之间的关系做出一些强有力的断言,例如上面突出显示的那个区间的权重一定不会超过在下面的直方图中与其重叠的区间权重的总和。基于这个事实,他们可以使用一个直方图的权重来构造另一个直方图权重的上限。
![]()
再一次声明,如果这两个直方图同时刻画相同的真实分布的,上界是必须确定的。
![]()
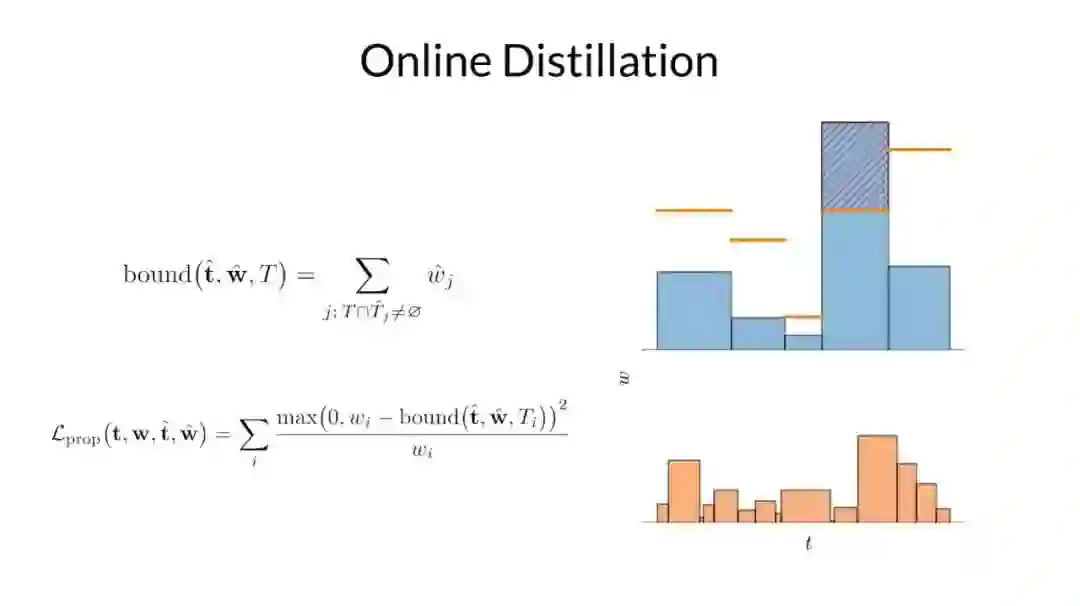
因此,在训练期间,研究者对他们提出的 mlp 和 NeRF mlp 分别生成的直方图之间构造了损失,该损失会惩罚任何违反此处以红色显示的边界的多余部分。通过这样方式,来鼓励他们提出的 mlp 学习什么是有效的上界。
![]()
![]()
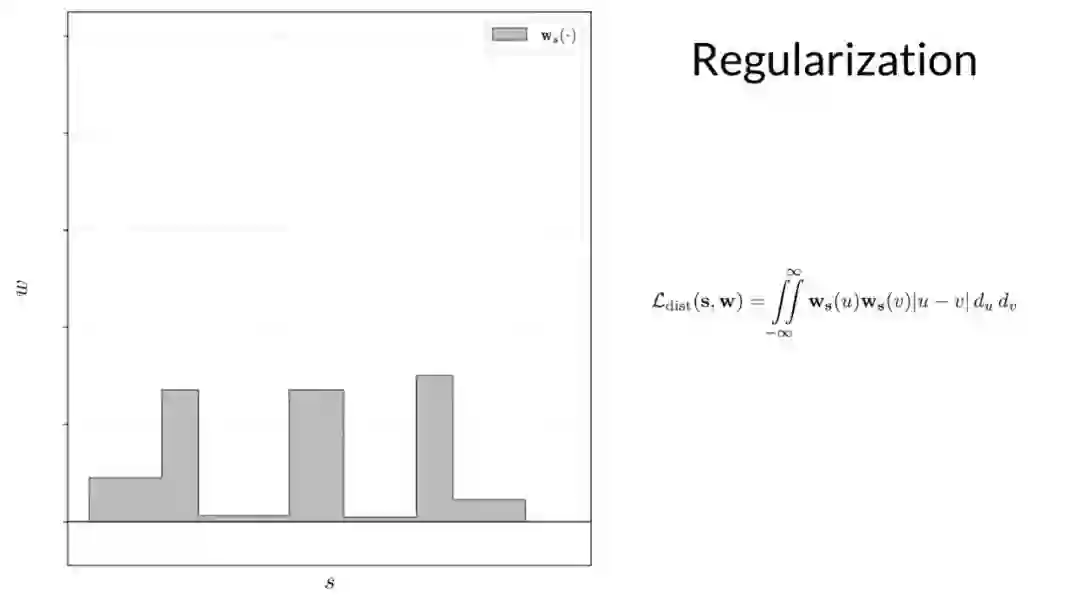
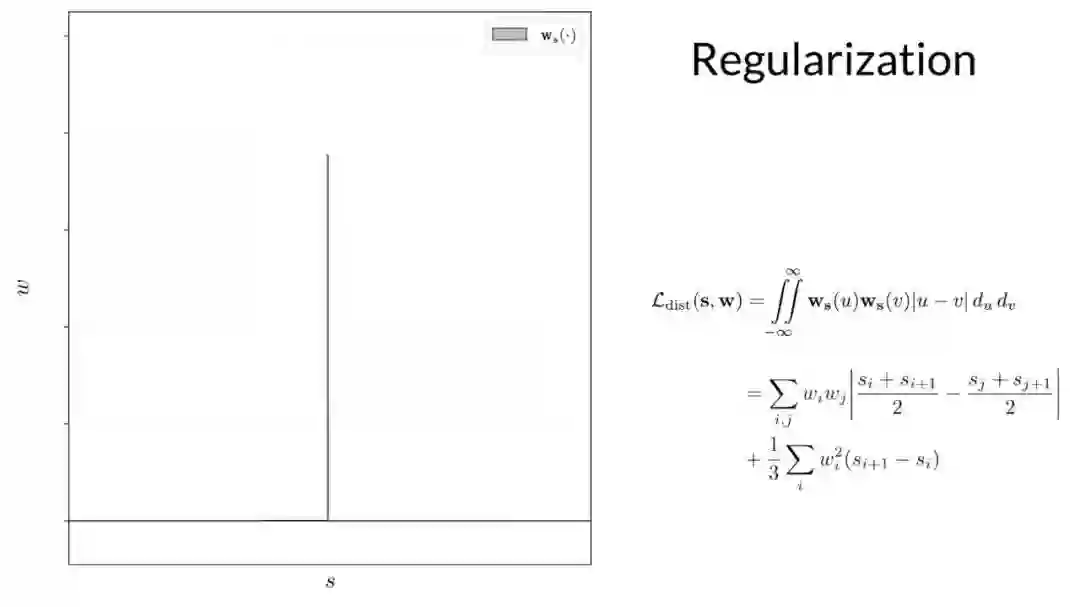
基于 nerf mlp 学习的体积场景密度,新模型中用来解决歧义问题的组件是光线直方图上的简单正则化器,他们简单地最小化沿光线的所有点之间的加权绝对距离,来鼓励每个直方图尽可能接近 delta 函数。这里显示的这个二重积分不容易计算,但可以推导出一个很好的封闭形式,计算起来很简单。
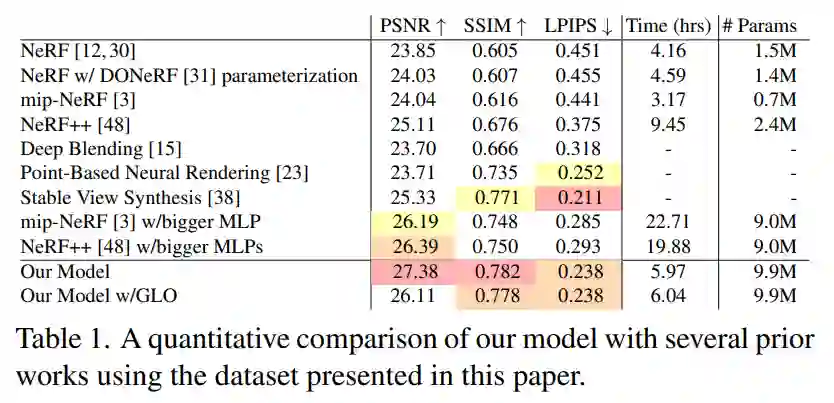
表 1 展示了数据集中测试图像的平均 PSNR、SSIM [46] 和 LPIPS [49]。从中可以看出,本文提出的模型大大优于所有先前的类似 NeRF 的模型,并且可以看到相对于 mip-NeRF ,均方误差减少了 54%,而训练时间仅为 1.92 倍。
![]()
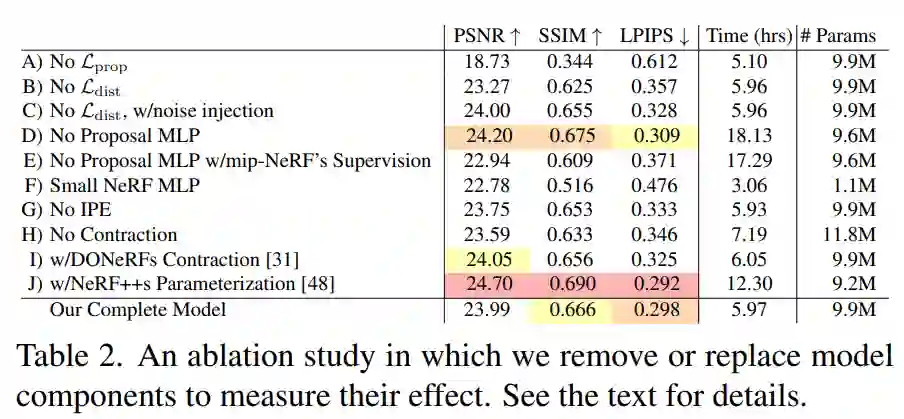
在表 2 中,研究者对模型在自行车场景中进行了消融研究,并在此总结了研究结果。
![]()
A) 移除 L_prop 会导致灾难性的失败,因为 MLP 完全不受监督。
B) 移除 L_dist 通过引入伪影降低图像质量(参见图 5)。
![]()
C) Mildenhall 等人提出的正则化器 [30] 将高斯噪声 (σ = 1) 注入密度当中,但效果不如我们的正则化器。
D) 移除研究者提出的 MLP 并使用单个 MLP 对场景和权重进行建模不会降低性能,但会比他们提出的 MLP 增加约为 2 倍的训练时间。
E) 删除 MLP 并使用 mip-NeRF 的方法训练本文提出的模型(在所有粗略尺度上应用 L_recon 而不是 L_prop)会降低速度和准确性,这证明研究者使用的监督策略是合理的。
F) 使用小型 NeRF MLP(256 个隐藏单元而不是 1024 个隐藏单元)加速了训练,但降低了质量,这展示了大容量 MLP 在建模详细场景时的价值。
G) 完全移除 IPE 并使用 NeRF 的位置编码 [30] 会降低性能,显示了基于 mip-NeRF 而不是 NeRF 的价值。
H) 消除收缩并增加位置编码频率来限制场景会降低准确性和速度。
I) 使用 DONeRF [31] 中提出的参数化和对数射线间距会降低精度。
J) 尽管使用 NeRF++ [48] 中提出的双 MLP 参数化可以优于本文中的技术 —— 但代价是训练时间加倍,因为 MLP 的验证时间加倍(为了保持恒定的模型容量,研究者将两个 MLP 的隐藏单元数除以 √2)。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com