ACL&AAAI顶会分享:揭开事件检测的神秘面纱
AI TIME欢迎每一位AI爱好者的加入!
事件检测已经作为人工智能领域的一项基础核心技术,被广泛应用到事件图谱的构建以及文本摘要的生成。事件检测中优质的结构化知识信息,能够指导我们的智能模型具备更深层的事物理解、更精准的任务查询以及一定程度上的逻辑推理能力,从而对海量的信息分析起到至关重要的作用。在第二期AI Time PhD知识图谱专题分享的直播间,清华大学计算机系、知识工程实验室的博士三年级研究生仝美涵,为大家梳理了事件检测任务发展的脉络,并讲解了如何利用模态的互补性以及外部的资源提升事件检测任务的效果,以及对未来发展方向作出了展望。

一、研究背景
事件抽取最早其实是上世纪八十年代由美国国防部发布的任务,当时是为了对恐怖打击做一些信息提取。
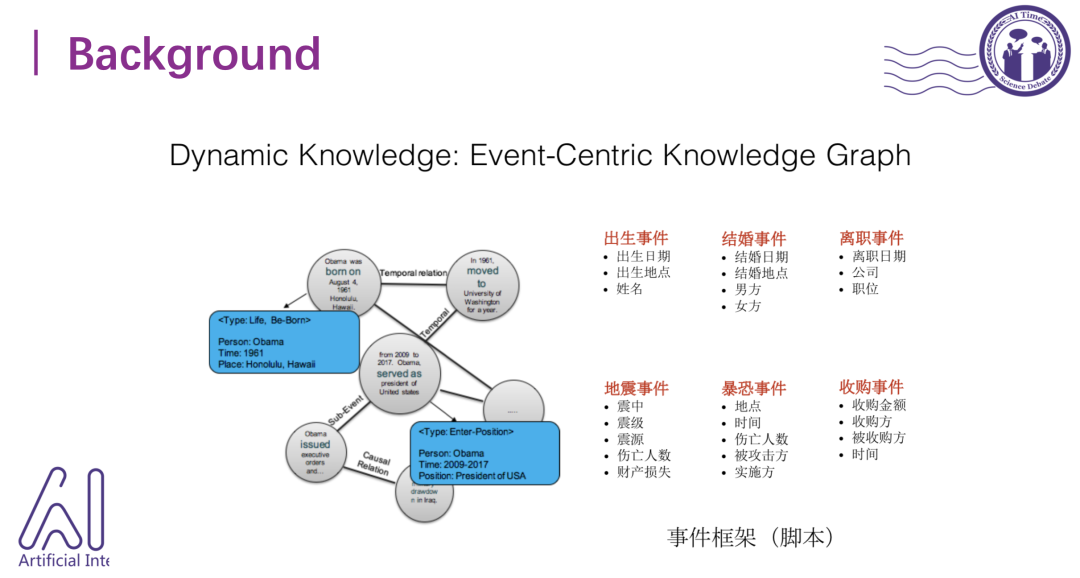
其实现有的知识图谱是一个静态知识的存储方式。比如“奥巴马的妻子——米歇尔”中,奥巴马是头实体,关系是配偶,米歇尔是尾实体。

但是事件抽取的结果可以组成一个动态的知识图谱,或者以一个事件为中心的事件图谱。对于“奥巴马的配偶是米歇尔”这件事情,如果我们知道结婚时间,就可以确定他的配偶这个静态知识是何时开始的,之前是什么状态。
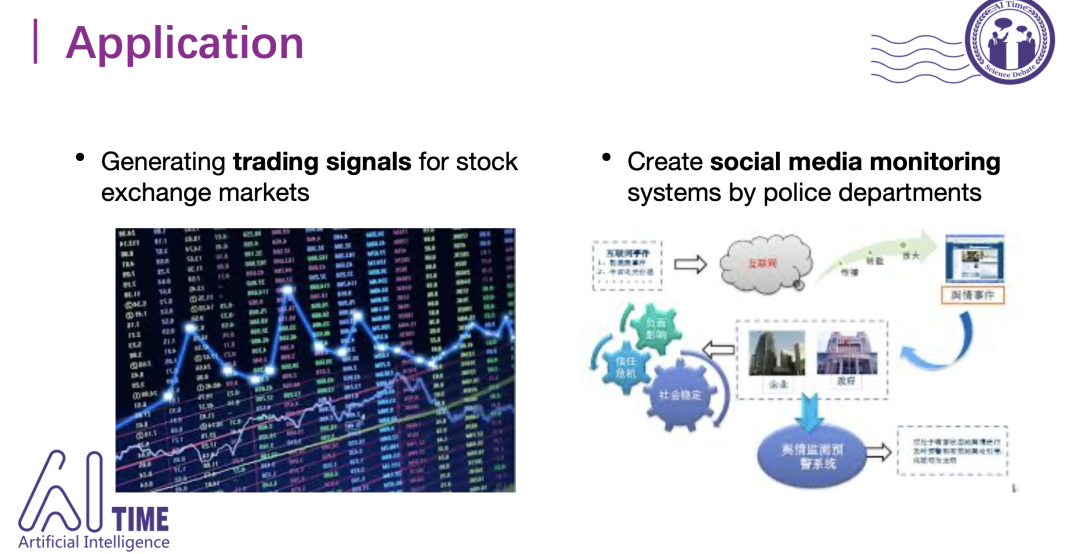
事件抽取在其他方向也有很多应用,比如金融领域。我们知道股票的涨跌其实和市面上一些新闻报道有很大关系,比如之前瑞幸爆出造假账之后股价就大跌。如果我们能够从新闻中快速抽取这些事件的话,就可以对股票进行预测。其次是对社交媒体进行监督,比如在爆发了新冠疫情之后,大家面对该事件的心态和状态、以及政府的应对,我们都可以去进行社交舆论的监测。
二、问题的形式化定义
既然事件抽取应用众多,我们来认识下它的具体定义。
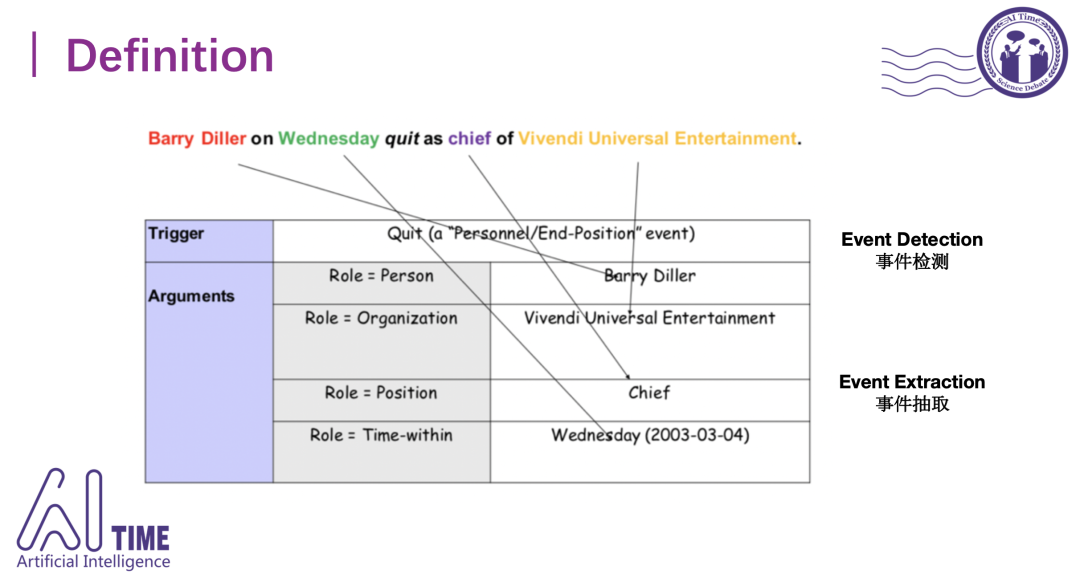
这里的事件其实是句子级别的,由两大部分组成:触发词 (trigger) 和元素 (argument) 。Trigger是一个事件指称中最能代表事件发生的词,是决定事件类别的重要特征。Argument是指事件中的参与者,是组成事件的核心部分,它与事件触发词构成了事件的整个框架。
图中辞职事件里,触发词是quit,参与角色是辞职人Barry Diller,他辞职的职位、时间和机构都可以抽取出来。
事件检测 (event detection) 只识别事件触发词,而事件抽取 (event extraction) 也做参与角色的抽取。
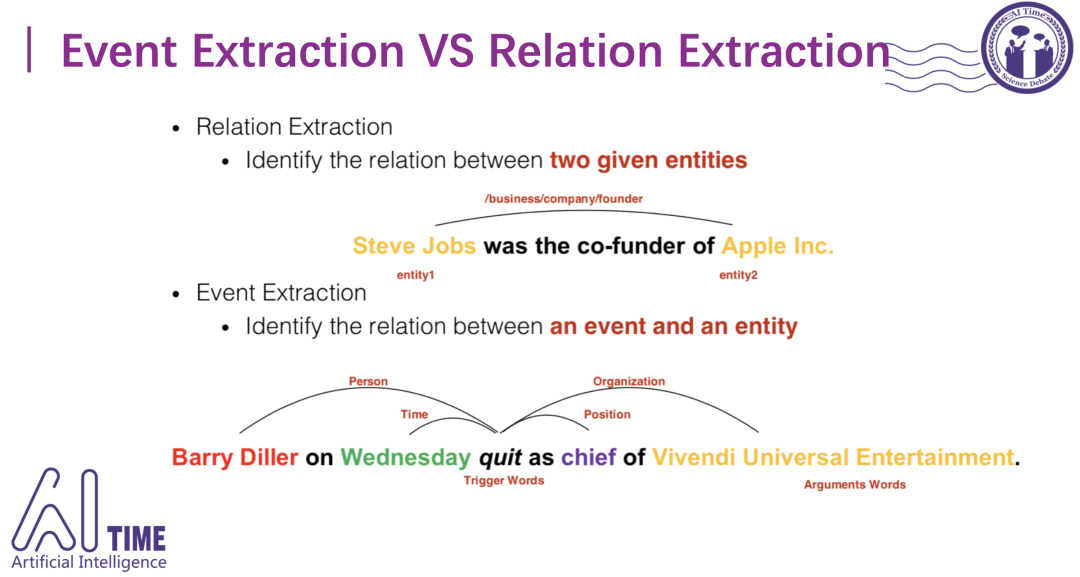
事件抽取和关系抽取的关系:
关系抽取有三个参与角色,头实体、关系和尾实体。而事件抽取是由一个触发词以及多个事件角色(event role)组成的。
三、数据集以及相关竞赛
事件抽取数据集中比较出名的有以下三个:

除了在研究界比较通用的这些benchmark以外,其实在生物方面也有一些具体领域数据集的构建:

以下是今年一些事件抽取的竞赛:

四、事件抽取的一些方法
a)
监督学习方法
1)基于特征工程
13年之前大家公认的有监督方法是基于特征工程的,研究者们会人工定义很多特征、变成onehot表示,输入到随机森林或者支持向量机SVM之类的模型当中,然后做分类。

当时设计的特征工程有三类:
一、周围环境词的特征,包括n-gram、词汇原形以及同义词的特征。
二、句法的特征。这类代表是用一些句法树的结果,去增强事件抽取的性能。
三、实体类型信息的特征。
然而,基于特征工程方法有一些缺点。首先,因为是基于已有的nlp工具做特征抽取,会受限于工具本身的准确率,也可能带来一些噪音,这些噪音会被引入后续算法中无从修改。其次,现有的NLP工具跟语言相关,对于英语这种高资源语言没有问题,比如有Stanford Parser这样的工具。但是对于低资源语言,比如越南语、闽南语,没有现成工具去帮助标注这些特征,这时特征工程就失效了。

2)数据驱动
因此2013年以后,大家更关注于数据驱动的事件抽取方式。这时大家不仅考虑句子本身的信息,还会引入篇章级别的信息。引入篇章级别的信息进行数据驱动具有语义指向性的好处,因为每篇文章都会给一个大概的主题,比如对于新冠肺炎这个公共安全事件,我们可以知道这类文档环境下,更可能发生一些死亡或者治疗事件,不太可能发生一些出生、结婚事件等等。
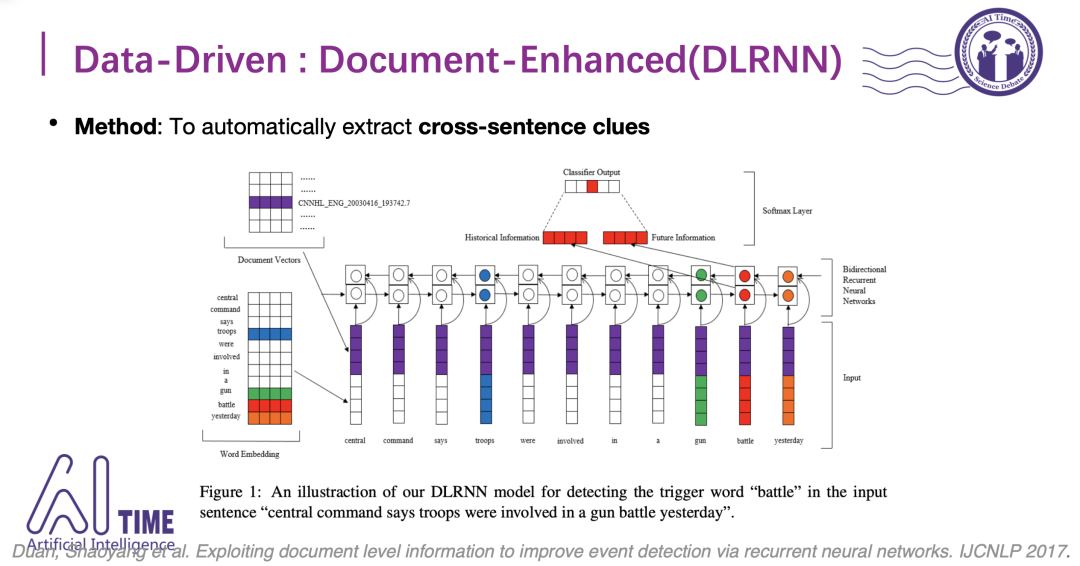
如何融入篇章级别的信息
因为文档级别信息是预先用文本训练好的,所以在训练过程中并不会随着分类的优化而优化,这样会导致文档级别信息在前期分类的时候比较有用,但是后期拟合到一定程度之后信息不够。
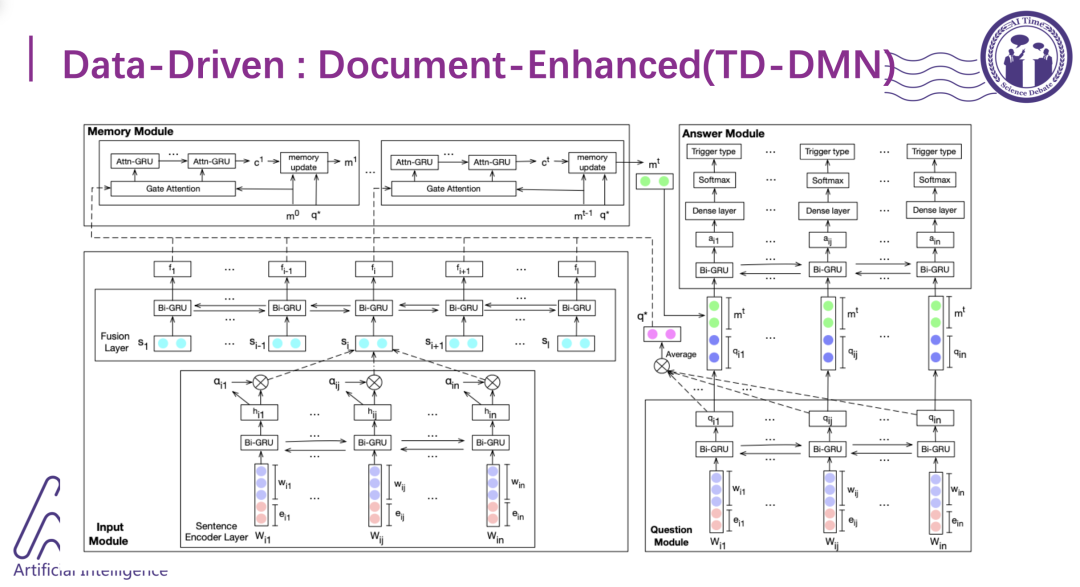
因此,这里又提出了一个新的模型去表示篇章级别的信息。这个模型由四个模块组成:输入模块、内存模块、提问模块和回答模块,这里的篇章级别表示是动态变化的层次级的表示,先把词组成的句子进行一个表示,然后把同一篇文章中不同的句子经过一个双向的GRU层,最后再通过动态的记忆循环机制去进行更新。对于每个进来的句子都会更新一下,导致最终输出的篇章级别的表示是随着环境语义的变化而变化的。
b)
低资源场景的解决方式
我们可以回顾一下事件抽取数据集,其篇章级别只有几百的量级,标注的句子集只有几千,对于这样的数据量,在有监督训练过程中很可能过拟合,因此需要在低资源场景下提供一些解决方案。
1)链接更多数据
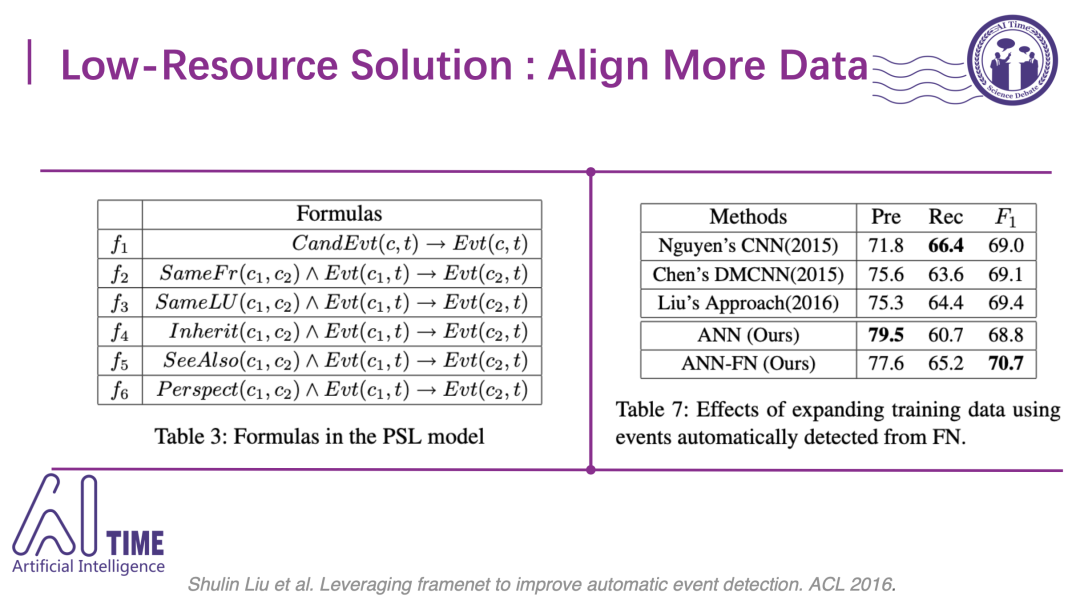
一个非常直观的解决方案是链接更多的数据进来。比较幸运的是,我们有一个外部的语义数据集FrameNet (FN)。它所定义的事件分类体系和ACE事件分类体系有一些对应关系。比如下图中FrameNet会定义一个invading的类,而ACE中定义一个attack的类,都是表达“攻击”的事件语义,因此我们可以设计一些模板将两个数据集进行对应。

实验结果表示,使用FrameNet对齐数据的ANN-FN比没有使用FrameNet的ANN效果明显提升了两个点。
2)多任务的学习
另一个思路是进行多任务的学习,也就是引入其它任务的数据然后进行联合学习,从而增强事件检测的能力。比如18年EMLP就是提出了一个词语消岐的任务来提升事件检测的联合学习的方法,把词汇消岐的参数和事件检测的参数进行一个软链接,使其有相互约束的关系,从而使得两个任务可以相互学习。

3)多语言的学习
除了引入多任务,我们可以从数据端进行一个多语言的链接学习。比如源语言是英语的话,可以翻译成中文,然后做中英文联合的事件检测。通过把一个语言翻译成另一语言,数据得以加倍,并且不同语言之间会有互补的作用。


4)引入多模态
另一种思路是引入多模态的形态表示。在做文本模态的分类时,可以引入一些图片模态的信息来帮助我们对词进行消歧,比如2017年发布的这篇文章其实是把图像信息和文本级别上的词和短语进行对齐,从而丰富文本模态的语义,比如要判断"confront"是触发暴力事件还是会面事件,根据周围语境不太好判断,但是加入了包含市长、会议信息之类的图片后,在这种很有条理的场景下,可以判断出更像是会议事件。
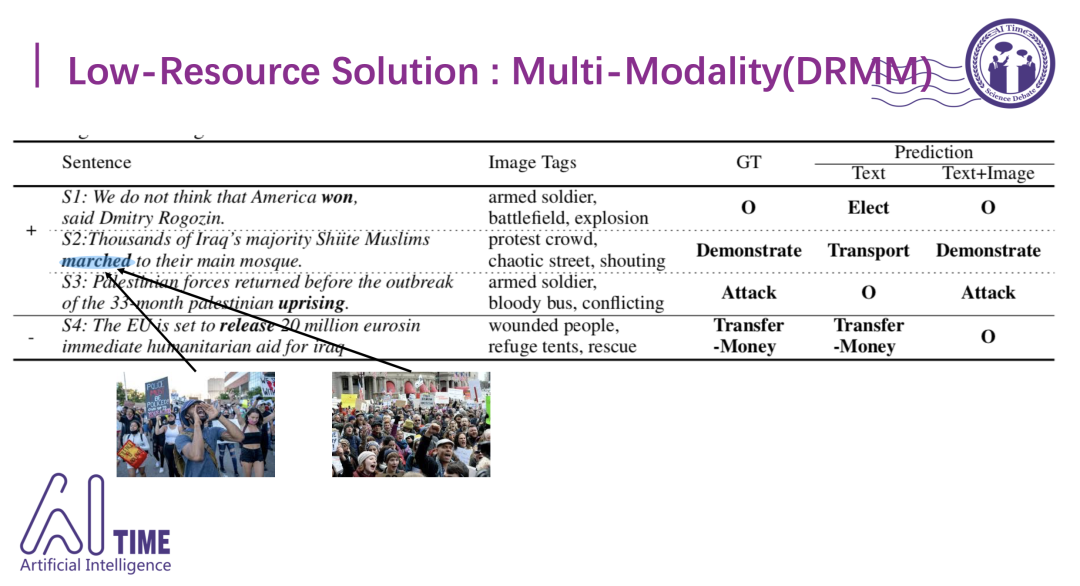
加入了图片信息之后,能够识别出一些分类上的错误。比如S2这句话其实是说很多穆斯林走到清真寺进行抗议,但是march本身没有抗议的意思,更多是表示移动,所以如果不结合这些图片信息的话,难以识别出这条示威事件。
5)知识增强
还可以从知识的角度去增强。由于数据集中各类的分布非常不均衡,比如attack类其实有1000多条标注,但是像fine或者acquire就只有五个到六个的标注,长尾现象非常严重。

于是在19年ACL 发表的一篇文章是从区分度信息和泛化度信息的角度进行了一个对抗的训练,使得模型没有那么依赖于触发词本身进行分类,而是必须依赖于周边环境进行分类。

延续这个问题,我们在今年acl2020上也提出了一篇新的论文,这个论文上引入了一个叫open-domain trigger knowledge的知识,实现对于长尾的极少遇见的触发词的性能提升。

Open-domain trigger knowledge是基于wordnet得到的知识,它可以告诉我们句中哪些词是具有事件性的。比如在这句话中,由于尼日利亚的总统就职导致恐怖袭击升级。这句话中升级、袭击和就职其实都是有事件性的词,如果单纯进行有监督训练的话,由于就职(inauguration)这个词是一个生僻词,在训练语料中根本没有出现,所以很可能过拟合训练语料,从而没办法把就职这个词识别出来。但是有了open-domain trigger knowledge的支持之后,我们知道这个词是有事件性的,需要关注它是否触发事件,从而增强召回率。
c)
弱监督方法
1)Pattern-Bootstrapping
早期的弱监督方法其实更集中于模板的迭代,它是从输入的种子词库出发,从未标注的文章中发现更多的词汇。比如在做美国去攻打伊拉克的事件抽取的时候,攻打的后面很可能会接入一个受害者或者被攻打方,通过这种模板就可以查找到更多的受害方,从而扩大我们的种子词库,然后把它放到一个分类器中去判断哪些是真样例哪些是假样例,把假样例放回到未标注的例子中,把真样例加入到我们的训练样例中,去更新分类器的参数,从而一直迭代下去。
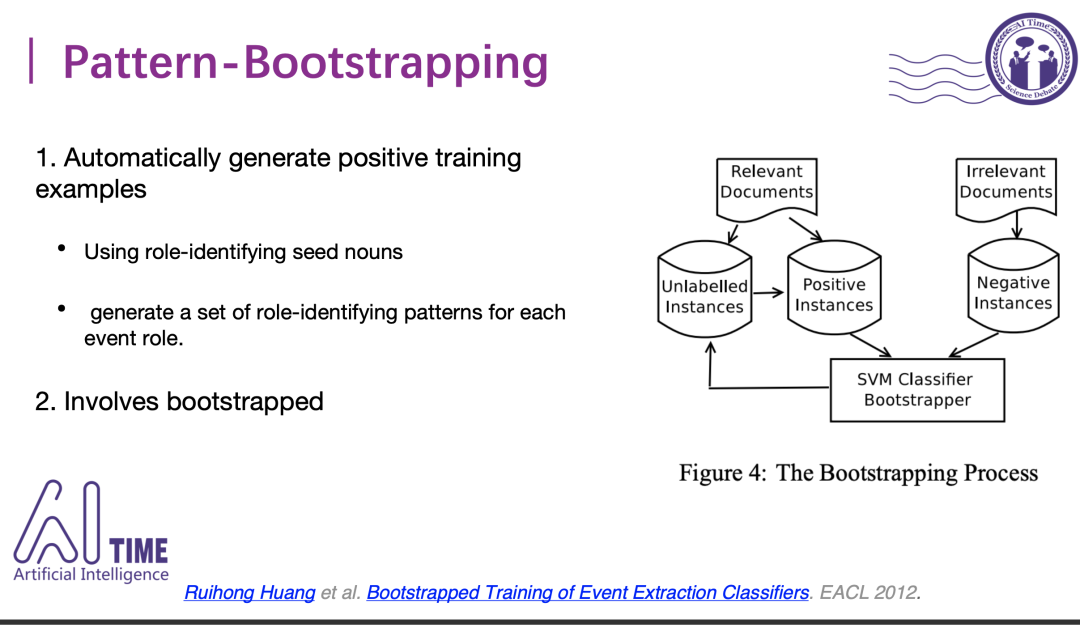
2)Self-Training
另一种思路是自训练的方式,不同于模板迭代,它有一种数据聚类。对于已有的一些文章,他会先进行聚类,然后对聚类结果打标签,根据标签去划分到各个已有的类上,从而增强这种分类的方式。在进行聚类结果的获取时,同时考虑了时间和实体信息,思路是一句话里包含相同的实体,并且这句话的报道时间差不多,那么很可能会触发同一件事,这其实是基于观察的方式得出来的假设。比如上半年澳大利亚发生了火灾,那么同时出现澳大利亚和这个时间的话,我们很可能知道这类文章都在报道大火这件事情。

根据这种方式聚类之后,我们可以训练一个简单分类器对这些聚类结果进行分类,然后根据分类把未标注的数据进行一个标注,有了标注之后还需从句子中选取出事件触发词,这其实是根据已有的一些触发词的集合进行初步的判断,这样我们就可以得到完整的事件抽取的标注数据,和已标注的数据进行一个联合训练,从而提升模型的效果。
3)Zero-shot Learning
最后介绍零样本学习的思路。
零样本学习的动机是新的事件类一直会出现,而新出现的这些事件类没有已经标注好的数据可以使用,另一个动机是希望这个学到的模型可以快速适应新的事件类型而不需要新数据的辅助。一个比较典型的方法是18年ACL这篇文章,其基本思路是把实体还有类统一表示到同一空间上。
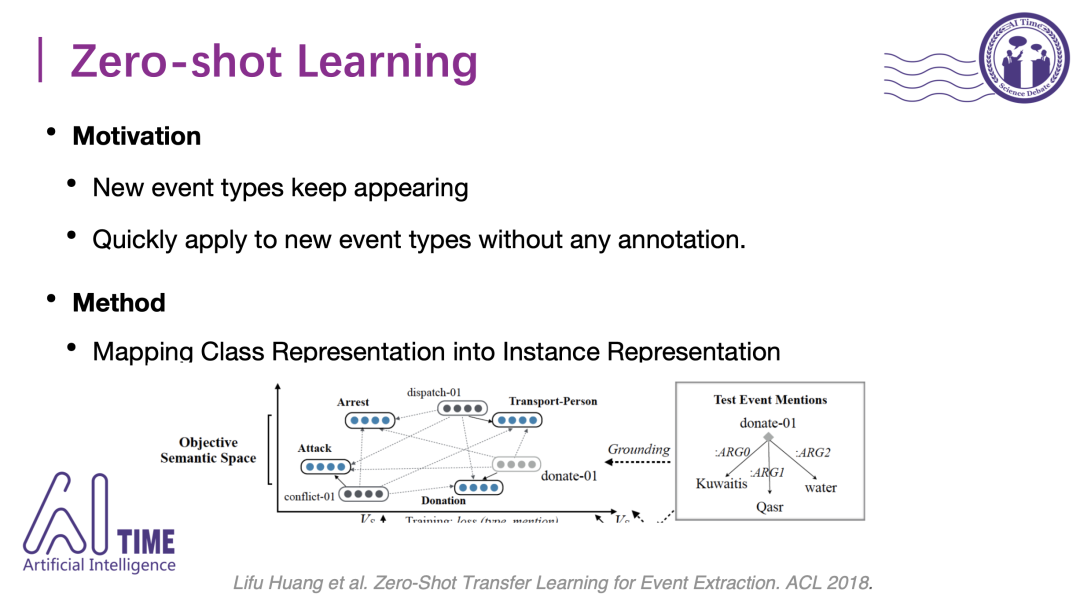
比如图中,蓝色是表示类的隐含空间上的分布式表示,灰色是实体的表示。可以看到dispatch这个实体实例其实是派遣的意思,跟移动transport-person这个事件类更相近,跟逮捕、攻击、捐赠这些事件类都比较远,然后我们可以根据这种几何空间的远近算出cosine值,可以知道dispatch这个实例是属于transport-person这个类。

总结事件抽取未来可能比较热的方向:
1. 事件抽取目前的核心还在于低资源的监督学习问题上,像小样本学习包括零样本学习是未来很好的方向。
2. 当然,也可以构造更多的数据集。
3. 由于新闻和网络资源越来越多模态化,包含文本、图片、视频或者音频资源,因此可关注多模态场景下的事件抽取。另一个较好的任务是专门做声音的事件检测。
4. 由于事件元素有可能分布在文档中的多个地方,所以除了句子层级的事件抽取,基于篇章级别的事件抽取也值得关注。
答疑互动
最后和大家分享直播后微信群里大家与嘉宾的部分互动。

请问清华的众多开源框架里有哪些是针对今天所提到的事件抽取?

来源框架目前主要集中在事件角色抽取,比如孙茂松老师组有一个thu-nlp的工具集。

有没有办法只提取事件的动作,与视频动作匹配实现自动消息配视频?
你这里提到的事件动作和视频动作对齐是个很好的想法,研究上我们称这类任务为video event extraction,感兴趣的话可以关注。
如何确定由wordnet得到的触发词是具有事件性的词,评定标准是什么呢?
wordnet的事件性评价我们其实用了无歧义的sysnset做为中介,如果sysnset是有事件性的,并且词语消歧后属于这个sysnset,就可以判定该词的事件性。
前两年wsd 的准确率比较低,是不是现在都比较难突破?
目前出现了很强大的预训练模型以后(BERT GPT3 ROBERTA),其实很多NLP的任务都获得了突破,所以对于wsd,通过利用任务相关的知识融合,可能会有进一步的突破。
知识图谱在构建的时候很难做到绝对的知识完备,所以面对新的问题,其可迁移性应该如何考虑呢?
可迁移性其实是所有知识图谱的普遍问题,我理解对应到事件上,其实就是说我们从一个领域到另一个领域以后的分类器也好、抽取器也好都没办法直接用,解决这类问题可以考虑小样本学习,通过很少的数据可以达到新领域的快速适应。
整理:鸽鸽
审稿:仝美涵
部分参考文献:
[1] Tong et al. Improving Event Detection via Open-domain Trigger Knowledge. ACL 2020
[2] Tong et al. Image Enhanced Event Detection in News Articles AAAI 2020
点击“阅读原文”下载本次报告ppt
直播回放:https://www.bilibili.com/video/BV1Z54y1B7Le








