综述 | 事件抽取及推理 (上)
本文转载自公众号:知识工场。
事件概要
事件是一种重要的知识,近年来,越来越多的工作关注于从开放域或领域文本中抽取结构化事件知识。同时,除了本身就很困难的事件抽取任务之外,近年来,越来越多的研究者开始关注于事件的推理工作中(事理推理,事件时序关系推理,事件 common sense level 的 intent 和 reaction 推理)。ACE给了事件定义为:
Anevent is a specific occurrence involving participants. An event is something that happens. An event can frequently be described as a change of state.
从中我们可以看到,事件一般是需要包含事件的参与者(角色),并且事件往往可以被描述为一系列状态的改变。在事件抽取的过程中,一个事件往往被更形式化地定义为包含了事件触发器(event trigger), 事件类型(event type), 事件元素(event argument) 和事件元素角色(event argument role),因此事件抽取的任务就是识别出上述事件要素并且进行结构化组织。从 Zero-Shot Transfer Learning for Event Extraction [HuangL,2017]这篇文章中我们也可以得到一个对事件抽取任务很好的定义:
Thegoal of event extraction is to identify event triggers and their arguments inunstructured text data, and then to assign an event type to each trigger and asemantic role to each argument.
因此,通常来说,事件抽取的基本任务都可以用以下几个方面概括:
事件触发词检测 Event (trigger) detection
事件触发词分类 Event trigger typing (一般和detection一起做,归结为detection的一部分)
事件元素识别 Event Argument Identification
事件元素角色识别 Event Argument Role Identification
举个例子来说明这个几个事件要素:

在这个例子中,触发词 trigger 有两个,为 injured 和 passed away,因此 event detection 的工作主要是识别出这两个触发词(块)。之后,需要对这些触发词进行分类,根据ACE事件触发词分类体系(如下图),结合语义应该对应分成 Injure 事件和 Die 事件。然后红字部分 Henry 根据分析应该判别 Henry 是事件的 Argument,角色都是事件的发起者。
每个事件类型都有一个模板,如下面两个图,列举了一些时间类型的模板和模板的基本样式:
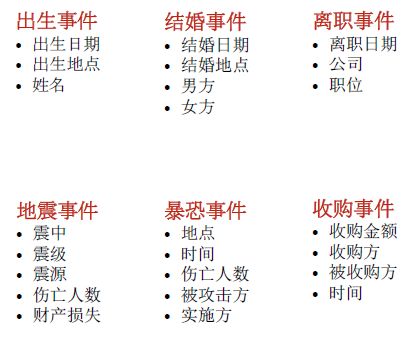
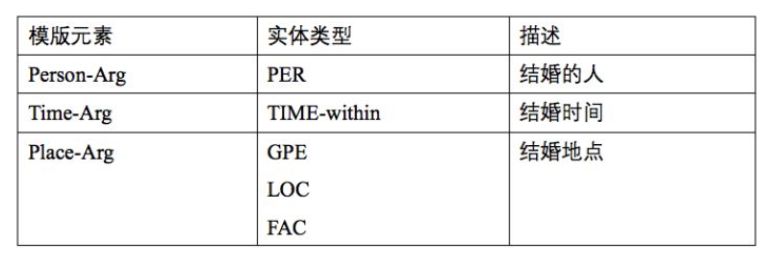
(ACE 2005一些事件类型模板,左图来源于 Kang Liu 的 PPT<Open domain Event Extraction from Texts>,右图来源于网络)
事件在确定了 trigger 类型之后,应该根据这些模板来进行填槽(slots)。
事件抽取方法
事件抽取的基本任务上面已经介绍了,学术界和工业界针对具体的一些任务都进行了自己的研究。这里值得注意的是这几个任务有时候并不是孤立去解决的,现在越来越多工作证明 joint 的方法更加有效(比如 event detection 和 event typing 一般都一起做,大多工作都归结为 event detection 的部分,[Shulin Liu,etc,2017]也指出一般在判断事件类型的时候更需要对应的 Argument role 的信息,以及文本的上下文信息来共同确定)
同样,先以一个简单例子来解释事件抽取方法:
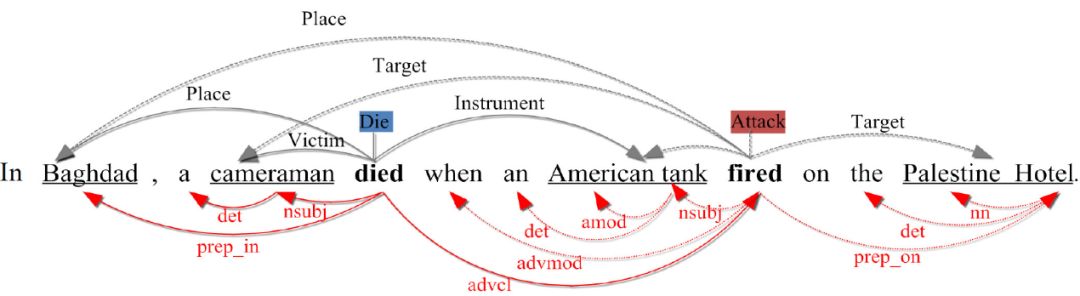
(图片来源于 [Y Chen, 2015] Event Extraction via DynamicMulti-Pooling Convolutional Neural Networks)
在这个例子中首先 event detection 找到两个事件触发词 died 和 fired,然后要 trigger typing 判断出 died 对应的是 Die 事件,fired 对应的是 Attack 事件,句子上面的黑色线表示的是 trigger 和 argument 之间的关系,下面的红线是用 AMR(Abstract Meaning Representations;Banarescu et al., 2013)进行的识别 argument candidates 并且构建起event mention 结构。
从 An Overview of Event Extraction from Text [F Hogenboom .etc ] 中可以总结出事件抽取方法主要有以下几种:
• Expert knowledge driven approaches(pattern-based approaches): 这个类别的方法主要是借助大量的已有的事件 patterns,比较适合于领域的事件抽取,将文本中的句子和已有的事件 patterns 进行匹配。同时使用词汇+语法 patterns 和词汇+语法 patterns 来进行 patterns 制作。这种方式往往能够抽取出准确度较高的事件表达,但是这种方式比较费时费力,并且有领域局限性。
•Data-driven approaches (Machine Learningapproaches): Data driven 的方法借助machine learning 的相关算法,以及深度模型来进行触发词判断等。具体来说,使用SVM,ME,CNN,RNN等方法来判断句子中某个词是否是触发词,重点都是在如何学习文本中 sentence 的表示,来提高判断准确度。另外,也要用 AMR 进行事件本体结构构件,并达到基于事件元素角色、基于事件上下文的自动语义标注。这种方式的好处在于相对需要人力较少,并且可以做开放域文本的抽取,但准确率自然不算高。
•Hybrid event extraction approaches,简言之,就是在做 event detection 的过程使用 pattern based 方法,在做 event typing 的时候要使用 machine learning 的一些方法提高模型的泛化能力,从而在减少人力的情况下尽量做到精准。基本现在近年的工作都是以这种方法作为基础的思想,并且在事件表示,事件学习结构上下足功夫来对事件抽取的各个具体难题进行一一解决。
• 其他方法,此处不详细介绍
接下来,结合几篇具体比较经典的事件抽取工作介绍一下一些基本的事件抽取的想法。
Dynamic Multi-Pooling Convolutional Neural Networks
Paper 原文:[Y Chen, 2015] Event Extraction via DynamicMulti-Pooling Convolutional Neural Networks ;这一节内容图片均来自此文
在事件抽取的工作中,两种特征是十分重要的:
lexical-level (词汇级别特征): prior knowledge (先验知识)
Sentence-level (句子级别特征) :从语法特征方面来帮助更好理解 events 和arguments
词汇级别的特征可以用一个例子来进行详细的说明,如下面的例子:
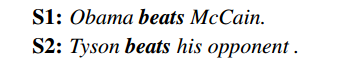
这两个 beat 在两句不同的句子中,我们人是可以识别前者是在讲竞选总统时候 Obama 打败了 McCain,因此这里的触发词 beats 应该对应到的事件类型是 Elect ,而后者说 Tyson 这个拳击手打败了对手,因此这个 beats 应该对应的是 Attack 事件类型。人们之所以知道这样分类是因为有 prior knowledge 即先验知识来支撑这样的分类,即我们知道Obama 和 McCain 是两个总统候选者,因此不太可能真的是 Attack 行为(一般来说),而因为 Tyson 是一个拳击手,所以他的 beat 是实打实的 Attack 行为。原文作者将这样的类似于 prior 的特征成为 lexical-level 的特征。这里我个人认为可以借助知识库(knowledge base,如中文的我们实验室的 CN-DBPedia 和 CN-Probase,借助 entity linking 工具),将具体的实体识别出来,获取这些实体丰富的属性和概念信息,从而可以获取更多的先验知识来进行更精准的实体 typing 。
Sentence-level 的特征主要就是考虑语法特征进去,比较普遍的方法就是用 AMR 工具来对事件表达进行 argument candidate 的识别和事件结构化,即找到每个 argument 和trigger 在语法层面的联系,比如 time,arg0,arg1,place.etc,如下图。
原文作者提出,这种传统的方法在提取这些特征时候严重依赖于已有的工具,但已有的工具的准确程度不能保证,容易导致 error propagation 。因此, sentence-level 和lexical-level 的特征应该使用更好的方式来进行学习和表示。对此,作者提出 Dynamic multi-pooling convolutional neural network 。
已有方法去用 CNN 来对句子进行处理并提取特征,传统的CNN使用一个 max-pooling层来对卷积后的结果来做降维和保留显著特征。池化层(Pooling layer)作用即为此,很多先前工作证明,Max-Pooling 能减少模型参数数量,有利于减少模型过拟合问题,因此在很多 CNN 结构中 Max-Pooling 是很自然的选择。放在句子中的物理含义就是对一个句子的表示做 max 操作,从而找出整个句子最有用的信息。但这样的操作可能会对句子产生信息丢失的错误,如上图的例子,一个摄像师因为美军坦克向一个酒店开火而死亡,使用传统的 CNN 的 Max-Pooling 方式最终会获取的关键信息就是 a man die,这样就会忽略一些重要事实——这个句子还有一个坦克向酒店开火的事件,并且两个事件是包含因果关系的,同时更重要的是,camera man 这个 argument 作为 die 的发起者,同时又是隐含的坦克 fire 事件的受体(虽没有明显指出,但是可以推出来),这些信息都是对 argument role 判定十分重要的。以这个典型的例子原文作者要说明这种用 max-pooling 的方法并不使用于事件抽取任务中。同时,为了使读者相信这种情况不是个例,原文作者使用列数据的方式来直观说明他们研究的必要性和重要性:

(作者对问题的统计工作,可见这种问题在数据集的比例很高,直接说明了问题有研究必要)
下图为该工作主要模型:
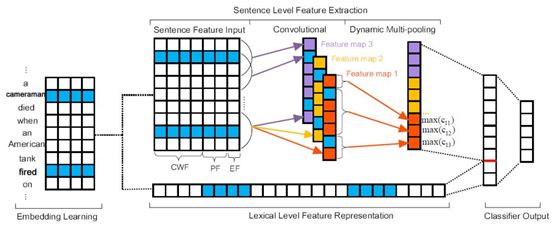
(Architecture. 该图以argument classification的工作过程作为示例)
该工作包含 event trigger identification 和 classification,以及 argument identification 和 argument role classification 的工作,相对比起来 trigger identification and classification要相对简单点,所以就以比较复杂的 argument role identification and classification 作为介绍的重点。
模型的任务是在 trigger identification and classification 做完之后,确定每个句子中的argument 是哪个并且应该是哪种 argument role,每次对句子中除了 trigger 的每个词当做argument candidate,然后进行该 candidate 的分类工作。因此抽象成的就是 word 分类任务,输入是一个句子,以及句子的 trigger(已知,在句子上标注好)和 trigger 的 type (这里讲 trigger 是单个 trigger,多个的话分别去做)。模型从左至右依次介绍:
Embedding learning:word embeddings,这个不需要太多介绍,skip-gram 做word2vec。Word-level 的特征就主要用 word embedding 获取,这里如果要引入知识库的知识作为先验知识则需要知识库的 embedding,或者对知识库进行知识的表示建模。
Lexical Level Feature Representation:即单词 embeddings 的拼接成向量形式
Sentence Level Feature Input:
1)CWF:Context-word feature,上下文特征,这里上下文指的是 argument candidate 上下文,比如图上蓝色部分,即把 cameraman 作为 argument candidate 作为研究,则句子其他部分是上下文。
2)PF:Position feature,当前词和需要进行预测类型的 trigger candidate 或者argument candidate 的相对距离,以 cameraman 为例,则a:-1,cameraman:0,died:1,when:2,an:3, …考虑到上下文位置关系。
3)EF: event-type feature,事件类型特征是对于判定 argument candidate 的类别是十分重要的特征。
DCNN:
1)Convolutional layer:对上述的三个 feature 拼接成的矩阵进行卷积操作,这里简单解释一下对句子的卷积操作:在文本中,一句话所构成的词向量作为输入。每一行代表一个词的词向量(这里就是CWF+PF+EF),所以在处理文本时,卷积核通常覆盖上下几行的词,所以此时卷积核的宽度与输入的宽度相同,通过这样的方式,我们就能够捕捉到多个连续词之间的特征,并且能够在同一类特征计算时中共享权重。 CNN 的作用这里就是捕捉句子的组成结构的语义特征并且把这些语义信息压缩要 feature map 中,使用 Multi-filters,在句子处理时候会自动学习有多少个 filters 来学习尽可能多的语义,比如一个 filter学 compositional feature,一个学习词依赖,一个学习构词法等,最终产生多个 feature maps。如果有 m 个 filters,每个 filter 窗口大小为 h,则
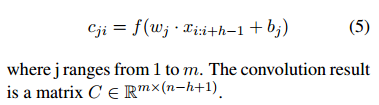
2)Dynamic Multi-Pooling:如图,假设有三个 feature map,传统的 max pooling 直接对每个 feature map 做一个 max 操作来提取最有用的信息,这里用的 dynamic pooling 就是将每个 feature map 根据 argument candidate 和 trigger 来进行分割操作,即把每个feature map 都根据 trigger 和 argument 来切成三块,计算的 max value 不是整个 feature map 的 value,而是这三块分别的 max value。因此,可以看到每个 feature map 经过dynamic pooling 的结果是三个部分的 max 值:max(c_11), max(c_12), max(c_13)。到这里核心部分完成。
Output:将上面所讲的每个 feature map 的 dynamic pooling 的结果拼接,并加上lexical level feature representation 压缩后的结果作为最终的 feature representation,然后过一个全连接层做分类,分类的结果包括各个 argument role 和 None role。
整个模型的主要过程就如上所示,这个讲的是 argument role 的分类方式。Trigger 分类也用同样的模型架构,但是输入少了EF,dynamic pooling 分割时候也只根据当前 trigger candidate 进行分割,其他的都一样,这里不再赘述。看一下实验结果:
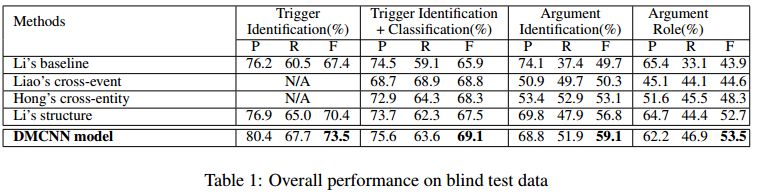
可以看出来这种 DMCNN 模型在 trigger 和 argument role 分类任务上都表现很好,说明了这种模型的效果。
本篇论文总结:
Dynamic multi-pooling 在这里用的十分契合实际的场景,可以有效解决 argument candidate 可能作为多个 trigger 的 argument 但是扮演不同 role 的问题,并且对特征输入做的十分清晰,输入特征比较完整。在中文场景中由于中文的特殊性参考 nugget event trigger identification 那篇文章则应该把 char feature 考虑进去。这篇文章对事件抽取比较有启发性。
下一节交叉讲一下 pooling 选择的策略,不要一味选择 max pooling。
Pooling 选择的策略
这里交叉介绍 pooling 选择的策略:
•池化的应用:降维和保留显著的特征
•Max pooling 是取整个 feature map 区域的最大值作为特征,即一个 max feature操作,在自然语言处理中常用于文本分类(text classification),观察到的特征是一般都是句子的强特征,以便可以区分出是哪一个类别,减少噪音影响。
•Average-pooling 通常是用于句子主题模型(topic model),考虑到一个句子往往不止一个主题标签,这时需要尽量多的句子上下文信息,如果是使用 Max-pooling 的话信息过少,所以使用 Average 的话可以广泛反映这个 feature map 的特征
•K-max pooling:在一个 feature map 上返回K组最大值,即选择 top k 的 feature 结果,不至于省略的太多,也不至于太平均,这种方式还保留了这k个特征的位置信息。
•Chunk-Max Pooling:类似于本文的 dynamic pooling,将 feature map 分为好几个块,具体怎么分块完全看你关注句子的哪几个部分,要定下哪几个部分来进行split 。Chunk-max pooling 和 K-max pooling 的区别在于,后者是事先不对 feature map 进行分割,然后根据值选最大的几块并保留这些值的顺序,前者是先选好切割成几块,然后对每块选该块中最大的值作为该块的结果。这种策略不止在本任务中,在情感分析也有用。比如我在分析句子情感时候,可能比较关注但是(but)这个词,我就可以根据 but 进行分割。原因就是比如一个评价说“某个商品很好,很漂亮,等等等等夸了一大堆, BUT 太贵了买不起”,其实是在含有负面情感在这边,如果 max pooling 那肯定判定是位正面情感,但用这种 chunk-max pooling 方法就能有效甄别出这种情感转折,特征的位置信息在这里就体现的尤为重要。
Event Argument 对事件抽取的促进
Paper原文:[Shulin Liu.etc,2017] Exploiting Argument Information to Improve Event Detection viaSupervised Attention Mechanisms. 本节图片均来自此论文
这篇文章进行一下简单介绍,跟上面一篇文章是同一个研究组进行的,主要强调的是 eventargument 对于 event trigger detection 的重要性。以一个例子说明:

Fired 这个 event trigger 到底应该对应的是哪个事件类型?如果只用 surface text 的话无法判断 Anwar 到底是什么,根据上下文可以得知 former protégé(role=Position)这个argument 角色,则可以辅助判断这个 fired 应该是一个 end-position 的事件 trigger 类型。
这篇文章进一步说明 event trigger identification and classification (ED任务)和event argument identification and classification (AE任务)这两个任务不应该独立去研究,应该把两个任务放在一起 joint 去研究。但 joint 的模型往往作为一个 multi-task 任务,loss 是联合起来进行训练的,语料中 argument 的数目较 trigger 要多得多,则模型偏向去提高 AE 任务。同时 joint 模型往往需要预 predict 一些 trigger candidate , 在预 predict 的过程也没有考虑 Argument 的影响。这篇文章用 supervised attention 来进行借助 argument role 进行 ED 任务, argument word 将会比其他上下文 word 获取更多 attention 。在训练中 attention 值根据实体的类型、上下文等信息进行确定。结构如下所示:
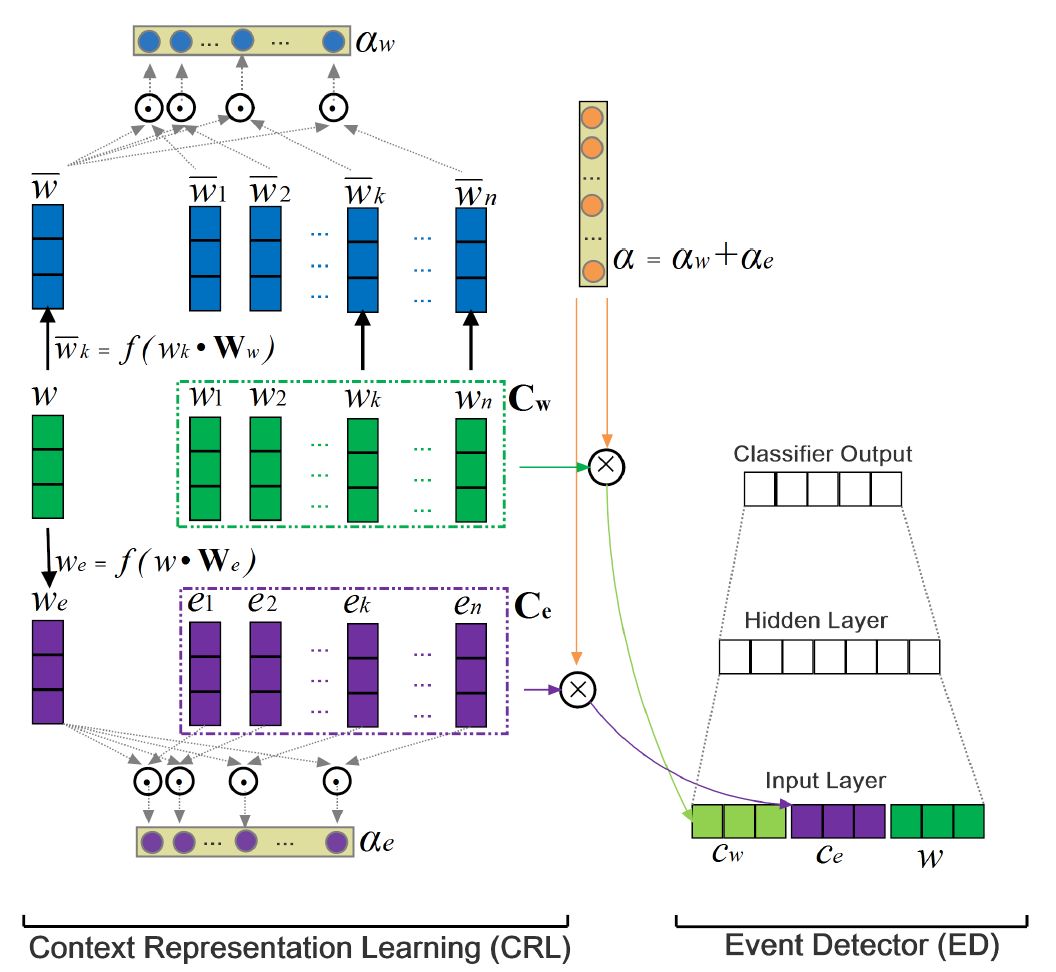
本篇内容的工作突出点就是用了 context 中的实体的类型信息和 supervised attention机制,他们的 attention 机制也就是用标注的 argument 来使 argument 的部分享有更大的 attention 权重,方法比较简单,有兴趣可以原文仔细阅读。
Imitation Learning 和 GAN 在事件抽取中的应用
Paper原文:[T Zhang, H Ji, etc.] Joint Entity and Event Extraction with Generative Adversarial Imitation Learning
本篇文章来自于 Prof. Ji Heng 的研究组,这篇文章站在更高的角度,将 IE 任务中的两种 entity extraction 和 event extraction 结合起来,提出一种端到端的基于模仿学习( imitation learning ) 的联合实体和事件抽取模型,同时为抽取出的实体打上 argument role 的分类标签。并且作者在训练过程中使用了逆强化学习方法 ( inverse reinforcement learning ) 来提高模型的能力.
问题描述和举例:
在两个句子中,有着同一个触发词(mention 相同),并有着相似的事件描述和上下文,传统的方法很难通过上下文词汇和语法特征去正确判别这个触发词应该触发哪个事件,属于哪种类型。即模型对于这种要深层次分析语义从而进行触发词识别的能力不够。
举例描述: Death 这个事件触发词可能触发一个 Execute 事件或者一个 Die 事件。我们可以看到这两句话可以认为有相似的 local information(word embeddings)和contextual features(两件事都在描述一个犯罪事件)。因此,传统的有监督学习的方法会去计算 death 这个词在触发词类型上的概率分布,由于在标准数据集中 death 标注为 Die 类型的比 Execute 多,从而会错误标注成为 Die 类型事件。
之后,原文作者对这种错误的原因进行了精彩的分析,如果有兴趣的读者可以转到原文去仔细阅读 introduction 部分。这里总结分析问题如下:首先原文作者提出这种错误是由于缺乏对错误 label 的学习,传统的多分类问题往往使用交叉熵(cross entropy)来仔细研究为什么学习器学的是对的,但对错误的 label 一视同仁,没有对这些错误的label进行深入的分析。模型学习的是提取大量特征,搞各种奇技淫巧来学习怎么正确去标记句子,但有时候却无法处理一些 ambiguous instances ,这种情况往往错误的特征在计算概率时候没有被减少。因此,从错误 label 中去学习,获取更多信息是提高模型 robust 的关键。
另外,原文引入 RL 也很巧妙,还原到人去学习怎么避免错误的场景,然后让机器去模仿人的动作,原文如下:
•To simulate this behavior fortraining an automatic extractor, we could assign explicit scores on those challenging cases – or rewards in terms of Reinforcement Learning (henceforth,RL).
方法部分:
原文方法归结为几点:使用模仿学习的思想用 Q-Learning 来做序列标记任务,找出哪些 word 是 entity 哪些是 trigger 。之后用用 policy gradient 来做事件对应 argument role 的判定,同时值得注意的是在训练过程中 extractor 的 reward 是由 GAN 来动态评估的。
这里简要介绍下 IRL 的引入原因: 实际任务中设计 reward 很困难,从认了专家提供的ground-truth 去反推 reward 有利于该问题。于是,对于给定状态空间 S,动作空间 A, 并且给定决策轨迹数据集 π,每个 π 由一个 s 和 a 的序列集合组成。
IRL 执行思想:
欲使机器做出和 ground-truth 相同的行为,等价于在某个 reward 的环境里求解最优策略,该最优策略产生的轨迹与范例轨迹一致
初始很难获取所有 policy,可以从随机策略开始,迭代求解更好的 reward 函数,基于 reward 获取更好的 policy,最终求得最符合范例数据集的 reward 和 policy

(RL的一些关键部分对应的信息抽取领域的内容)
下面是 QL 做 entity 和 trigger 识别的框架图,这里进行简要介绍,需要读者有一定 RL背景知识。作者使用 Bi-LSTM 做 context embeddings ,然后输入到 forward LSTM 和全连接层去产生预测结果到 Q-Table 里面。
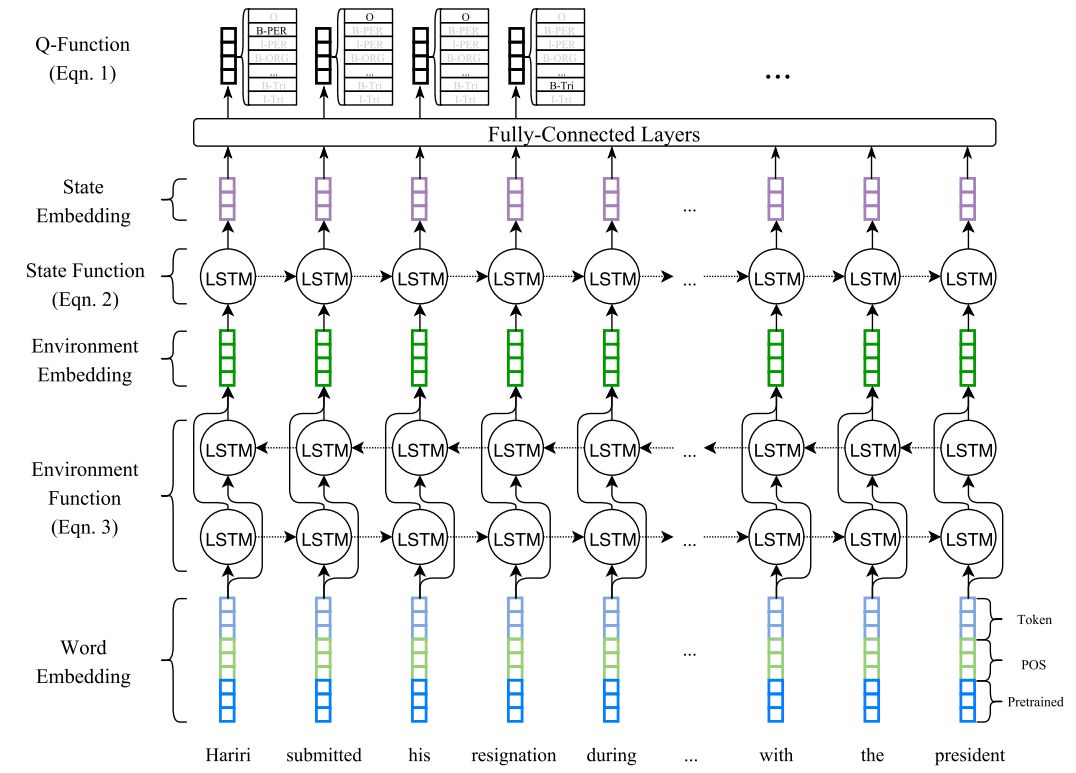
q-table的生成公式为:
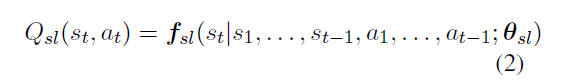
其中,f_sl 操作就是 forward lstm 和 fully connect layer,然后 s_1,…s_t-1 ,说的是句子中当前词之前的所有词标记的状态, a 对应的是一系列的标记 action , theta 是参数集。 Q-table 主要获取所有分类的得分, extractor 就从 table 中获取 rank 得分最大的标记作为标记。这样在每一步都会计算一个 extractor 的标记和 ground-truth 的标记的差别,以此来计算 reward。
当前打的标记也会用 Bellman Equation 来对 Q-table 中的值不断地进行更新,更新的策略为:
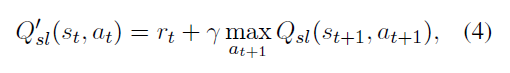
中间那个 max 前面的符号是用来控制当前状态和下个状态的影响的大小。
以 Die 那个例子来看下学习过程:
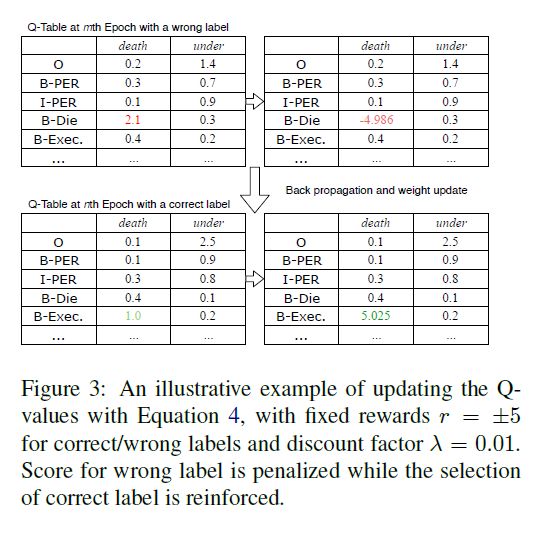
从 Q-table 可以看到,刚开始 die 的分高,等式 4 会惩罚 Q 值,后面之后如果extractor 产生了一个对的 label Execute , Q 值就会被升高,从而让决策强化。
接下来是判断 Argument role 的工作,由于是借鉴之前工作的,因此这里也简单说一下,就是考虑了 candidate argument 和 trigger 的上下文,得到 contextual embedding,同时也考虑了句子中各个实体的类型信息和 trigger 的类型信息,这种方式之前的 paper 也强调了,做法其实没有太大本质差别。结构框架图如下所示:
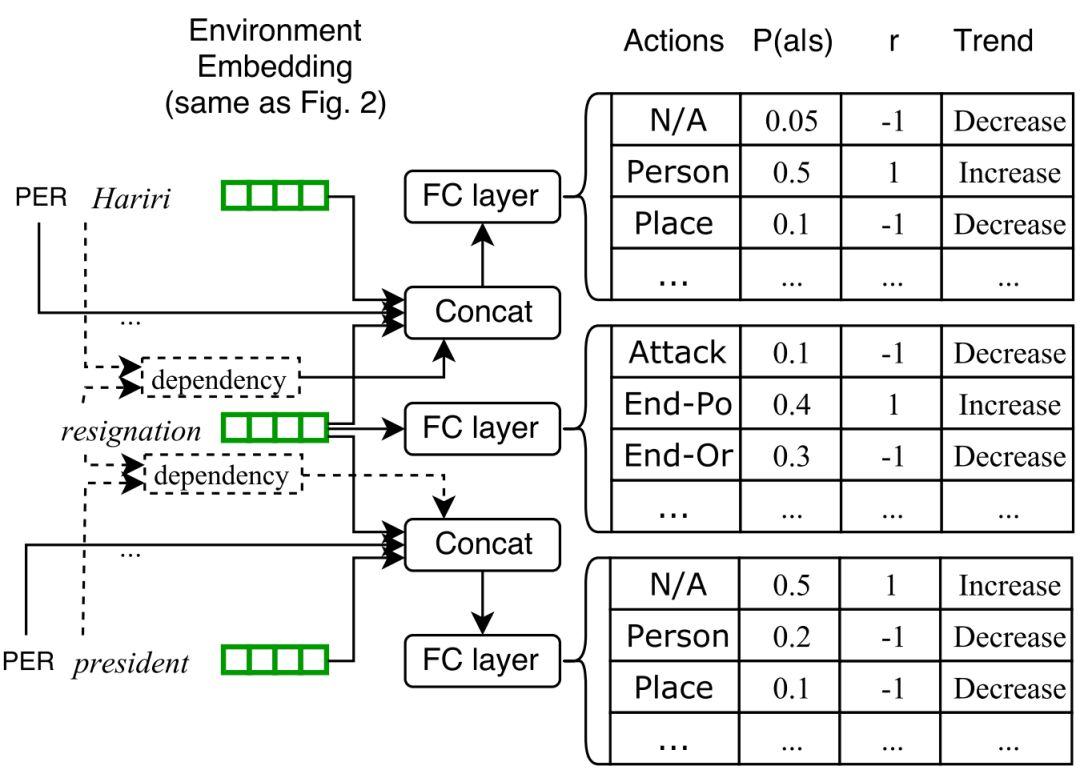
文章另一个重点是用 GAN 来进行 reward 评分,通过不断对比 extractor 的标记结果和 ground truth 进行对抗。具体引入的原因是由于序列标注和角色标注都很复杂,所以reward 值应该是动态变化的
•举个例子:作者认为 extractor 应该给那些把触发词标记成实体的情况比那些对触发词没啥特殊标记的情况更低的分值,就是如果对这些情况都预先定义一个 reward 值的话有点 expensive 。所以用 IRL 来动态评估 reward
1)这里对 GAN 进行训练的过程进行阐述: GAN 在训练过程中扩大了正确和错误标记的 rewards 值的差距,即对学习正确的 label 的例子将会给更高 reward 分,学习错误的label 的例子将会适当给更低的 reward 分,这样不断扩大学习中正负标记的 margins。
2)在训练的最后几个 epoch ,就会获取一个比较好的动态的 reward 值,这个 reward 值就可以反过来导向 extractor 去进行正确标记。
总的来说,这篇文章从写法和思想上都是十分有启发性的,鼓励读者在阅读本次简单的介绍之后去实际读一下这篇文章,现在这篇文章挂在 Arxiv 上。
本篇部分介绍了事件抽取的基本步骤,和一些经典的事件抽取任务的方法,希望能对大家有所帮助。同时,我们这次的介绍将分上下两部分,下部分将在之后的公众号进行推文,主要介绍的是一篇 zero-shot 方法在 event extraction 的使用,以及整个事件推理的专题。近年来事件推理逐渐引起注意,包括事理图谱构建、common sense level 的事件起因和反应的推理,事件因果关系推理,事件时序关系等等都将在下一次的推文中进行详细介绍。
参考文献:
1. Huang L, Ji H,Cho K, et al. Zero-Shot Transfer Learning for Event Extraction[J]. arXiv preprint arXiv:1707.01066, 2017.
2. Ahn D. The stages of event extraction[C]//Proceedings of the Workshop on Annotating and Reasoning about Time and Events. Association for Computational Linguistics,2006: 1-8.
3. Hogenboom F,Frasincar F, Kaymak U, et al. An overview of event extraction from text[C]//Workshop on Detection, Representation, and Exploitation of Events in the Semantic Web (DeRiVE 2011) at Tenth International Semantic Web Conference(ISWC 2011). Koblenz, Germany: CEUR‐WS. org, 2011, 779: 48-57.
4. Zhang T, Ji H.Event Extraction with Generative Adversarial Imitation Learning[J]. arXiv preprint arXiv:1804.07881, 2018.
5. Chen Y, Xu L,Liu K, et al. Event extraction via dynamic multi-pooling convolutional neural networks[C]//Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on NaturalLanguage Processing (Volume 1: Long Papers). 2015, 1: 167-176.
6. Liu S, Chen Y,Liu K, et al. Exploiting argument information to improve event detection viasupervised attention mechanisms[C]//Proceedings of the 55th Annual Meeting ofthe Association for Computational Linguistics (Volume 1: Long Papers). 2017, 1:1789-1798.
7. Event extraction from text.Liu Kang, 2017
8. Huang L, CassidyT, Feng X, et al. Liberal event extraction and event schema induction[C]//Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2016, 1: 258-268.
9. Feng X, Qin B,Liu T. A language-independent neural network for event detection[J]. Science China Information Sciences, 2018, 61(9): 092106.
10. Lin H, Lu Y, HanX, et al. Nugget Proposal Networks for Chinese Event Detection[J]. arXiv preprint arXiv:1805.00249, 2018.
OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。



