超越99.9%人类玩家,微软专业十段麻将AI论文细节首次公布
机器之心编辑部
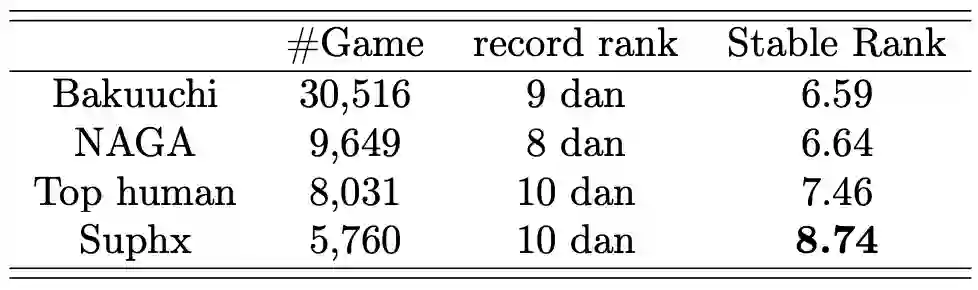
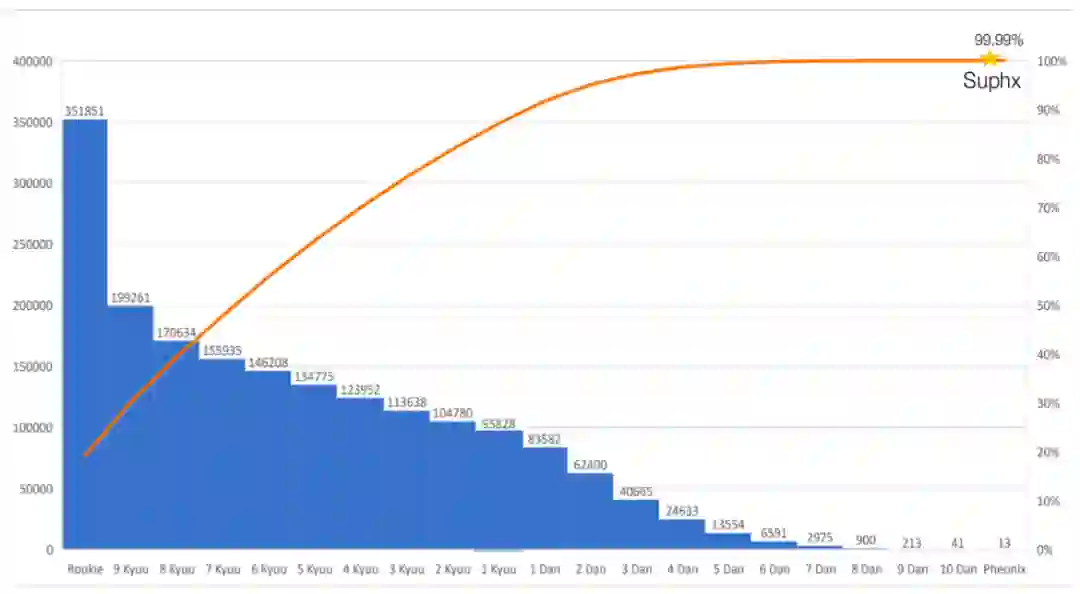
在去年 8 月底的世界人工智能大会上,时任微软全球执行副总裁的沈向洋正式对外宣布了微软亚洲研究院研发的麻将 AI「Suphx 」。近日,关于 Suphx 的所有技术细节已经正式公布。


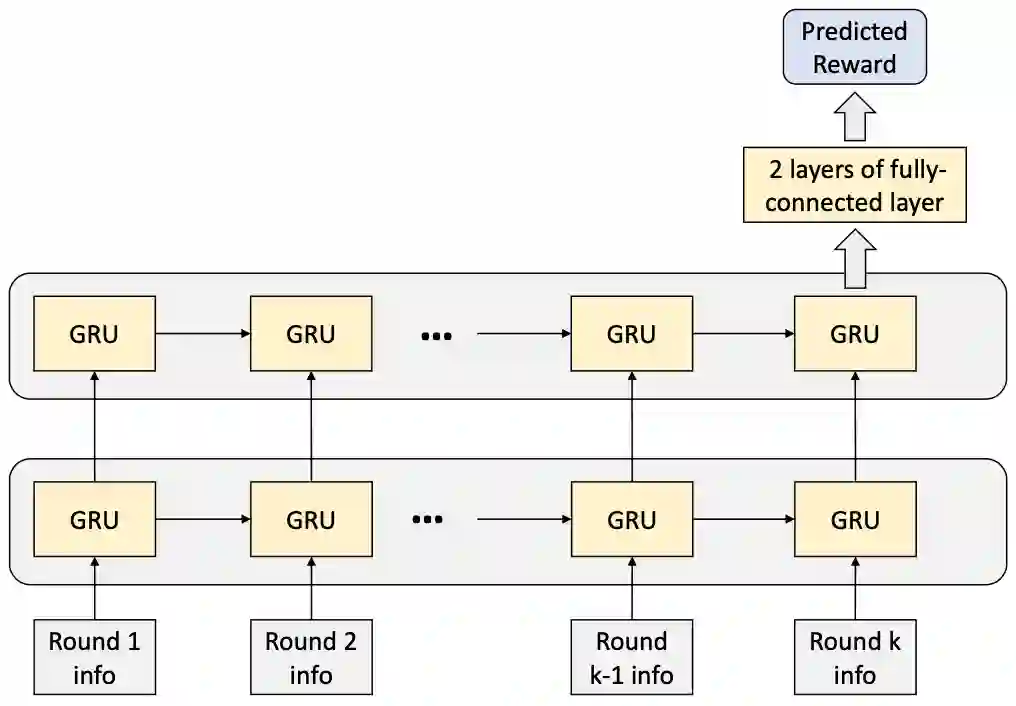
全局奖励预测用来训练一个预测器,进而根据当前和先前回合的信息来预测游戏的最终奖励。该预测器提供有效的学习信号,从而可以执行策略网络的训练。此外,研究者还设计了预读(look-ahead)特征,以便对不同必胜手牌(winning hand)的可能性以及回合内的获胜分数进行编码,从而支持 RL 智能体的决策;
Oracle guiding 引入了一个 oracle 智能体,它能够查看包括其他玩家私有牌(private title)和 wall title 在内的完美信息。得益于完美的信息访问,该 oracle 智能体成为超级强大的麻将 AI。在 RL 训练过程中,研究者逐渐从 oracle 智能体中删除完美信息,最后将其转换为仅将可观察信息作为输入的常规智能体。在 oracle 智能体的帮助下,与仅利用可观察信息的标准 RL 训练相比,常规智能体的提升速度要快得多;
由于麻将的复杂游戏规则导致了不规则的博弈树,并且限制了蒙特卡洛树搜索(Monte-Carlo tree search)方法的应用,所以研究者提出以蒙特卡洛策略调整(Monte-Carlo Policy Adaptation,pMCPA)来提升智能体的运行时性能。当游戏继续进行并且可观察更多信息时,pMCPA 能够逐渐地修正和调整离线训练策略,从而适应在线比赛阶段的特定回合。


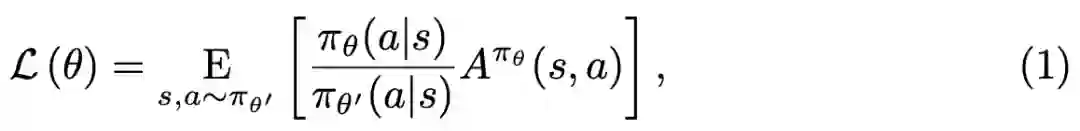
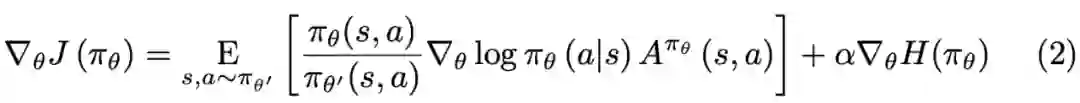
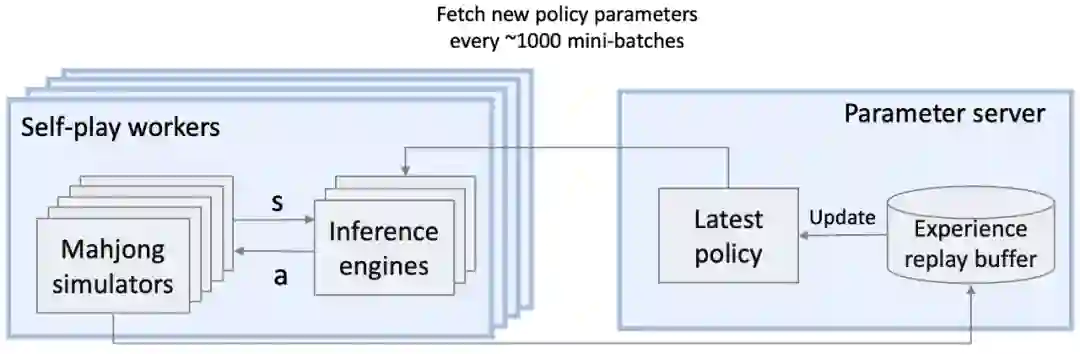
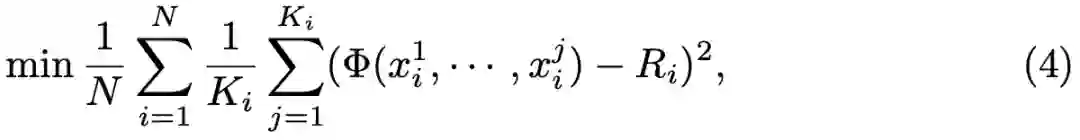
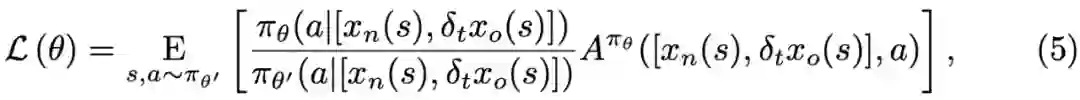
模拟。随机采样另外三个对手的私有牌和排除了自身私有牌后的所有牌,使用离线预训练的策略进行 rollout,并完成整个环境轨迹的探索。于是,总共会产生 K 条轨迹;
调整。使用 rollout 产生的轨迹进行梯度更新,以此微调离线策略;
推断。在本局中使用微调后的策略与其他玩家进行对弈。
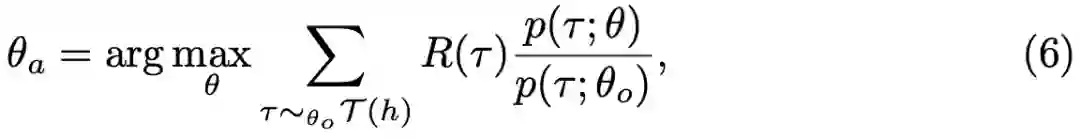
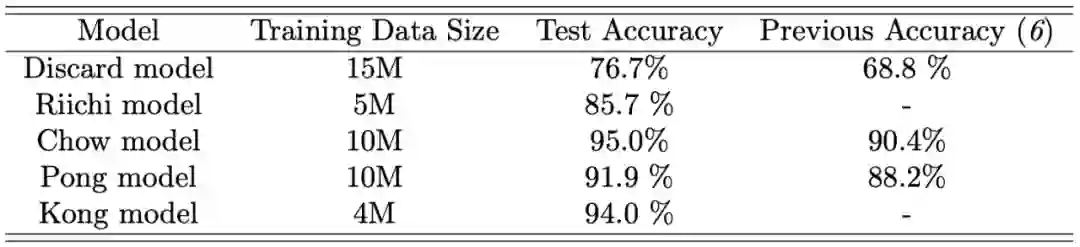
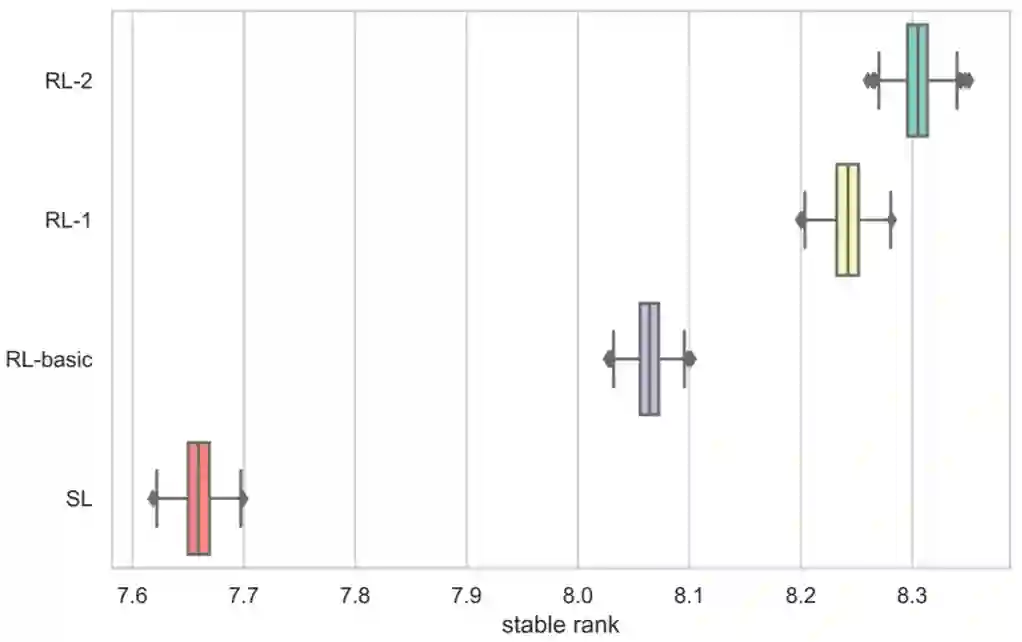
SL:监督学习智能体,如上节所述,该智能体(所有五个模型)都受到监督训练。
SL-weak:训练不足的 SL 智能体版本,在评估其他智能体时可作为对比模型。
RL-basic:强化学习智能体的基础版本。在 RL-basic 中,discard 模型用 SL discard 模型进行初始化,然后通过策略梯度方法进行迭代,以回合得分作为奖励以及熵正则化用。Riichi、Chow、Pong 和 Kong 的模型与 SL 智能体的模型相同。
RL-1:这个 RL 智能体通过全局奖励预测增强 RL-basic。奖励预测器使用了来自天凤的游戏日志,通过监督学习进行训练。
RL-2:该智能体通过 oracle guiding 进一步增强 RL-1。在 RL-1 和 RL-2 中,仅用 RL 训练了 discard 模型,而其他四个模型则与 SL 智能体相同。