安防新算法解读:旷视科技提出 RepLoss,优化解决密集遮挡问题

AI掘金志出品
雷锋网旗下只报道“AI+传统”的内容频道
全球计算机视觉顶会 CVPR 2018(Conference on Computer Vision and Pattern Recognition,即 IEEE 国际计算机视觉与模式识别会议)将于 6 月 18 日至 22 日在美国盐湖城举行。作为大会钻石赞助商,旷视科技 Face++研究院也将在孙剑博士的带领下重磅出席此次盛会,本次旷视共有 1 篇 spotlight 论文,7 篇 poster 论文,在雷锋网旗下学术频道 AI 科技评论旗下数据库项目「AI影响因子」中有突出表现。而在盛会召开之前,旷视将针对 CVPR 2018 收录论文集中进行系列解读。本次第 3 篇主题是可优化解决人群密集遮挡问题的 RepLoss。
论文链接:https://arxiv.org/abs/1711.07752
目录
导语
RepLoss 设计思想
密集遮挡的影响
RepLoss 计算方法
吸引项
排斥项(RepGT)
排斥项(RepBox)
RepLoss 实验结果
结论
参考文献
导语
人群检测是计算机视觉技术发展不可绕过的关键一环,其中密集遮挡(crowd occlusion)问题是最具挑战性的问题之一。旷视科技 Face++从技术底层的层面提出一种全新的人群检测定位模型 Repulsion Loss(RepLoss),在相当程度上优化解决了这一难题。底层技术创新的适用范围异常广泛,这意味着绝大多数与人群检测相关的产品应用皆可实现不同程度的提升,从根本上推动安防监控、自动驾驶、无人零售、智慧城市的落地和发展。此外,人群定位技术 RepLoss 的检测对象并不仅限于人,还可迁移泛化至一般物体检测,其底层创新驱动力的波及范围十分广泛,有助于机器之眼打造一个人、物、字、车的检测矩阵,进一步看清楚、看明白这个世界。
RepLoss 设计思想
检测人群之中的行人依然是一个充满挑战性的问题,因为在现实场景中行人经常聚集成群,相互遮挡。一般而言,物体遮挡问题可以分为类内遮挡和类间遮挡两种情况。类间遮挡产生于扎堆的同类物体,也被称为密集遮挡(crowd occlusion)。在行人检测中,密集遮挡在所有遮挡问题中占比最大,严重影响着行人检测器的性能。
密集遮挡的主要影响表现在显著增加了行人定位的难度。比如,当目标行人 T 被行人 B 遮挡之时,由于两者外观特征相似,检测器很可能无法进行定位。从而本应该框定 T 的边界框转而框定 B,导致定位不准确。更糟糕的是,由于非极大值抑制(non-maximum suppression/NMS)需要进一步处理主要的检测结果,从 T 移走的边界框可能会被 B 的预测框抑制,进而造成 T 漏检。即,人群遮挡使得检测器对 NMS 阈值很敏感:较高的阈值会带来更多的误检(false positives),较低的阈值则造成更多的漏检(missed detection)。这会让大多数实例分割框架失效,因为它们也需要精确的检测结果。因此,如何精确地定位人群之中的每个行人是检测器最为关键的问题之一。
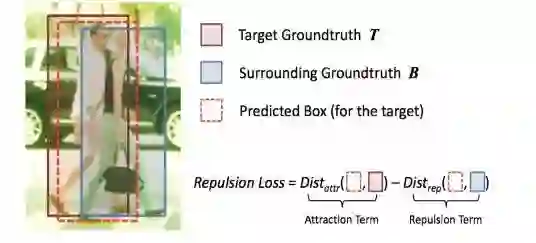
图 1:RepLoss 图示。
在当前最优的检测框架中,边界框回归技术常用来定位物体,其中回归器被训练用来缩小 proposal 和 groundtruth box 之间的差距(通过一些距离度量进行测量,比如 Smooth_L1 或者 IoU)。尽管如此,现有方法只需要 proposal 接近其指定目标,并不考虑周遭的物体。如图 1 所示,在标准的边界框回归损失中,当预测框移向周遭物体时,对其并没有额外的惩罚。这不免使人设想:如果要检测人群之中的一个目标,是否应该考虑其周遭物体的定位?
在磁极相互排斥吸引的启发下,本文提出一种全新的定位技术,称之为 Repulsion Loss(RepLoss),通过它,每一个 proposal 不仅会靠近其指定目标 T,还会远离其他 groundtruth 物体以及指定目标不是 T 的其他 proposal。如图 1 所示,由于与周遭的非目标物体重叠,红色边界框移向 B 将受到额外的惩罚。因此,RepLoss 可以有效防止预测边界框移向相邻的重叠物体,提升检测器在人群场景中的鲁棒性。
密集遮挡的影响
本节将借助实验探讨当前最优的行人检测器如何受到密集遮挡(crowd occlusion)的影响,更加深入地理解密集遮挡问题。密集遮挡主要会造成两个方面的问题,漏检和误检,下面会通过两个图示分别作出解释,其中基线检测器是针对行人检测优化的 Faster R-CNN,并使用新型行人检测数据集 CityPersons。
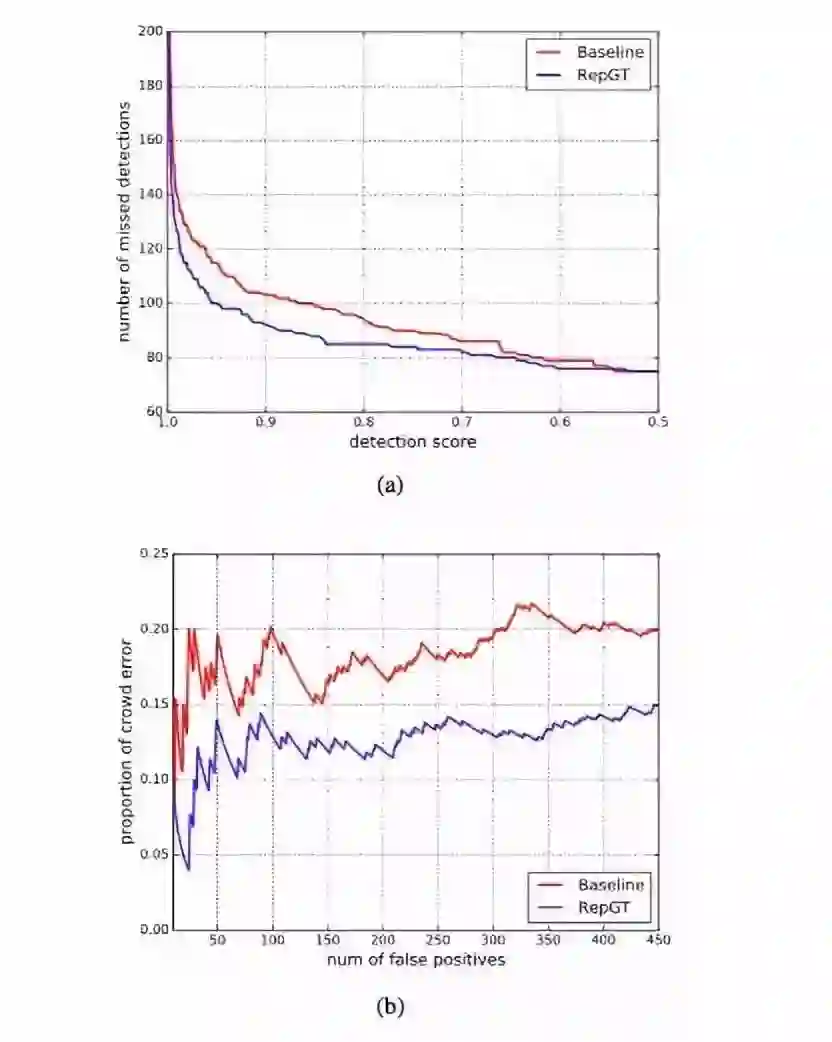
图 3:基线与 RepGT 的错误检测分析。
图 3(a) 是不同检测分值下在 reasonable-crowd 子集上的漏检数量,红线表示基线的 groundtruth 行人漏检数量。在现实应用中,只考虑带有高置信度的预测边界框,曲线左端的高漏检量意味着离实际应用还很远。图 3(b) 表示由密集遮挡导致的误检占全部误检的比例,红线表明基线的这一比例大概在 20% 左右。如图 3 红、蓝线对比所示,RepGT 损失分别有效降低了由密集遮挡造成的漏检和误检数量。

图 4:错误检测的可视化实例。红框表示由密集遮挡引起的误检。
如图 4 所示,绿框是正确的预测边界框,而红框是由密集遮挡造成的误检,并给出了检测器的置信值。如果预测框轻微或显著移向相邻的非目标 groundtruth 物体(比如右上图),或者框定若干个彼此遮挡物体的重叠部分(比如右下图),则经常出现检测错误。此外,密集遮挡引起的检测错误通常有着较高的置信度,从而造成高排名的误检。这表明为提高检测器在密集场景中的鲁棒性,需要在执行边界框回归时有更具判别力的损失。下面是另一个可视化实例:

图 9:基线与 RepLoss 的对比。蓝框表示误检,红框表示漏检。灰色虚线上、下两部分的第一行是基线的预测结果;第二行是添加 RepLoss 之后的预测结果。
通过分析错误检测表明,密集遮挡对行人检测器的影响令人吃惊,不仅是漏检的主要来源,还在增加定位难度的同时造成了更多的误检。正是为解决上述问题,提升行人检测器在密集场景中的鲁棒性,RepLoss 被提了出来。
RepLoss 计算方法
本节将详述如何计算 RepLoss。受到磁石属性的启发,RepLoss 包括 3 个组件,表示为:
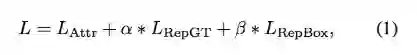
其中 L_Attr 是吸引项,需要预测框靠近其指定目标;L_RepGT 和 L_RepBox 是排斥项,分别需要预测框远离周遭其他的 groundtruth 物体和其他指定目标不同的预测框。系数 α 和 β 充当权重以平衡辅助损失。
为简明起见,下面仅考虑两类检测,假定所有的 groundtruth 物体属于同一类别。分别使 P = (l_P,t_P,w_P,h_P) 和 G = (l_G, t_G, w_G, h_G) 为 proposal 边界框和 groundtruth 边界框,并分别由它们的左上点坐标及其高度、宽度表示。P_+ = {P} 是所有 positive proposal 的集合(那些和至少一个 groundtruth box 有高 IoU 的被视为正样本,反之为负样本);G = {G} 是一张图片中所有 groudtruth box 的集合。
吸引项
本文沿用 Smooth_L1 构造吸引项。给定一个 proposal P ∈ P_+,把具有极大值 IoU 的 groundtruth box 作为其指定目标:G^P_Attr = arg max_G∈G IoU(G,P)。B^P 是回归自 proposal P 的预测框。由此吸引损失可计算为:
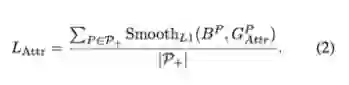
排斥项(RepGT)
RepGT 损失旨在使 proposal 受到相邻的非目标 groundtruth 物体的排斥。给定一个 proposal P ∈ P_+,它的排斥 groundtruth 物体被定义为除了其指定目标之外带有最大 IoU 区域的 groundtruth 物体。受 IoU 损失的启发,RepGT 损失被计算以惩罚 B^P 和 G^P_Rep 之间的重叠(由 IoG 定义)。IoG(B, G) ∈ [0, 1],从而 RepGT 损失可写为:
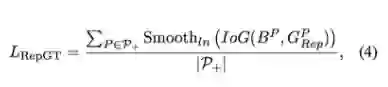
其中 Smooth_ln 是一个在区间 (0, 1) 连续可微分的平滑 ln 函数,σ ∈ [0, 1) 是调节 RepLoss 对异常值的敏感度的平滑参数。由此可见,proposal 越倾向于与非目标 groundtruth 物体重叠,RepGT 损失对边界框回归器的惩罚就越大,从而有效防止边界框移向相邻的非目标物体。
排斥项(RepBox)
NMS 是绝大多数检测框架中不可或缺的后处理步骤,为降低检测器对 NMS 的敏感度,作者接着提出 RepBox 损失,意在排斥来自不同指定目标的 proposal。RepBox 损失可计算为:
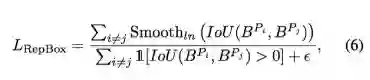
从上式可以看到,为最小化 RepBox 损失,指定目标不同的两个预测框之间的 IoU 区域需要较小。这意味着 RepBox 损失可以降低 NMS 之后不同回归目标的边界框合并为一的概率,使得检测器在密集场景中更鲁棒。
RepLoss 实验结果
本节将直接给出 RepLoss 在数据集 CityPersons 和 Caltech-USA 上的评估结果,包括在 CityPersons 上分别评估和分析 RepGT 损失 和 RepBox 损失;在 CityPersons 和 Caltech-USA 上把 RepLoss 与当前最优的方法相对比。实验设置和实现细节从略,了解更多请参见原论文。
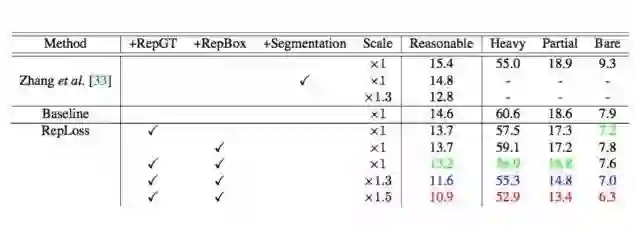
表 3:在 CityPersons 上评估的 RepLoss 行人检测结果。模型在训练集上训练,并在验证集上测试。ResNet-50 是 backbone。最佳的 3 个结果分别标为红、蓝、绿色。
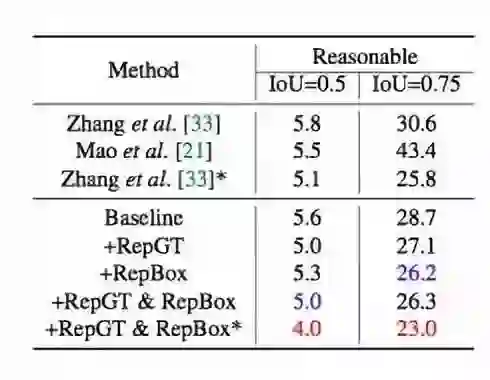
表 4:在新注释中评估的 Calech-USA 测试集 (reasonable) 结果。在 0.5 IoU 阈值下,作者进一步在强基线上把当前最优推进到显著的 4.0 MR^−2。当把 IoU 阈值增至 0.75,持续的涨点证明了 RepLoss 的有效性。

图 7:在基线和 RepBox 的 NMS 之前的预测框可视化对比。RepBox 结果中两个相邻的 groundtruth 之间的预测较少,模型输出的边界框的分布更加明晰。

图 10:更多的 CityPersons 数据集检测实例。绿框中是预测的行人,其分值 ([0, 1.0]) 大于 0.8。
结论
RepLoss 专为行人检测精心设计,尤其提升了密集场景的检测性能,其主要想法在于目标物体的吸引损失并不足以训练最优的检测器,来自周遭物体的排斥损失同样至关重要。
为充分发挥排斥损失的潜能,本文提出 RepGT 和 RepBox,并在流行数据集 CityPersons 和 Caltech-USA 上取得了当前最优水平。特别是,本文结果在未使用像素注释的情况下优于使用像素注释的先前最佳结果大约 2%。详细的实验结果对比证实了 RepLoss 在大幅提升遮挡场景下检测精度方面的价值,并且一般的物体检测 (PASCAL VOC) 结果进一步表明了其有效性。作者希望 RepLoss 在诸多其他物体检测任务中也有更为广泛的应用。
参考文献
[1]Dollar, C. Wojek, B. Schiele, and P. Perona. Pedestrian detection: A benchmark. In IEEE Computer Vision and Pattern Recognition, 2009.
[2]K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In IEEE Conference on Computer Vision and Pattern Recognition, 2016.
[3]J. Mao, T. Xiao, Y. Jiang, and Z. Cao. What can help pedestrian detection? In IEEE Conference on Computer Vision and Pattern Recognition, 2017.
[4]S. Ren, K. He, R. Girshick, and J. Sun. Faster r-cnn: Towardsreal-time object detection with region proposal networks. In NIPS, 2015.
[5]J. Yu, Y. Jiang, Z. Wang, Z. Cao, and T. Huang. Unitbox: An advanced object detection network. In Proceedings of the 2016 ACM on Multimedia Conference.
[6]S. Zhang, R. Benenson, and B. Schiele. Citypersons: A diverse dataset for pedestrian detection. In IEEE Conference on Computer Vision and Pattern Recognition, 2017.
长按二维码,关注雷锋网旗下「AI掘金志」