细节决定成败: 推荐系统实验反思与讨论

近些年来,随着互联网的迅速发展,用户在各种在线平台上接收到海量的信息,信息爆炸成为一个关键性问题。在此背景下,推荐系统逐步渗透到人们工作生活的各个场景,已成为不可或缺的一环。它不仅可以帮助用户快速获得想要的信息和服务,还可以提高资源利用效率,从而给企业带来更多效益。因此,个性化推荐算法不仅获得了工业界广泛的关注,也是科研领域的研究热点之一。
http://jcs.iie.ac.cn/xxaqxb/ch/reader/create_pdf.aspx?file_no=20210504&flag=1&year_id=2021&quarter_id=5
欢迎干货投稿 \ 论文宣传 \ 合作交流
推荐阅读
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。
登录查看更多
相关内容

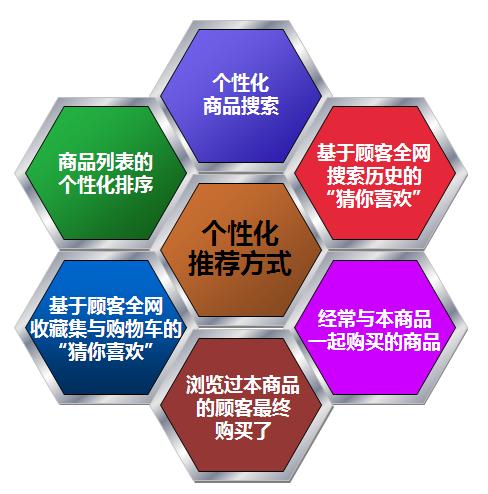
推荐系统,是指根据用户的习惯、偏好或兴趣,从不断到来的大规模信息中识别满足用户兴趣的信息的过程。推荐推荐任务中的信息往往称为物品(Item)。根据具体应用背景的不同,这些物品可以是新闻、电影、音乐、广告、商品等各种对象。推荐系统利用电子商务网站向客户提供商品信息和建议,帮助用户决定应该购买什么产品,模拟销售人员帮助客户完成购买过程。个性化推荐是根据用户的兴趣特点和购买行为,向用户推荐用户感兴趣的信息和商品。随着电子商务规模的不断扩大,商品个数和种类快速增长,顾客需要花费大量的时间才能找到自己想买的商品。这种浏览大量无关的信息和产品过程无疑会使淹没在信息过载问题中的消费者不断流失。为了解决这些问题,个性化推荐系统应运而生。个性化推荐系统是建立在海量数据挖掘基础上的一种高级商务智能平台,以帮助电子商务网站为其顾客购物提供完全个性化的决策支持和信息服务。
Arxiv
24+阅读 · 2021年9月20日
A Survey of Reinforcement Learning Techniques: Strategies, Recent Development, and Future Directions
Arxiv
80+阅读 · 2020年1月19日



相关VIP内容
相关资讯
相关论文
Arxiv
24+阅读 · 2021年9月20日
A Survey of Reinforcement Learning Techniques: Strategies, Recent Development, and Future Directions
Arxiv
80+阅读 · 2020年1月19日