人工智能新技术:联邦学习的前世今生


文章作者:彭南博、王虎
内容来源:JDD风控算法
导读 1
联邦学习(Federated Learning)作为人工智能的一个新分支,为机器学习的新时代打开了大门。JDD风控算法团队将通过联邦学习白话三部曲,为大家揭秘联邦学习的前世今生。
本段为您解读:
1. 联邦学习为什么这么热?
2. 联邦学习能做什么?
3. 三合一速成法则告诉你联邦学习是什么?
4. “百万富翁”带你揭秘如何直观理解隐私保护技术?
5. 联邦学习会损害模型效果吗?

如果投票问人工智能和大数据应用领域有什么好玩又好用的新技术,“联邦学习”一定是排在前列的。这项技术由谷歌在2016年首次提出,从2018年8月开始在国内快速发展和普及,截至2020年2月,有公开资料可查的联邦学习研究或应用单位已超过百家,阿里、微众、京东、腾讯、华为、平安等各领域的头部企业均在大力推进。身边做技术和业务的朋友都在说:忽如一夜春风来,联邦学习突然就在圈子里传播了,在聊天中不发表点联邦学习的看法都不好意思。
第一个问题是,为什么联邦学习会突然冒出来、如此受欢迎呢?我们认为有以下几个重要的触发因素。
(1)在谷歌提出联邦学习之前,欧盟就在探讨移动互联网的隐私数据保护问题,于2016年4月通过了《通用数据保护条例》,并于2018年5月强制实施,严格约束了个人隐私数据的收集、传输、保留和处理。才过半年,谷歌即被罚款5000万欧元,因为其收集和使用用户数据触犯了该条例。在中国,数据保护的法规也在不断完善。例如,全国信息安全标准委员会先后于2017年12月和2020年3月发布了两版《信息安全技术个人信息安全规范》,对个人信息收集、储存、使用作出了明确规定。大家应该还记得,在2019年10月份,几乎每个APP都在更新用户授权协议,令人不胜其烦,这就是因为相关法规趋严导致的。国内外隐私保护法规的不断完善,使得移动互联网的企业决策者不得不重新规划未来的战略方向。这是因为移动互联网的生态价值在于其海量的用户数据,如果数据不能用于生产,整个行业将受到巨大损失和挫折。

(2)中国特色的市场环境促进了基于移动互联网的数字经济爆发式的发展,通过改善人们生产生活体验,数字经济获得快速增长并达到世界领先。例如,电商服务让我们足不出户买到生活物资,让购物更便捷、更省时间,特别是解决了出门难人群的采购难题;互联网金融实现了线上快速的风险评估和金融服务,解决了广大民众日常急用的借款需求;移动医疗使得远程问诊技术普惠大众,让患者可便捷地得到专家的指点,同时也极大地缩短了挂号、缴费等“排长队”流程的时间;个性化资讯、短视频、直播等新媒体内容极大地丰富了娱乐生活和社交,使得欢声笑语越来越多了。2018年我国数字经济总量达31万亿,GDP占比达34.8%,数字经济已成为带动我国国民经济发展的核心组成。数字经济的关键在于数据和大数据分析技术。数据作为原料,大数据分析技术蒸馏出有价值的信息,进而帮助用户更快地找到需要的商品和媒体服务、为优质用户提供低息贷款、更准确的诊断疾病。在此次应对疫情的防控保卫战中,大数据正发挥着越来越大的作用,在科技助力下,相关部门可以尽早发现疑似病患、密切接触者,有助于及时隔离、切断传染源。然而,由于上述国内外数据隐私保护法规的推出,互联网数据分散在不同企业或者终端形成“数据孤岛”,不能直接共享或者交换,因此我们急需破解数据孤岛的技术。

在数据隐私安全保护需求和破解数据孤岛需求的背景下,联邦学习应时而生。它能够实现在不泄露隐私数据的情况下实现企业间的数据融合建模,成为解决上述问题的首选技术。如此实用的技术发展之迅速,普及之广泛,不足为奇。
上面介绍了联邦学习的现状和用途,下面回答联邦学习是什么?与其他技术的区别在哪里?
从技术角度看,联邦学习是一种隐私保护的分布式机器学习技术,包括机器学习、分布式、隐私保护三个技术关键词。对这三种技术的研究已有几十年历史,但直到近年来,它们在工业实践中才做到真正结合并蓬勃发展。

第一个关键词是机器学习,它是计算机从数据中寻找统计规律的过程,用于像人一样解决不确定性问题,比如在不同光照条件下判断出熟人及其名字(人脸识别)、依据对某人历史行为的评估决定是否借钱给他(风控准入建模)以及借多少(授信额度建模)等等。人的学习过程是从书本、老师以及实践探索中不断积攒经验,成为具有“智慧”的个体;机器学习与此略有不同,它的经验来源于大量的数据,接受某个领域的数据便可成训练成为该领域的“智能体”,例如,大量的人脸图像可以训练出人脸识别或身份认证系统。利用数据获得经验的过程称之为建模;利用经验对新数据做出估计或者预测的过程称之为推理。
机器学习可解决数字经济中的诸多问题,比如说克服因服务人员经历不足或情绪不佳影响产生的偏见和歧视。这是因为在大数据时代,机器学习可获得更加全面的数据和经验,据此提升社会服务的公正性。机器学习无需人工干预即可实现智能服务,因此还可以大幅提高生产效率。例如在618购物节中,京东智能客服7*24小时不间断地为数亿用户解答疑问,这是传统人工客服团队不可能做到的。
第二关键词是分布式,是指数据被分为若干份,各份数据的存储和计算都分布在不同位置。其中,不同位置包括不同的用户终端或者企业服务器。像手机、平板电脑这样的用户终端已逐渐成为人们生活的必需品,被广泛用于社交、获取新闻资讯、记录备忘、消遣消费等,其用户日均使用时长达到5小时(2018年移动互联网报告)。随着使用时间的增加,用户终端存储了大量的隐私数据,包括朋友聊天记录、浏览记录、日程安排、照片视频等。不夸张地说,这些数据从不同侧面展示了一个“数字化的你”。

数字化的好处在于让计算机更“懂你”,进而提供贴心的服务,例如推荐最想买的商品、找回遗忘的资料等。数字化的坏处在于隐私泄露,2019年央视3-15晚会就介绍了个人隐私信息通过手机App泄露的案例。因此,法规一般要求这些数据在非授权情况下只能存储在用户终端,或者授权情况下存储在对应的企业服务器,禁止泄露给第三方。在不传输隐私数据的前提下,分布式的机器学习可以使用存储在不同终端或者企业的数据,例如谷歌的GBoard移动键盘团队使用分布在150万用户终端的6亿个句子提升了手机输入法预测下一词的准确性,这让用户可以快速输入脑海中的字词,也能联想到新出现的流行词、缩写词等。通过这种分布式的方法,我们可以让用户享受大数据带来的良好体验,同时又能避免隐私数据的传输。
第三个关键词是隐私保护,它是防止恶意攻击的盾牌。分布式的机器学习可以使用分布在不同终端或者企业的数据,虽然不会直接传输用户隐私数据,但是黑客(恶意的联邦成员)可以使用一些特殊的破解技术,利用建模阶段所需的大量中间值,推算出对应的原始数据,进而窃取联邦内的用户隐私。
隐私保护技术的主要思想是对训练过程的中间结果进⾏某种变换,以掩盖原始数据或改变其数据特性,⽐如连续性、分布规律等,从⽽使得恶意联邦成员的破解技术失效,同时还能保证诚实的联邦成员依然可以从数据中学习到经验。就相当于数据提供方将数据放入保险箱中进行传输,其他联邦成员无法打开箱子看到真实数据,但却可以在不解锁的情况下,对保险箱中的数据完成训练所需的操作;当训练完成后,数据提供方再开箱取出计算结果即可。这种理想的功能需要我们使用特殊的技术进行实现,其中常⽤技术包括差分隐私、同态加密等。简单来说,差分隐私对数据加上一定程度的随机噪声,例如将年龄从50改为46(-4)或者51(+1),这可使得某些破解技术失效;同态加密是将数据变换到另一个数域的技术,新数域的大小顺序、分布都会发生变化,所以不可能被破解出原始数据。
因此,联邦学习是机器学习、分布式、隐私保护三合一的交叉技术。与现有的分布式机器学习不同,联邦学习主要受制于原始数据分布在不同位置的严格约束,不能有任何泄露原始数据的风险,隐私保护技术是防止泄露的关键。
这里我们以“百万富翁”设想为例,简单直观地说明隐私保护技术的需求和解决方案。这是个非常经典有名的案例,是由计算机界最有名的姚期智院士于1982年提出的数学难题。有意思的是,这个问题引发了更多的相关研究,并逐渐发展成为密码学的一个重要分支。“百万富翁问题”是这样的:两个争强好胜的富翁A和B在街头相遇,如何在不暴露各自财富的前提下比较出谁更富有?

这个问题的难点在于,两个富翁都不想暴露自己的财富数量,既不想直接告诉对方也不愿借助第三方机构的帮助。如何直观地解决这个问题?我们可以参考一种“变换”的方法。假设两个富翁(A和B)的财富都在 10 B$(100亿美元)以内,则我们可以简单地用十个盒子比较出A和B谁的财富更多。
首先,由A进行如下操作:给盒子贴上编号,并按照财富值放入水果,放置规则如下:如果编号等于财富值的盒子放入橙子,编号小于财富值的盒子放入苹果,编号大于财富值的盒子放入香蕉。假设A 的财富是3 B$,则放置结果如图所示。

然后,A给所有盒子上相同的锁(即要求开锁的钥匙是一样的,依靠钥匙不能辨别盒子的编号)。这里将财富值“变换”为锁在盒子里的水果,本质是一个加密过程。

接下来A下场、B上场,B知道A的操作是编号、放水果、上锁,但是不知道每个盒子装了什么水果。B要做的是选择与自己财富对应的盒子去除编号,并销毁其他盒子。这里去除编号的目的在于让A不知道B选择了哪个盒子,从而避免泄露B的财富数量。
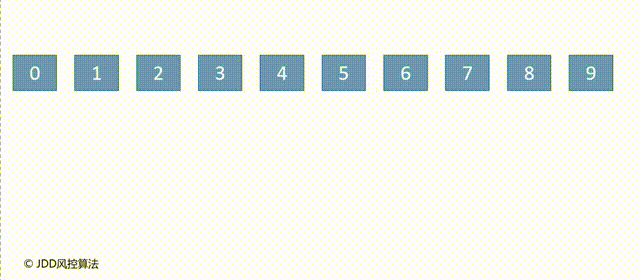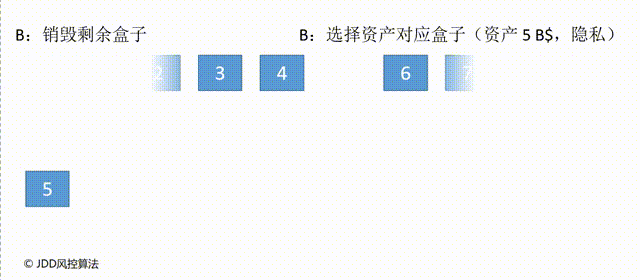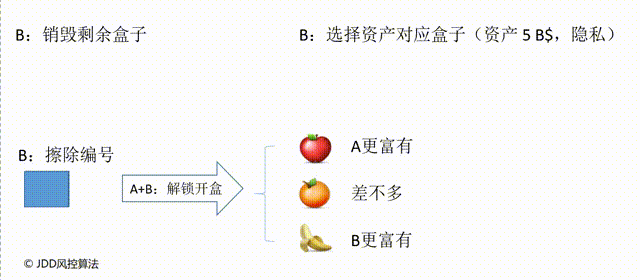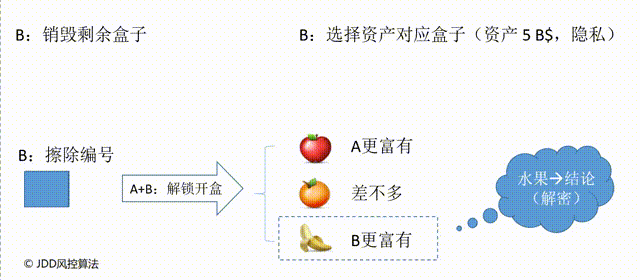
最后,A和B同时上场,由A开锁打开剩下的无编号的盒子,这个盒子里对应的水果就能推断出谁更富有。这里基于水果推测结果,本质是一种解密过程。假设B的资产是5 B$,则打开盒子获得香蕉,表明B更富有;假设B的资产是2 B$,则获得苹果表明A更富有;假设B的资产是3 B$,则获得橙子表明A和B的财富是差不多的。通过这几个步骤,A和B都没有向任何人泄露自己的财富数量,但成功实现比较,这就是一种隐私保护的比较计算技术。
也许有读者会问,在这个解决方案中,B可以通过顺次比较的方式,最多9次就能破解A的财富是多少了。确实如此,这主要是因为这里只用到10个盒子,而我们可以通过增加盒子数量的方式增加破解的难度。在实际操作过程中,一般采用基于数论的密码学技术,这种技术的破解难度非常大,即使用最先进的计算机可能也需要数百年才能破解。
在与其他团队进行技术交流时,我们发现很多朋友对联邦学习存在主观偏见:联邦学习的主要作用是合规地共享数据能力而不泄露用户隐私,依据经验和“没有免费的午餐”定律,隐私保护会损害机器学习的模型效果(例如预测准确性或排序性)。事实正好相反,联邦学习并不会损害模型效果,反而能够从如下两个方面提高业务模型的效果。
一方面,联邦学习理论上是可以获得最优解的,通过梯度下降迭代过程,可以实现联邦间的特征组合和交叉建模,从而解决如“异或”这样的非线性问题,这等价于把数据拼到一起后进行机器学习的效果。异或问题如下表所示:
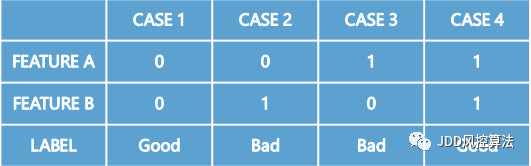
注:“Bad” 例如不守信用的老赖
传统的子模型法为了控制数据泄露的风险,往往只能带少量样本的标签(Label)到其他企业建模,然后融合双方子模型的输出分获得最终决策,这就如同盲人摸象每次只能看到一个侧面,效果难以达到最佳。对于上述异或问题,子模型发现无论特征(Feature)是“0”还是“1”,标签分别是“Bad”和“Good”的比例都是差不多的,因此子模型的判断准确率只有50%,这和扔硬币方式的猜测差不多。相比之下,联邦学习可以建立如下图所示的决策树模型,有效地解决异或问题的判断,准确率从50% 提高到100%。
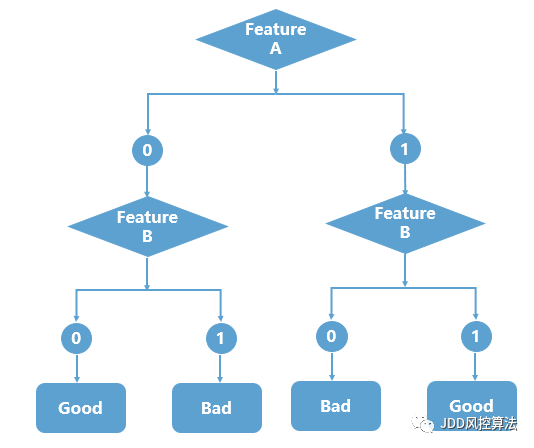
图 联邦决策树判别“异或”问题
另一方面,联邦学习由于能够保护数据隐私安全,因此无需限制建模样本的数量。也就是说,联邦学习可以使用更多的数据建模,因而能够基于大数据更有效地发现数据规律,提高模型效果。
上述两个方面从理论上表明,联邦建模效果优于传统子模型法。在行业实践的一个包含2家企业的联邦POC验证中,联邦学习相比于单侧模型的效果提升了13%,相比于传统子模型法也有4%的提升。也许有人质疑4%的相对提升并不高,但是,移动互联网市场环境表明,随着拓新增量市场见顶,流量红利耗尽,存量市场的竞争将变得异常激烈,对于存量市场的精细化运营成为企业赖以生存和发展的依靠,每一点提升都将具有重要意义。此外,这仅仅是2家企业联邦的效果,随着联邦成员数量增加,联邦模型具有更多、更互补的视角,效果将会获得更大的提升。
参考文献
[1] Andrew Hard et., al. Federated Learning for Mobile Keyboard Prediction, https://arxiv.org/abs/1811.03604
[2] Qiang Yang et., al. Federated Machine Learning: Concept and Applications. ACM TIST2019. https://arxiv.org/abs/1902.04885
[3] Federated Learning: Collaborative Machine Learning without Centralized Training. https://ai.googleblog.com/2017/04/federated-learning-collaborative.html
[4] Kewei Cheng, Qiang Yang et., al. SecureBoost: A Lossless Federated Learning Framework. https://arxiv.org/abs/1901.08755
[5] 刘洋, 范涛. 联邦学习的研究与应用. https://img.fedai.org.cn/fedweb/1553845987342.pdf
[6] Tian Li et., al. Federated Learning: Challenges, Methods, and Future Directions. https://arxiv.org/abs/1908.07873
[7] 飞向未来的埃舍尔. 联邦学习/联盟学习的发展现状及前景如何?https://www.zhihu.com/question/329518273/answer/717840293
在移动互联网时代,基于大数据的智能技术让我们的生活更便捷、娱乐更丰富、生产更高效,唯一不足在于潜在的隐私泄露。在隐私数据保护相关法规推动下,联邦学习如雨后春笋般在各大企业快速成长,成为解决隐私数据保护和数据共享矛盾的关键技术。本篇从联邦学习的基本组成、直观认识和准确性详细剖析了联邦学习技术,后续我们将继续与大家探讨联邦学习的应用前景、当前难点、技术原理和实施方案。
未完待续,敬请关注。
导读 2
上段内容回顾:
本段为您解读:
2. 联邦学习应用部署难点和趋势
3. 联邦学习的具体实施方法

广播、电视、互联网的相继出现,时空距离骤然缩短,世界紧缩成一个“地球村”,“连接”促成了生产效率的提升和社会经济的发展。例如,古有丝绸之路促进了中西方的经济文化交流,海上航线促进工业革命成果的传播和发展(19世纪前后),今有超过50亿用户的互联网推动着知识传播、技术进步和人机协作。联邦学习也是一种“连接”工具,用于连接联邦成员的大数据资产,具有非常广泛的应用价值。




2) 政府和行业协会尚未发布正式的标准和法规,企业和金融机构对新技术存在顾虑。正在立项过程中的联邦学习标准包括IEEE 3652.1, IEEE P2830,待其正式发布后将具有全球公认权威性。此外,京东等企业也在积极参与和推动中国的联邦学习相关的国家标准立项。随着技术标准的完善和实施,企业和金融机构不再有顾虑,联邦学习将如同RSA非对称加密等新技术的应用一样无处不在。

3) 技术门槛较高。虽然市面上已有联邦学习商业解决方案和开源项目,但其稳定性和准确性方面还存在不少异常问题和挑战,需要频繁的更新迭代。常见的移动互联网服务是面向C端消费者的,以企业自身的快速迭代为特征,因此对错误的容忍性较高。然而联邦学习需涉及多个企业,对应的解决方案需面向B端企业,并且需要企业间生成集群和研发人员进行配合,这使得联邦学习合作对异常问题的容忍度非常低。此外,企业需要投入较多的人力资源对联邦学习进行安全性审核、部署、调试和优化,这导致中小企业不能快速使用联邦学习。针对这个问题,包括京东在内的大型企业在投入大量资源研发简单易用的商业解决方案,技术门槛正在逐步降低。

参考文献
[1] Andrew Hard et., al. Federated Learning for Mobile Keyboard Prediction, https://arxiv.org/abs/1811.03604
[2] Qiang Yang et., al. Federated Machine Learning: Concept and Applications. ACM TIST2019. https://arxiv.org/abs/1902.04885
[3] Federated Learning: Collaborative Machine Learning without Centralized Training. https://ai.googleblog.com/2017/04/federated-learning-collaborative.html
[4] Kewei Cheng, Qiang Yang et., al. SecureBoost: A Lossless Federated Learning Framework. https://arxiv.org/abs/1901.08755
[5] 刘洋, 范涛. 联邦学习的研究与应用. https://img.fedai.org.cn/fedweb/1553845987342.pdf
[6] Tian Li et., al. Federated Learning: Challenges, Methods, and Future Directions. https://arxiv.org/abs/1908.07873
[7] 飞向未来的埃舍尔. 联邦学习/联盟学习的发展现状及前景如何?https://www.zhihu.com/question/329518273/answer/717840293
导读 3
上段内容回顾:
本段为您解读:
1. 密码技术的那些事儿
2. 联邦学习的加密原理

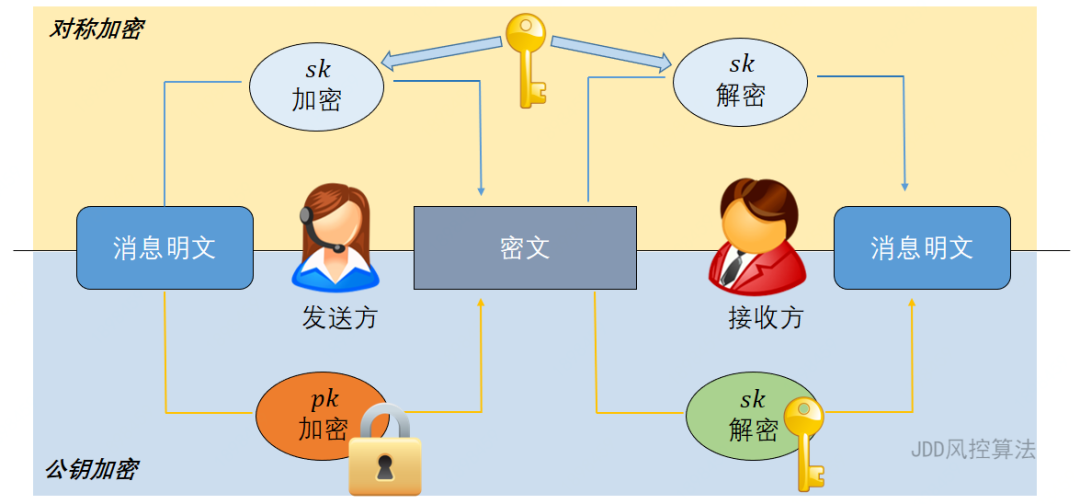
密码(crypto)的概念由来已久,但与我们的手机解锁“密码”或者WiFi“密码”不同。这些由我们自己设置、用来验证身份的数字或者字母的组合,并非真正意义上的密码,而是“口令”(password)。与简单的口令相比,密码技术则是指通信过程中的一种混淆技术,将明文的消息转变为第三方不可识别的消息,在通信过程被窃听时,防止消息的机密性被泄露。准确地来说,密码技术将明文消息加密成密文,发送给通信的接收方,接收方在收到密文后使用密钥进行解密,从而恢复明文。
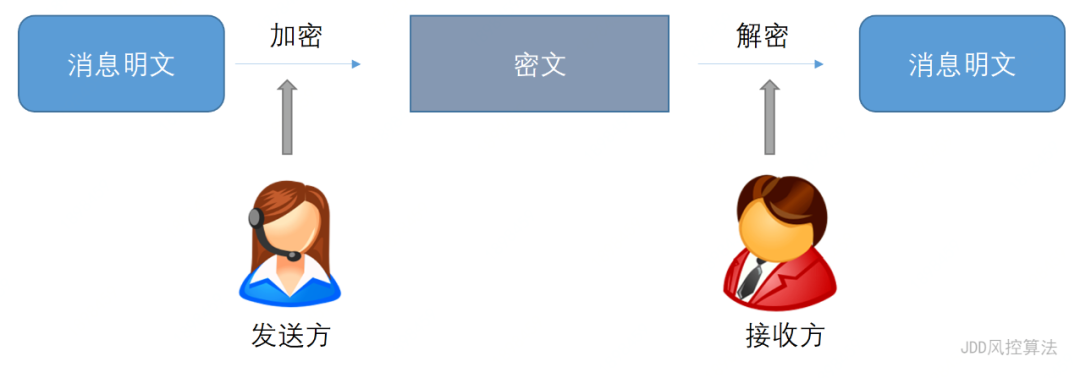

图:凯撒密码轮盘






https://tech.sina.com.cn/scientist/2019-03-01/doc-ihrfqzka5463594.shtml
[9] 二战德军密码机- Enigma
http://www.boy-toy.net/thread-80044-1-1.html
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个三连击呗~~

关于我们:
DataFunTalk 专注于大数据、人工智能技术应用的分享与交流。发起于2017年,在北京、上海、深圳、杭州等城市举办超过100场线下沙龙、论坛及峰会,已邀请近500位专家和学者参与分享。其公众号 DataFunTalk 累计生产原创文章300+,百万+阅读,7万+精准粉丝。

🧐分享、点赞、在看,给个三连击呗!👇





