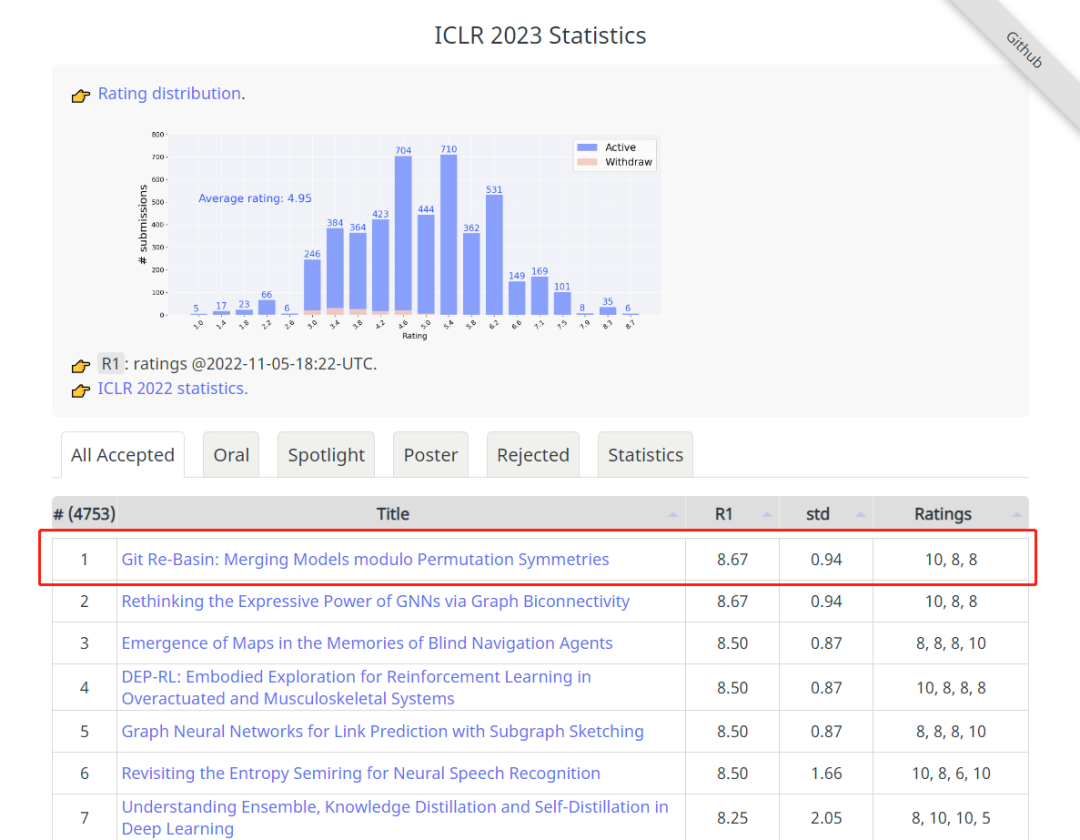
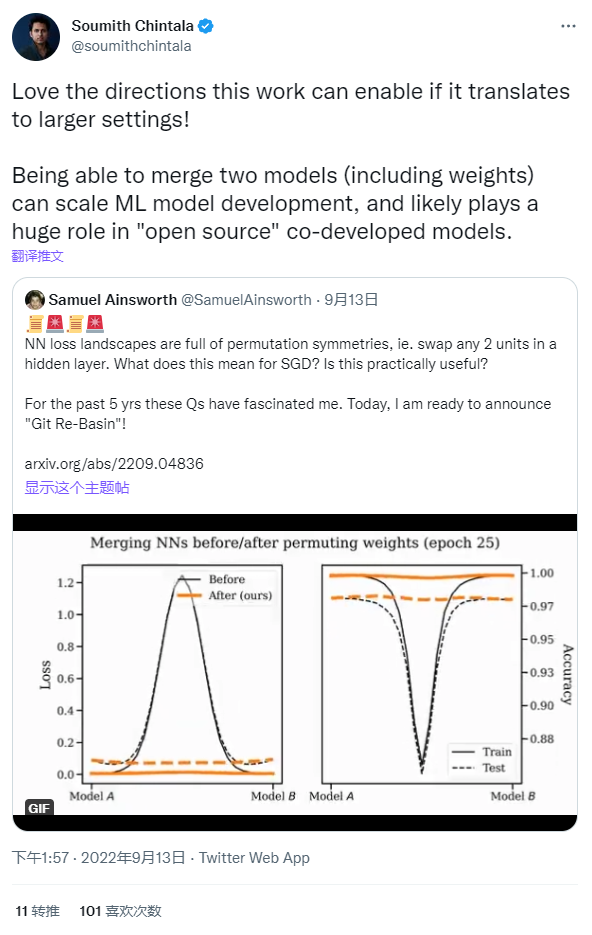
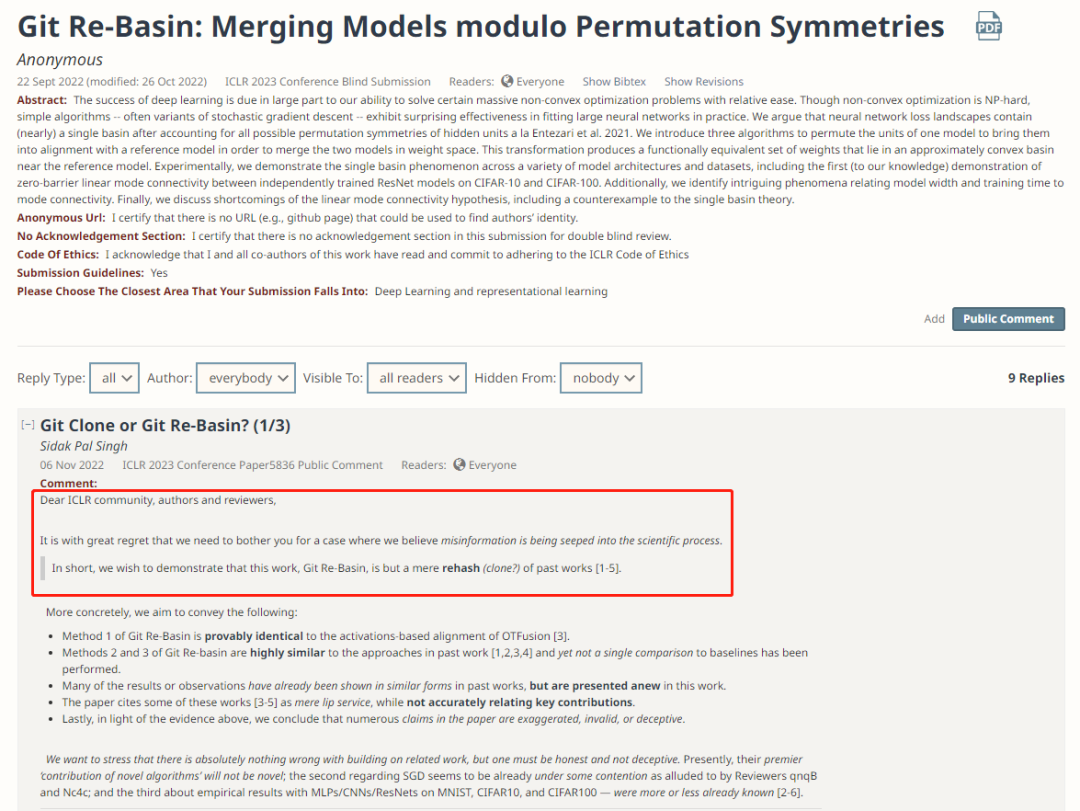
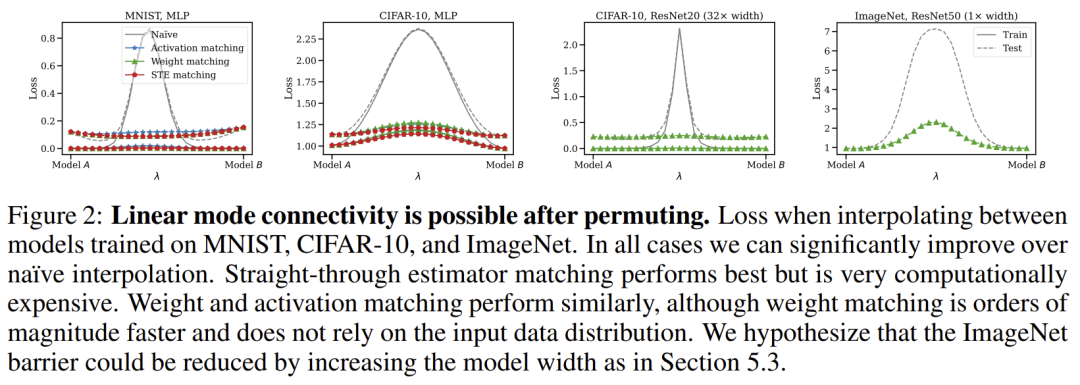
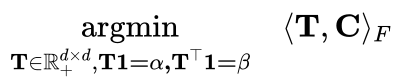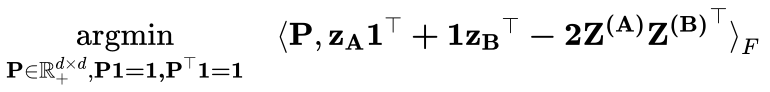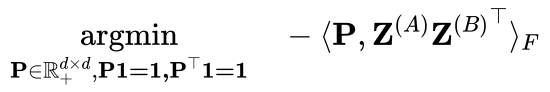现在我们已经看清了 Git Re-Basin 的假象,很清楚,它当前的形式只是以前工作的翻版 [1-5],包含了通过在额外的网络规模和数据集(例如 MNIST、CIFAR10、CIFAR100 的结果已在 [2-6] 中显示)。在这一点上,还需要庆幸 ICLR 是允许社区参与审查过程的独特会议之一,从而避免不准确的判断渗透到文献中——在其他会议中,只有在做了这些判断的情况下才能进行回顾性地更正。鉴于 ICLR 是现代科学进程的火炬手,并将维护科学的完整性,希望我们能够继续对ICLR公正和严谨的决策过程保持信心。最后,这篇长文评论的两位作者Sidak Pal Singh 和 Martin Jaggi 表示很乐意详细说明或回答任何进一步的意见。「听我说中药苦,抄袭应该更苦」,今天的这件事应当对我们有一些启发:应当学习 Sidak Pal Singh 博士对于学术道德的端正态度,诚然,在相关工作的基础上做研究是本没有错的,但必须诚实、不能欺骗、不能心存侥幸地隐瞒。长文评论链接:https://openreview.net/forum?id=CQsmMYmlP5T¬eId=9liIVMeFFnW 参考资料:[1] Ashmore, Stephen, & Michael Gashler. "A method for finding similarity between multi-layer perceptrons by Forward Bipartite Alignment." 2015 International Joint Conference on Neural Networks (IJCNN). IEEE, 2015.[2] Yurochkin, Mikhail, et al. "Bayesian nonparametric federated learning of neural networks." International Conference on Machine Learning. PMLR, 2019.[3] Singh, Sidak Pal, & Martin Jaggi. "Model fusion via optimal transport." Advances in Neural Information Processing Systems 33 (2020): 22045-22055.[4] Wang, Hongyi, et al. "Federated learning with matched averaging." arXiv preprint arXiv:2002.06440 (2020).[5] Tatro, Norman, et al. "Optimizing mode connectivity via neuron alignment." Advances in Neural Information Processing Systems 33 (2020): 15300-15311.[6] Entezari, Rahim, et al. "The role of permutation invariance in linear mode connectivity of neural networks." arXiv preprint arXiv:2110.06296 (2021).