点击上方“计算机视觉life”,选择“星标”
快速获得最新干货
不会画画却也想画出帅哥美女?梦中情人不用空想!近日一篇被计算机图形学顶会 SIGGRAPH 2020 接收的论文提出了一种新的基于草图深度生成人脸图像的方法。
基于该方法的智能人脸画板,不需要用户拥有专业的绘画技巧,就能够从粗糙甚至不完整的草图生成高质量的人脸图像,并且同时支持对面部细节的编辑与控制。该算法降低了人脸肖像绘制的门槛,同时也减轻专业画家的工作难度,简单实用。
人脸图像的生成在各个行业有着重要应用,例如刑事调查、人物设计、教育培训等。然而一幅逼真的人脸肖像,对于职业画家也要至少数小时才能绘制出来;对于从未接触过绘画的新手,就更是难如登天了。新手绘制出来的人脸草图往往非常简陋抽象,甚至有不匀称、不完整。但如果使用智能人脸画板,无疑是有如神助。
![]()
在 2009 年就有使用草图作为输入进行图像合成的研究工作 Sketch2Photo [1],CVPR 2018 上的工作 Mask-guided[2] 实现了基于参考图像和语义标签的人脸图像生成。2018 年 SIGGRAPH 上发表的工作 FaceShop[3] 利用草图交互实现人脸图像编辑。现有的从徒手草图快速生成的方法中,大部分都是基于深度学习的图像到图像转换技术,如 pix2pix,cycleGAN,pix2pixHD 等。然而,当前这些解决方案通常过拟合于草图,往往需要专业绘画的草图甚至边缘图作为输入,才能生成五官匀称合理的图像。对于线条粗犷、边缘不完整封闭的情况难以处理。这就意味着现有的解决方案对于输入草图的质量要求偏高,即无法满足新手或者手残党的需求。
为了解决这个问题,DeepFaceDrawing 工作另辟蹊径。其核心思路并非直接用输入草图作为网络生成条件,而是将人脸进行分块操作后利用数据驱动的思想对抽象的草图特征空间进行隐式建模,并在这个流形空间中找到输入草图特征的近邻组合来重构特征,进而合成人脸图像。
让我们先来看一下基于该方法使用简陋草图生成人脸的效果:
![]()
图一:DeepFaceDrawing 草图合成人脸结果
可以看到,即使草图是「歪瓜裂枣」、欠缺细节表达,或者线条粗犷甚至线条不完整,DeepFaceDrawing 都能为这些草图生成美观真实的人脸图像。与此同时,基于 DeepFaceDrawing 的方法,用户甚至无需进行绘画,可以直接拼凑,从而生成新的人脸:
![]()
图二. DeepFaceDrawing 实现的人脸拼接结果
下面让我们来具体看看这种高度逼真的人脸生成究竟是怎样做到的。
在已有的研究中,往往将输入的草图作为条件生成网络的硬约束,生成效果受草图质量影响较大。也有将草图投影到 3D 空间然后用 3D 模型作条件生成人脸图形的方法,但这种全局参数模型不够灵活,无法容纳丰富的图像细节,难以支持局部编辑。受作者之前 SDM-NET [4]工作启发,并且通过验证发现,全局 - 局部结构的网络对于细节的合成非常有效。因此,这篇论文也采取了对人脸进行分块,然后在特征空间隐式建模的思路。
在这篇论文中,作者一方面将人脸关键区域(双眼、鼻、嘴和其他区域)作为面元,学习其特征嵌入,将输入草图的对应部分送到由数据库样本中面元的特征向量构成的流形空间进行校准。另一方面,参考 pix2pixHD [5]的网络模型设计,使用 conditional GAN 来学习从编码的面元特征到真实图像的映射生成结果。该方法核心亮点之一,便是以多通道特征图作为中间结果来改善信息流。从本质上看,这是将输入草图作为软约束来替代传统方法中的硬约束,因此能够用粗糙甚至不完整的草图来生成高质量的完整人脸图像。
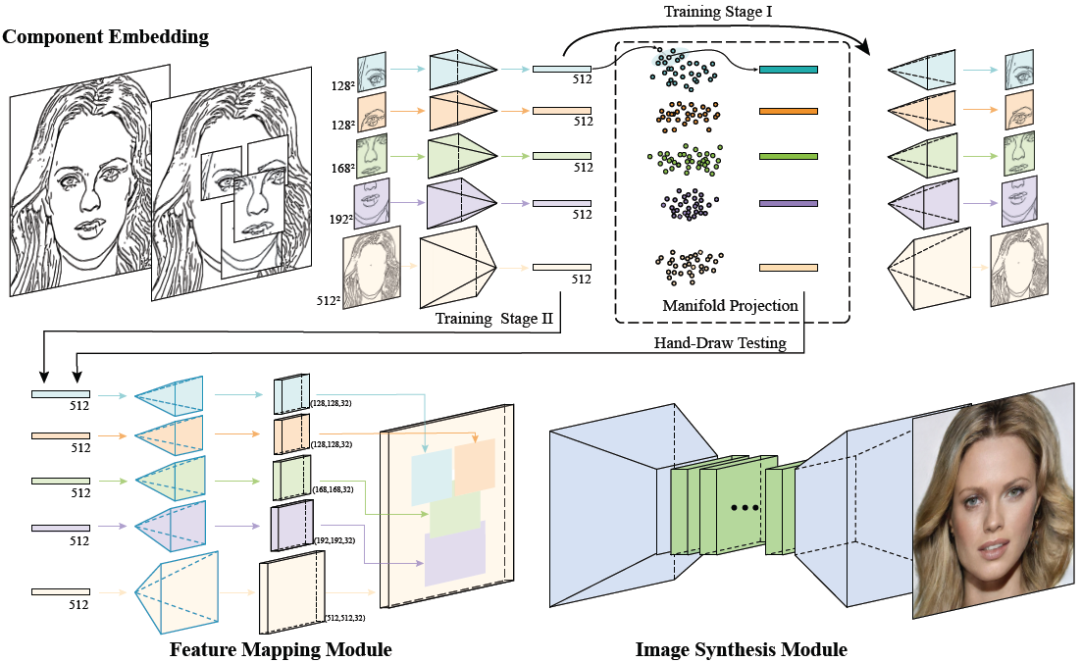
正所谓大道至简,本论文效果好,框架其实也不复杂。如图三所示,DeepFaceDrawing 系统由三个模块组成:内容嵌入模块(Component Embedding)、特征映射模块(Feature Mapping)、图像合成模块(Image Synthesis),在下文它们分别被简称为 CE、FM、IS 模块。
![]()
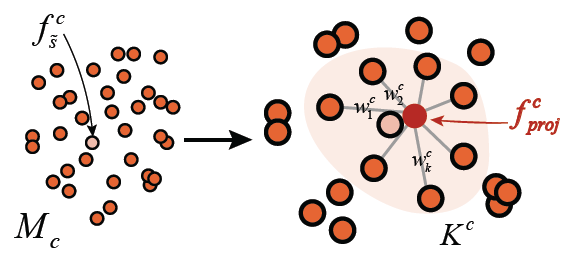
CE 模块采用自编码器结构,将人脸草稿分为五部分(左眼、右眼、鼻、嘴、其他部位)作为五个特征描述符,投影到局部线性的流形空间。每个部位的流形空间由数据库中大量样本编码的特征向量构成。输入的手绘草图样本特征向量则作为点样本投影到这个空间中寻找近邻,通过线性组合重构成来进行优化草图输入,如图四所示。
![]()
FM 和 IS 模块一起构成另一个用于条件图像生成的深度学习子网络,并将组件特征向量映射到现实图像。FM 模块与 CE 模块的解码部分类似,然而所不同的是,FM 模块将特征向量映射到 32 通道的特征映射空间并非 1 通道的草图。由于草图只有一个通道,因此通过草图到图像的网络很难解决重叠区域相邻组件的不兼容性问题。FM 模块中的映射方法改进了信息流,从而提供了更大的灵活性来融合单个人脸部位,以获得更高质量的合成结果。
搭建好整体的框架之后,要想训练出好的生成结果自然需要大量的人脸与草图图片对。为了实现用稀疏线条便能抽象表示人脸,该论文基于 CelebAMask-HQ[6]人脸图像数据库,筛选无遮挡的面部图像后,利用 Photoshop 加草图简化的方法提取草图,构建了一个新的含有 17K 对人脸图像和相应草图的数据集。
数据集构建完毕之后,则开始对网络进行训练。在这里,训练分为两个阶段,如图三所示,阶段一先训练内容嵌入模块,将编码的草图重建后的 MSE loss 做为损失函数训练。阶段二则是固定好内容嵌入模块参数后,再以端到端方式对特征映射模块和图像合成模块网络进行训练。
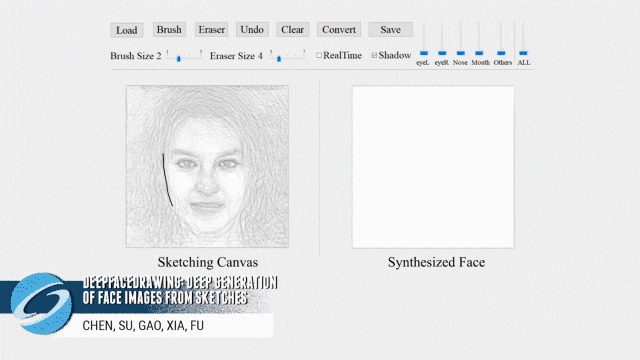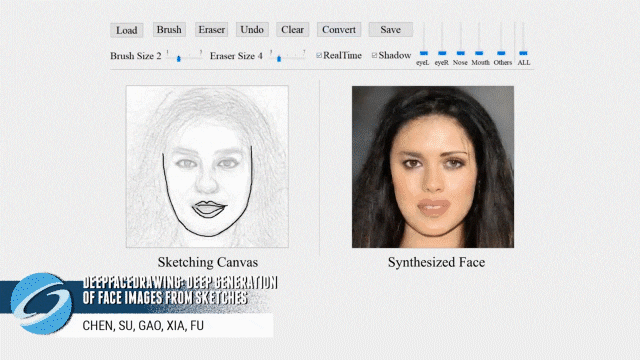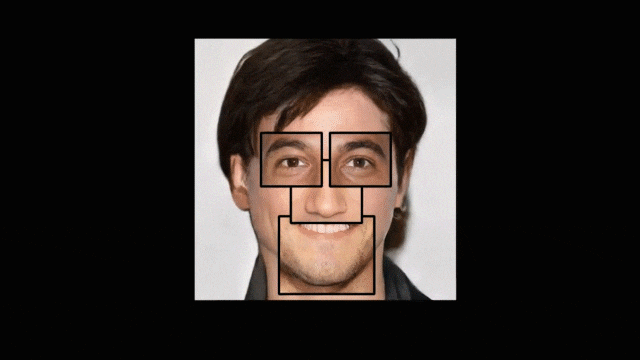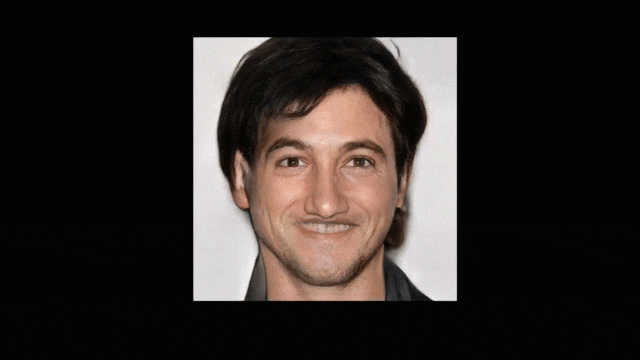
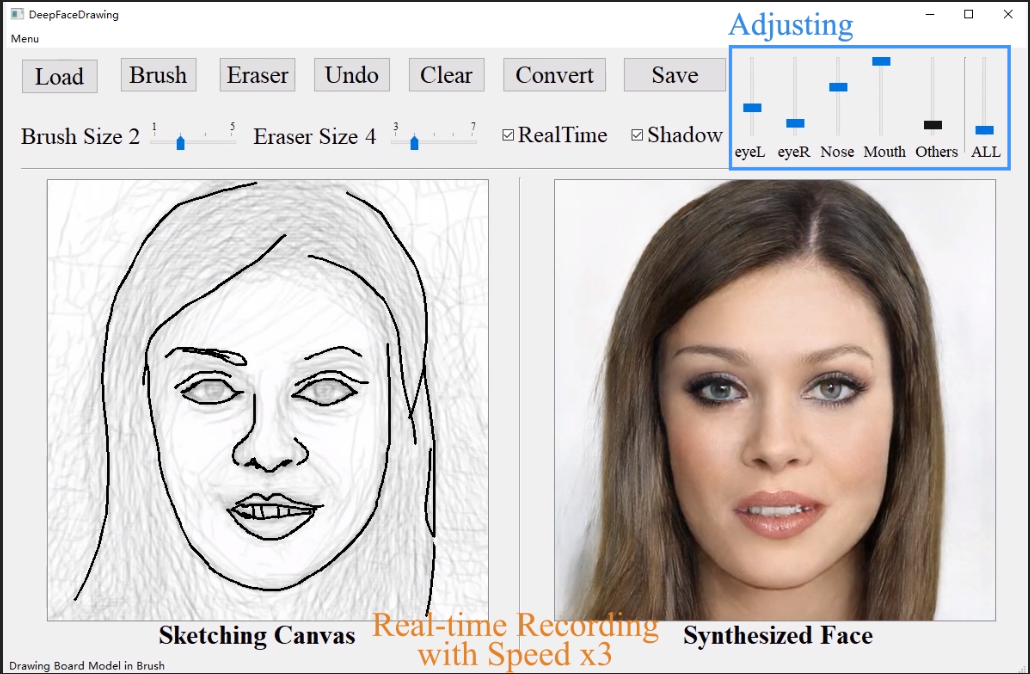
为了更方便用户轻松画好,DeepFaceDrawing 提供了数据驱动下预测的草图供用户参考。每次用户画下一笔后,系统就会根据更新的草图匹配出最接近 “真实人脸” 的草图作为背景阴影,供用户参考。
同时为了方便用户调整细节,DeepFaceDrawing 也提供了对细节的调整,如下图五所示,包括针对脸部五部分的五个参数(eyeL、eyeR、Nose、Mouth、Others)的控制滑条。每个滑条的值代表着原始草图特征和系统优化特征的混合权重,滑条值越高代表混合特征越接近原始草图特征。
![]()
由于 DeepFaceDrawing 实现了将草图各部位编码为对应特征空间中的特征向量,并在流形空间上进行投影,因而可以对相应分量的源特征向量与目标特征向量进行线性插值,再将插值后的特征向量送入网络模块生成中间人脸图像结果,实现人脸变换(Face Morphing)。
同样,因为采用特征向量解析,也可以将来自不同人不同部位的图像提取草图编码成特征向量,将其整合看作一张脸送入网络生成人脸图像,实现人脸拼接(Face Copy-Paste),结果如图二所示。
DeepFaceDrawing 采用局部到全局的方法,将用户输入的草图分块投影到特征空间进行重构优化,避免了不合理草图的影响,能生成完整优美的人脸图像,行之有效,十分巧妙。
有关论文的更多细节,及论文、视频、代码的下载,请浏览项目主页。
-
智能人脸画板系统和论文见项目主页:
http://www.geometrylearning.com/DeepFaceDrawing/
-
Jittor 实现代码:https://github.com/IGLICT/DeepFaceDrawing-Jittor
论文:DeepFaceDrawing: Deep Generation of Face Images from Sketches
![]()
目前智能人脸画板开源代码将提供 Pytorch 版本和 Jittor 两个版本。计图(Jittor)是清华大学计算机系胡事民教授带领团队研发的一个全新的国产深度学习框架。对比 Jittor 版本和 Pytorch 版本运行时间,网络模型在模型训练上 Jittor 相对于 Pytorch 平均加速比为 168%,在图像生成上平均加速比为 300%。
Jittor 网址:https://cg.cs.tsinghua.edu.cn/jittor/
[1] Tao Chen, Ming-Ming Cheng, Ping Tan, Ariel Shamir, and Shi-Min Hu. Sketch2Photo: Internet Image Montage.ACM Transactions on Graphics (Siggraph Asia 2009), 2009, Vol 28, No. 5, 124:1-124:10.
[2] Shuyang Gu, Jianmin Bao, Hao Yang, Dong Chen, Fang Wen, and Lu Yuan. MaskGuided Portrait Editing with Conditional GANs, CVPR 2019.
[3] Tiziano Portenier, Qiyang Hu, Attila Szabo, Siavash Arjomand Bigdeli, Paolo Favaro, and Matthias Zwicker. Faceshop: Deep sketch-based face image editing. ACM Transactions on Graphics, 2018, Vol. 37, No. 4, 99:1-99:13.
[4] Lin Gao, Jie Yang, Tong Wu, Yu-Jie Yuan, Hongbo Fu, Yu-Kun Lai, and Hao (Richard) Zhang. SDM-NET: Deep Generative Network for Structured Deformable Mesh. ACM Transactions on Graphics (Siggraph Asia 2019), 2019, Vol 38, No. 6, 243:1–243:15.
[5] Ting-Chun Wang, Ming-Yu Liu, Jun-Yan Zhu, Andrew Tao, Jan Kautz, and Bryan Catanzaro. High-resolution image synthesis and semantic manipulation with conditional gans, CVPR 2018.
[6] Cheng-Han Lee, Ziwei Liu, Lingyun Wu, and Ping Luo. MaskGAN: Towards Diverse and Interactive Facial Image Manipulation, CVPR 2020.
从0到1学习SLAM,戳↓
视觉SLAM图文+视频+答疑+学习路线全规划!
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
![]()
投稿、合作也欢迎联系:simiter@126.com
![]()
长按关注计算机视觉life
PS:公众号最近更改了推送规则,不再按时间顺序推送,而是根据智能推荐算法有选择性向用户推送,有可能以后你无法看到计算机视觉life的文章推送了。
解决方法是看完文章后,顺手点下文末右下角的“在看” ,系统会认为我们的文章合你口味,以后发文章就会第一时间推送到你面前的,比心~
![]()