多模态推荐系统最新进展总结
© 作者|陈昱硕
机构|中国人民大学
研究方向 | 推荐系统
为了缓解推荐系统中存在的数据稀疏以及冷启动等问题,部分研究者尝试将多模态信息引入推荐系统中,使模型在训练过程中得到更好的用户和物品表示,进而取得更好的模型效果。
1. Recommendation by Users' Multimodal Preferences for Smart City Applications
https://ieeexplore.ieee.org/document/9152003
这项工作提出了一种基于用户多模态偏好的推荐模型。
以往的使用多模态推荐的工作都至少存在以下的一个缺点:
1)采用浅层模型,不能很好地捕获高层概念信息;
2) 未能捕获用户个性化的视觉偏好。
该论文提出了 UMPR (deep users' multimodal preferences-based recommendation) 模型来捕获用户和物品之间的文本和视觉之间的联系。
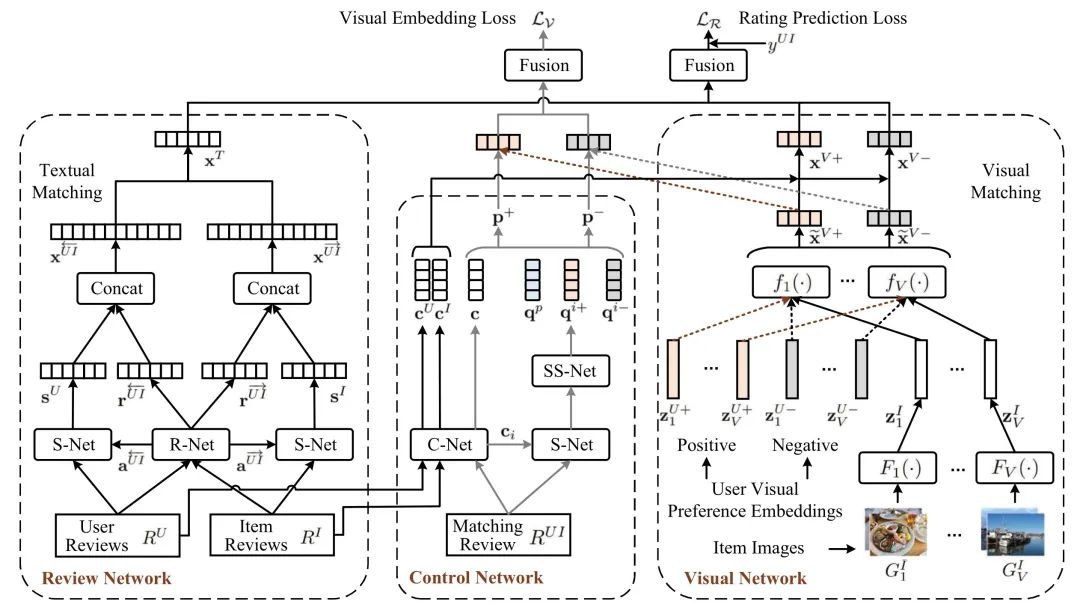
模型图如上所示,输入包括用户 的历史评论 ,物品 的历史评论 ,用户 对物品 的评论 (仅在训练时使用) 以及物品 在 个方面的图片集 。训练任务包括 Rating Prediction 以及用户视觉偏好损失。
该模型主要分为三个部分:Review Network,Visual Network 和 Control Network:
-
Review Network 主要是捕获 和 之间的关联,该网络先使用Glove + 双向 GRU 得到评论的表示以及两者之间的关联度, 然后再使用 attention 机制得到 和 之间的相关匹配模式及其相关情感证据;
-
Visual Network 主要捕获 的特征以及 和用户视觉偏好的关系,该网络使用 VGG-16 得到物品 的表示,然后再计算其与用户 的正面视觉偏好和负面视觉偏好的关联程度, 从而得到物品 与用户视觉偏好的关系;
-
而 Control Network 则是捕获跨模态之间的联系以及指导用户视觉偏好的学习。由于该模型的性能对参数的初始化方式十分敏感,该工作还为模型中的一些模块设计了预训练任务以提升效果。
2. An integrated model based on deep multimodal and rank learning for point-of-interest recommendation
https://link.springer.com/article/10.1007%2Fs11280-021-00865-8
这项工作针对 POI 推荐中存在的数据稀疏、冷启动等问题,提出了 DMRL (deep multi-modal rank learning model) 模型。
这个模型针对用户行为的时空特点,建立了一个与时间相关的一个用户偏好模型,能够更好的捕捉用户行为。并且为了缓解数据稀疏问题,该模型引入了 POI 的语义信息,并使用 BPR 框架来学习隐式交互,模型结构如下图所示:
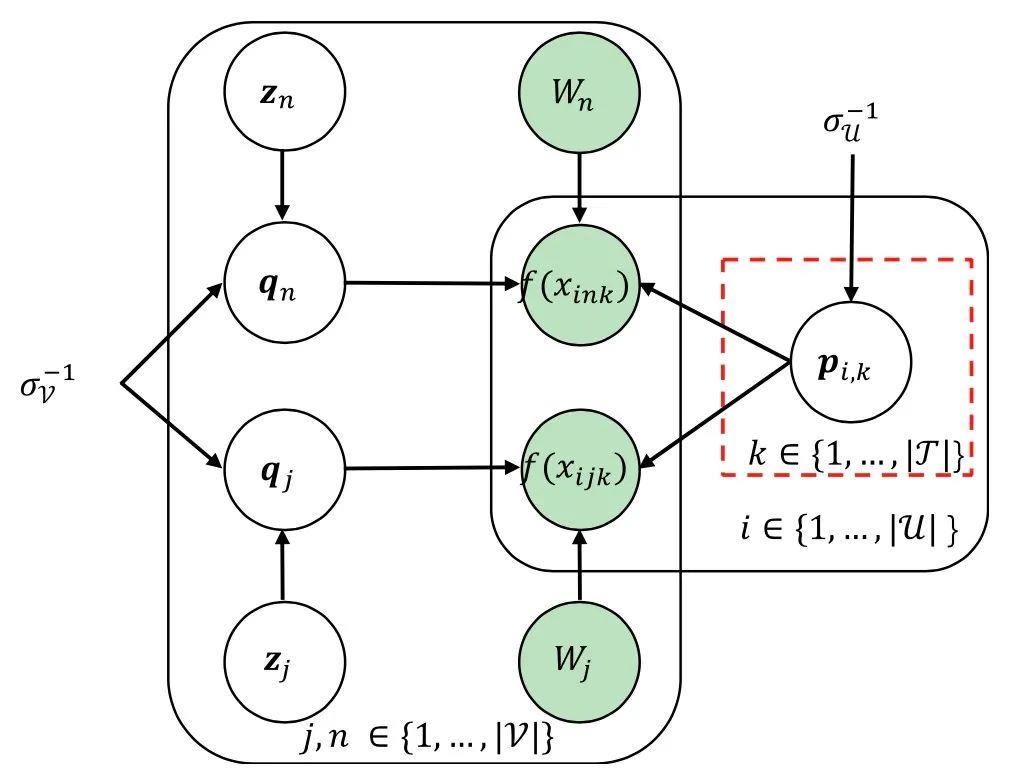
其中 为用户表示, 和 分别为正例地点和负例地点的表示, 和 分别为正负例地点的多模态语义信息, 和 分别为模型对正负例交互的打分,计算方法如下:
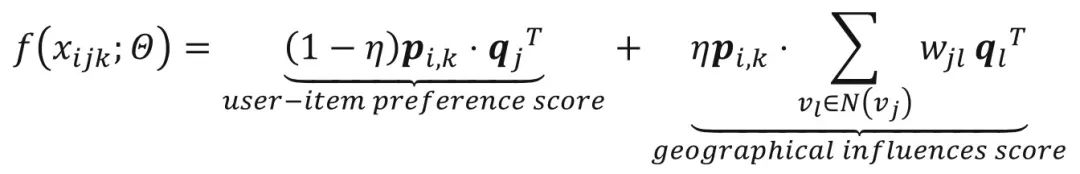
其中 为地点 和地点 间的距离关联度,计算方法为 , 为 之间的距离。从这个打分函数可以看出,该工作在传统的矩阵分解方法的基础上增加了临近地点对目标地点表示的影响。
而对于多模态信息,该模型分别对文本和图像使用了 LSTMAE 以及 VGG-16 来得到对应的表示,然后通过 fusion 网络进行融合,从而得到地点多模态的语义信息。这里的 fusion 网络就是分别对文本和图像的表示通过一个线性层,然后将两者拼接起来再通过一个线性层进行融合。
该部分的模型图如下所示:
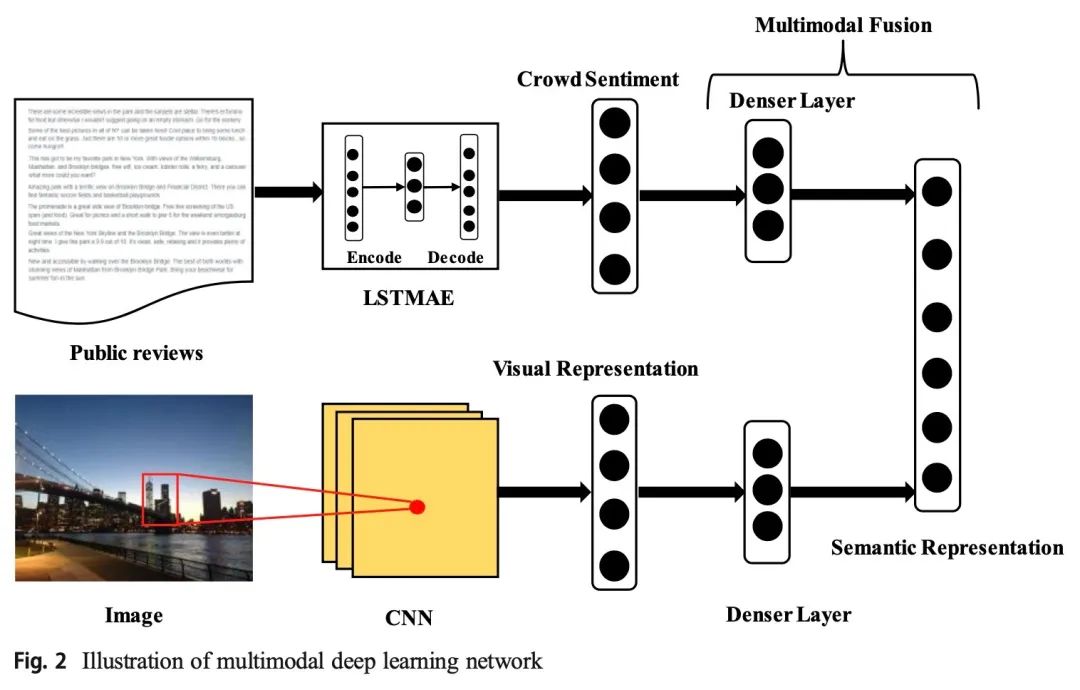
最后该工作使用了一种基于排序的动态抽样策略,以加快收敛速度,并在模型优化过程中提高模型精度。
3. Pre-training Graph Transformer with Multimodal Side Information for Recommendation
https://dl.acm.org/doi/10.1145/3474085.3475709
这项工作为了将物品的多模态信息融入物品的表示中,提出了一个在同质物品图上的预训练模型 PMGT (Pre-trained Multimodal Graph Transformer)。
这个模型首先是根据物品的共同购买次数构建物品的同质图,即该图上相邻的两个节点对应的物品共现次数应超过某个阈值。随后该工作提出了一个 MCNSampling 的采样算法来为每个物品
采样出相关的邻居节点序列
。如下图 a 左半部分所示。这个序列越靠前的节点与
就越相关。
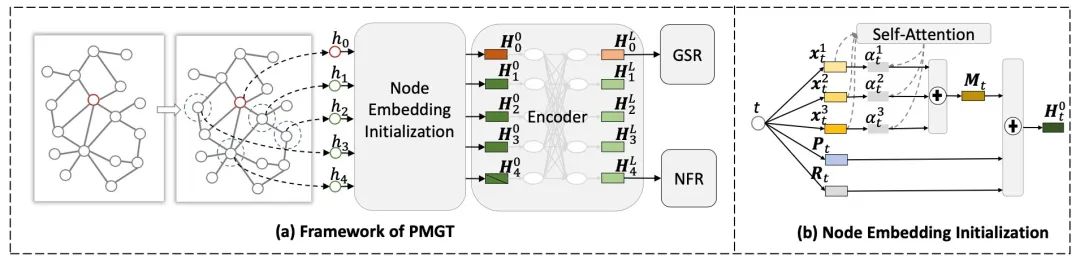
而每个节点的表示 由三部分组成,分别是多模态信息 ,位置表示 以及是否为目标节点的表示 ,如上图 b 所示。其中多模态信息 的计算方法是将多模态的表示先映射到同一个向量空间,然后再使用注意力机制将他们融合起来。
该模型的预训练任务有两个,第一个是图结构重建任务,即节点链接预测;第二个是 mask 节点的特征恢复任务,使用经过 Transformer 网络的表示来恢复 mask 节点的多模态特征。
4. MM-Rec: Multimodal News Recommendation
https://arxiv.org/abs/2104.07407
这项工作提出了一种多模态新闻推荐算法 MM-Rec (Multimodal News Recommendation) ,它融合了新闻的文本和视觉信息来学习多模态新闻表示。该模型结构如下图所示:
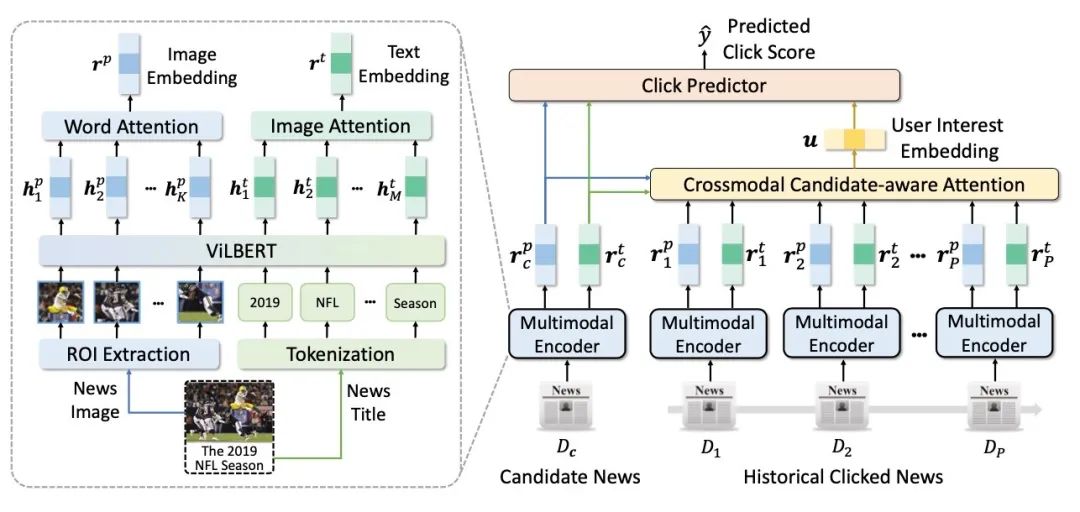
它首先通过目标检测算法 (Mask-RCNN) 从新闻的图像中提取感兴趣区域(ROI)。然后,我们使用预先训练好的视觉语言模型 (ViLBERT) 对新闻文本和新闻图像 ROI 进行编码,并且使用 co-attention 网络对其内在关联性进行建模。
最后,为了得到更加准确的用户建模,该工作还提出了一个跨模态候选注意网络,计算了候选新闻与历史新闻之间的跨模态关联度,通过融合这些多模态信息来得到更好的用户建模。
5. Course video recommendation with multimodal information in online learning platforms: A deep learning framework
https://bera-journals.onlinelibrary.wiley.com/doi/10.1111/bjet.12951
该研究的主要贡献是设计了一个基于深度学习模型的多模态课程推荐框架。在该框架中,模型将从不同种类、不同模态的课程信息,如课程标题、课程音频和课程评论,学习到物品和用户的表示。此外,该工作还利用显性和隐性反馈来推断学习者的偏好。
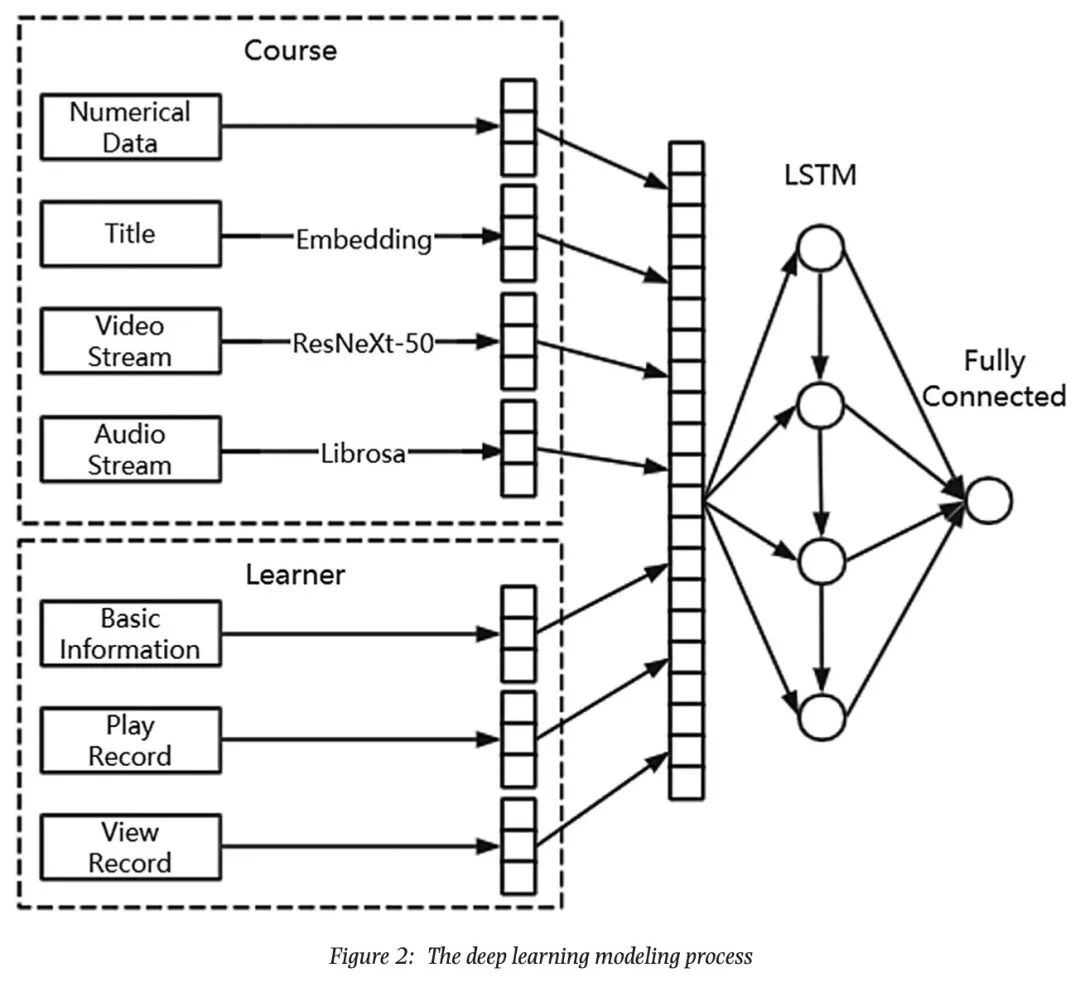
该工作中使用了不同种类、不同模态的数据,如课程标题、课程视频以及课程的其他数值特征。对与课程的标题,该工作在去除了停用词之后,使用预训练好的词表示,再使用这些词表示的平均值作为标题的表示。
而对于课程视频的图像部分,该工作使用了 ResNeXt-50 处理视频每一帧的画面,再将这些画面的表示进行平均,从而得到课程视频图像部分的表示。课程视频的音频部分这是使用 Librosa 处理,提取了过零率、频谱质心、频谱衰减、迈耶频率倒谱系数和色度频率五种声学特征。将上述的所有表示拼接起来就得到了课程的表示。
对于课程平台的用户,该工作将用户的交互行为分为两类,一类是播放过的课程,称为显示交互,另一类是浏览过的课程,称为隐式交互。而用户的表示就是由播放过的课程表示的平均值与浏览过的课程表示的平均值拼接起来的。最后该工作使用 LSTM 来建模用户和课程序列的关联。
该工作的模型图如下所示:
6. DEAMER: A Deep Exposure-Aware Multimodal Content-Based Recommendation System
https://link.springer.com/chapter/10.1007%2F978-3-030-59419-0_38
在之前的工作中,基于内容的推荐系统往往会受到数据稀疏的影响,导致模型会对已交互的物品表示过度特定化,而未知的物品表示则几乎不可区分。为了缓解这一问题,该工作提出了 DEAMER (Deep Exposure-Aware Multimodal contEnt-based Recommender) 模型。
该模型共分为两个模块,分别是曝光生成模块 (Exposure Generation Module) 和打分生成模块 (Rating Generation Module),如下图所示:
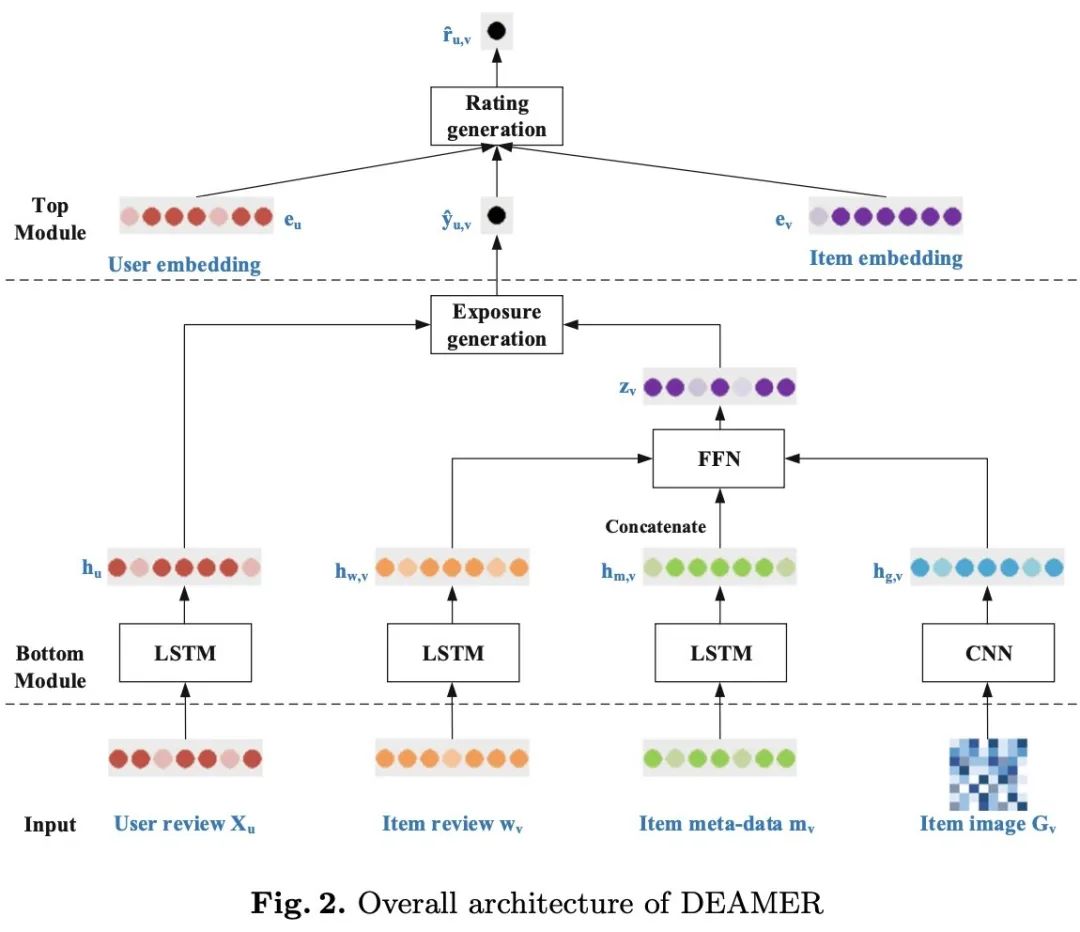
曝光生成模块是模拟推荐系统的现实场景,它基于多模态的用户和物品信息来预计用户是否会和该物品交互。
最后该模型使用如下的损失函数来联合计算两个模块的损失函数:
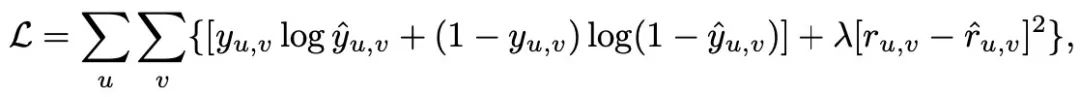
7. MGAT: Multimodal Graph Attention Network for Recommendation
https://www.sciencedirect.com/science/article/abs/pii/S0306457320300182?via%3Dihub
该工作的主要研究如何在多模态交互图上采用 GNN,自适应地捕获用户对不同模态的偏好。为此提出了一种新的多模态图注意网络,简称 MGAT (Multimodal Graph Attention Network)。
MGAT 能在不同模态的交互图上进行信息传播,同时利用门控注意机制识别不同模式对用户偏好的不同重要性分数。因此,它能够捕获隐藏在用户行为中的更复杂的交互模式,并提供更准确的建议。
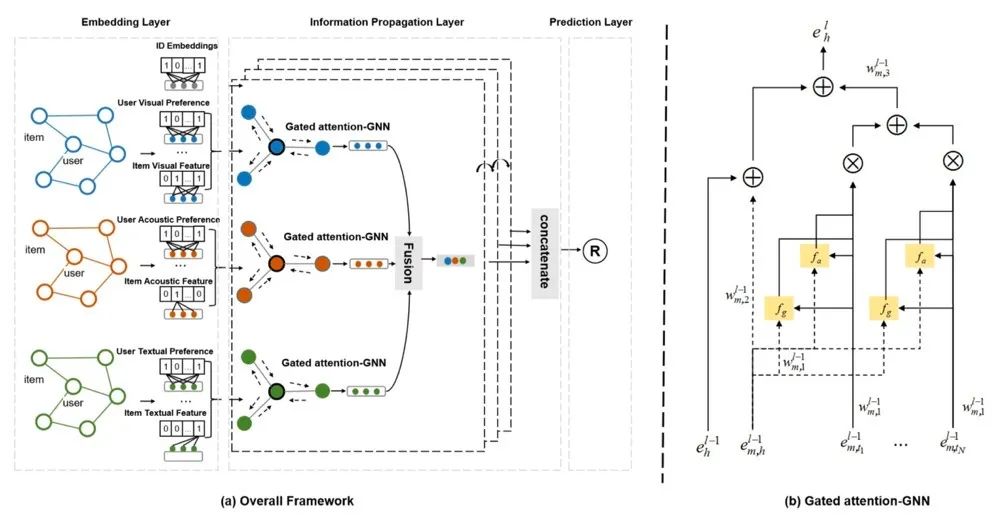
该模型的模型图如上所示,一共有四个部件,分别是:
(1)嵌入层。初始化用户 的表示 ,用户 在模态 上的偏好 ,物品 的表示 以及物品 在模态 上的表示 ;
(2)在单模态交互图上嵌入传播层,执行消息传递机制以捕获用户对各个模态的偏好;
(3)跨多模态交互图的门控注意聚集,它利用与其他模态的相关性来学习每个邻居的权重,以指导传播;
(4)预测层,其基于最终表示来估计交互的可能性。最后使用 BPR loss 来优化模型。
8. Enhancing Music Recommendation with Social Media Content: an Attentive Multimodal Autoencoder Approach
https://ieeexplore.ieee.org/document/9206894
这项工作提出了一种多模态自编码方法 AMAE (Attentive Multimodal Autoencoder) 来捕获用户的多模态特征。
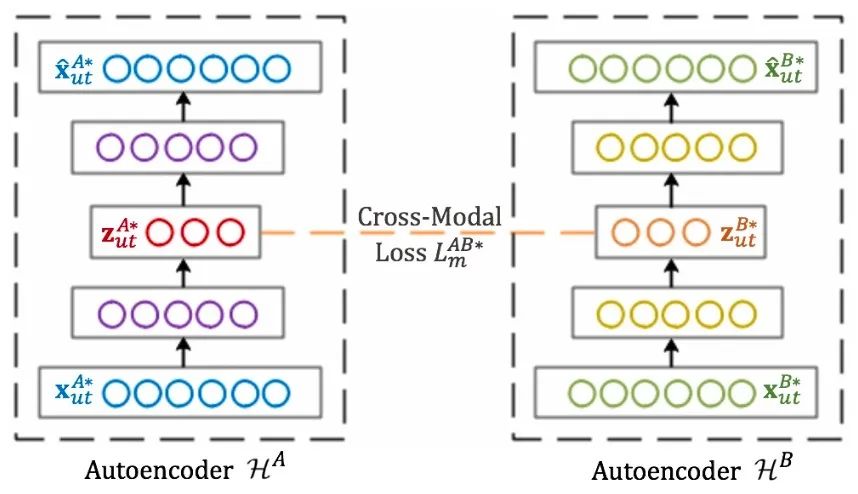
该工作考虑了全局特征和局部特征对用户推荐都存在影响这一因素,它为每个模态计算了全局特征(根据用户进行平均)和局部特征(根据近邻交互进行平均)。然后分别对不同模态,不同层次的特征使用 Autoencoder 来获取低维表示。同时为了不同模态的特征能够互补,该工作为这个 Autoencoder 设计了 Cross-Modal 的损失函数。
AMAE 部分的模型图如下所示:
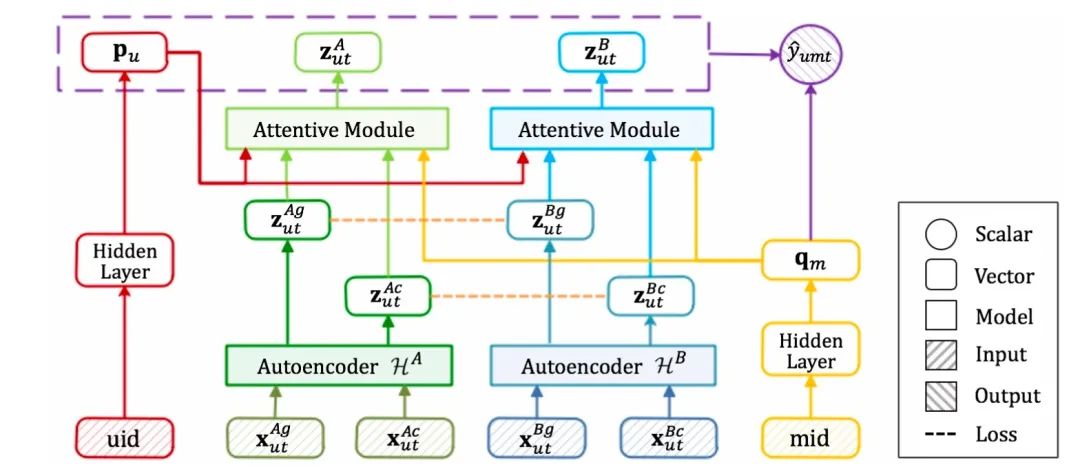
然后,在通过 AMAE 得到用户多模态的全局和局部表示之后,使用注意力机制来聚合每个模态的全局和局部表示。最后再结合矩阵分解方法,将用户的表示和所有模态的表示拼接起来,计算其与物品表示的点积值作为预测值,并使用 BPR 损失函数来优化预测部分的模型。
预测部分的模型图如下所示:
9. Click-Through Rate Prediction with Multi-Modal Hypergraphs
https://dl.acm.org/doi/pdf/10.1145/3459637.3482327
该工作提出了基于超图的多模态推荐框架 HyperCTR ,模型图如下所示:
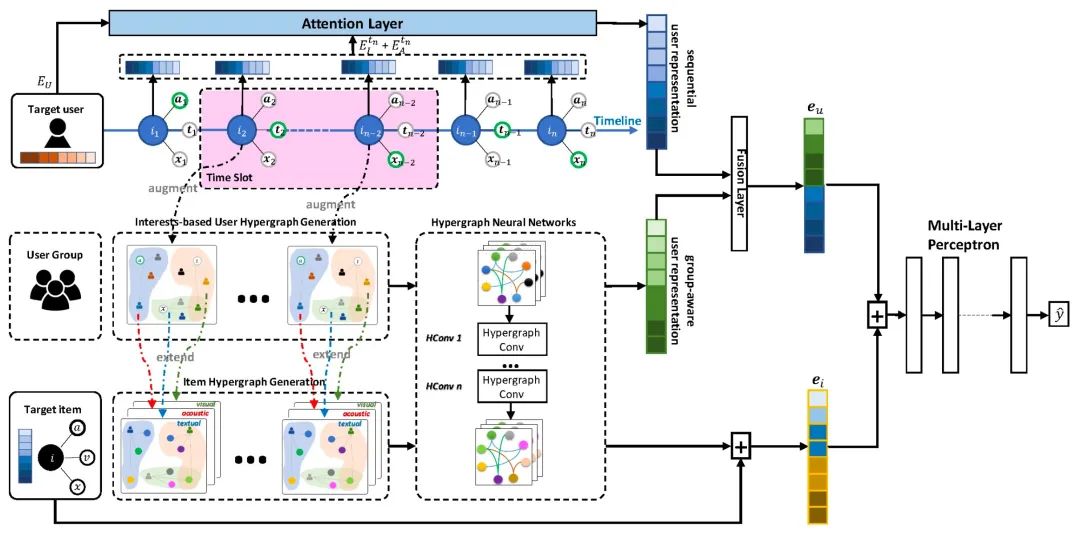
模型主要由四部分组成:基于时序的用户行为注意力模块,基于兴趣的用户超图生成模块,商品超图构造模块以及预测模块。
基于时序的用户行为注意力模块旨在根据用户的物品交互序列,通过用户、物品和多模态类别的表示,结合 Transformer 的自注意力机制来学习交互序列内部的关系。基于兴趣的用户超图生成模块,商品超图构造模块是分别根据用户行为以及物品的多模态联系,构建出对应的超图,再在这些超图上使用 HGCN 来学习用户和物品的表征。最后再将基于时序的用户行为表示和基于超图的用户表示进行融合,最终通过MLP层得到最终的 CTR 预测值。
10. Multi-modal Knowledge Graphs for Recommender Systems
https://dl.acm.org/doi/10.1145/3340531.3411947
该工作的主要贡献是提出了多模态知识图谱自注意力网络 MKGAT (Multi-modal Knowledge Graph Attention Network)。这个模型相比于传统的知识图谱推荐,他能够利用多模态的信息来增强推荐效果。该模型的模型图如下所示,主要由两个模块组成:多模态知识图谱嵌入模块和推荐模块。
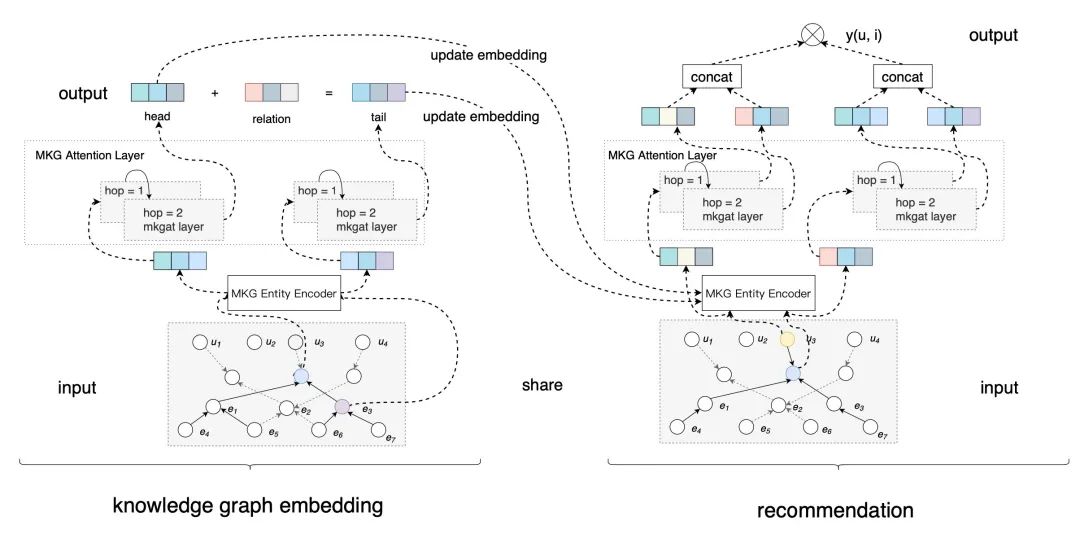
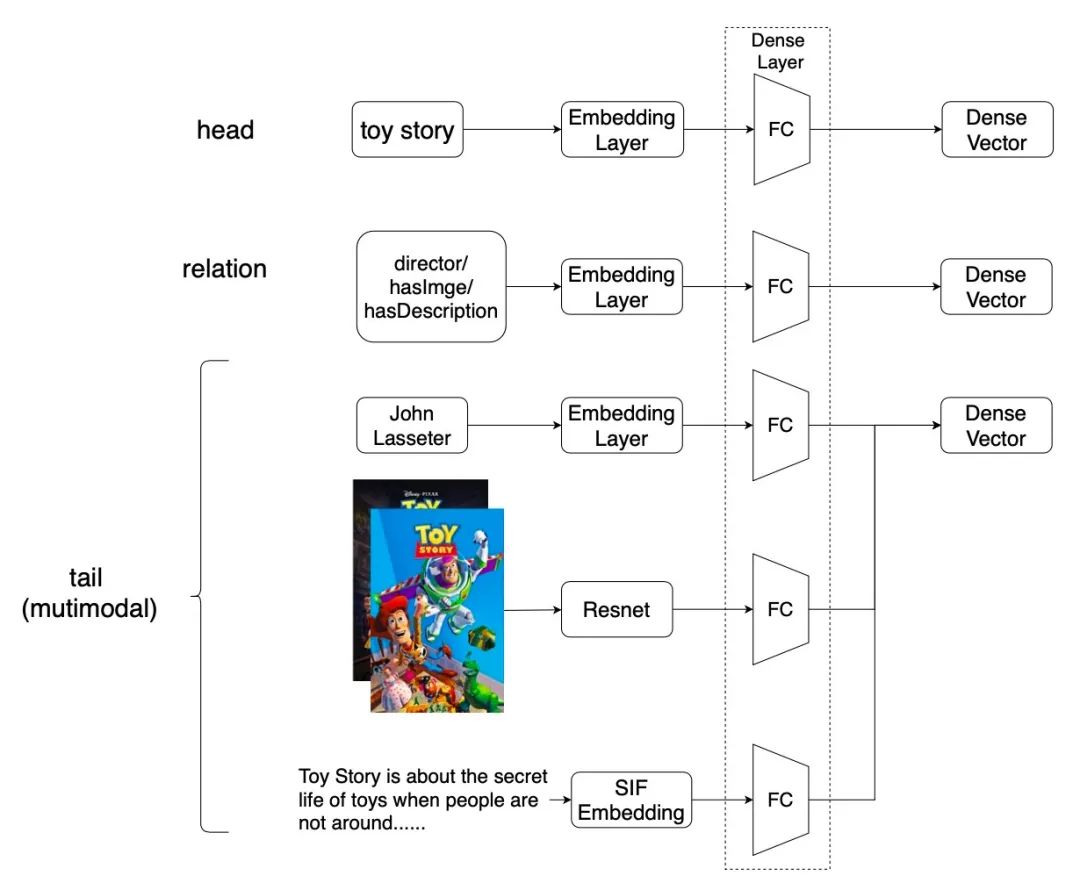
为了将多模态实体合并到模型中,多模态知识图谱嵌入模块也会学习不同模态数据的表示。简单的说,就是该模块首先会为尾实体不同的模态使用不同的编码器,随后再统一到和头实体同样的维度上。如下图所示:
然后在得到头实体、尾实体以及关系的表示之后,该模块仿照 KGAT,使用自注意力机制来汇聚周围节点的信息。
二、小结
将多模态信息引入推荐系统,是解决推荐系统中数据稀疏以及冷启动等问题一种研究方向。近两年的研究工作大致可分为两类:其中较为简单的方法是从不同模态的特征中学习到各自的表示,然后再将这些表示直接拼接或平均起来,作为用户或物品的多模态表示;同时也有其他工作是利用注意力机制等方法来学习不同模态之间的关联,来增强多模态的表示。通过这些多模态的表示,各种模型都一定程度上的缓解了数据稀疏的问题,提高了模型的冷启动性能。
最后,希望本文能够给读者带来一些启发。如有不同见解,欢迎大家批评与讨论。
欢迎干货投稿 \ 论文宣传 \ 合作交流
推荐阅读
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。



