还在为机器学习的因果推理头疼?试试微软的因果推理分析库吧
选自TowardsDataScience
作者:Jesus Rodriguez
机器之心编译
参与:胡曦月、张倩
人类思维具备一种将特定事件与其原因联系起来的超凡能力。上至选举结果下至物体落地,人们不断将导致某种特定结果的一系列事件串联起来。神经心理学将这种认知能力称为因果推理。计算机科学和经济学研究一种特殊形式的因果推理,侧重于发掘两个观测变量之间的关系。多年来,机器学习领域产生了许多因果推理方法,但是绝大多数难以在主流应用中使用。本文介绍了微软推出的因果推理分析框架开源项目——DoWhy,它为许多流行的因果推理方法提供了统一接口。

项目地址:https://github.com/Microsoft/dowhy
因果推理的挑战性并不在于它是一个新学科,恰恰相反,当前的方法只是其中很小的简单版本。大部分诸如线性回归的模型都依赖于对数据做出一些假设的经验分析,纯因果推理基于一种反事实分析,这种分析更能表现人类如何做出决策。想象一个场景,你和家人正在前往未知目的地的旅途上,在旅程前后,你需要解决一些反事实问题:
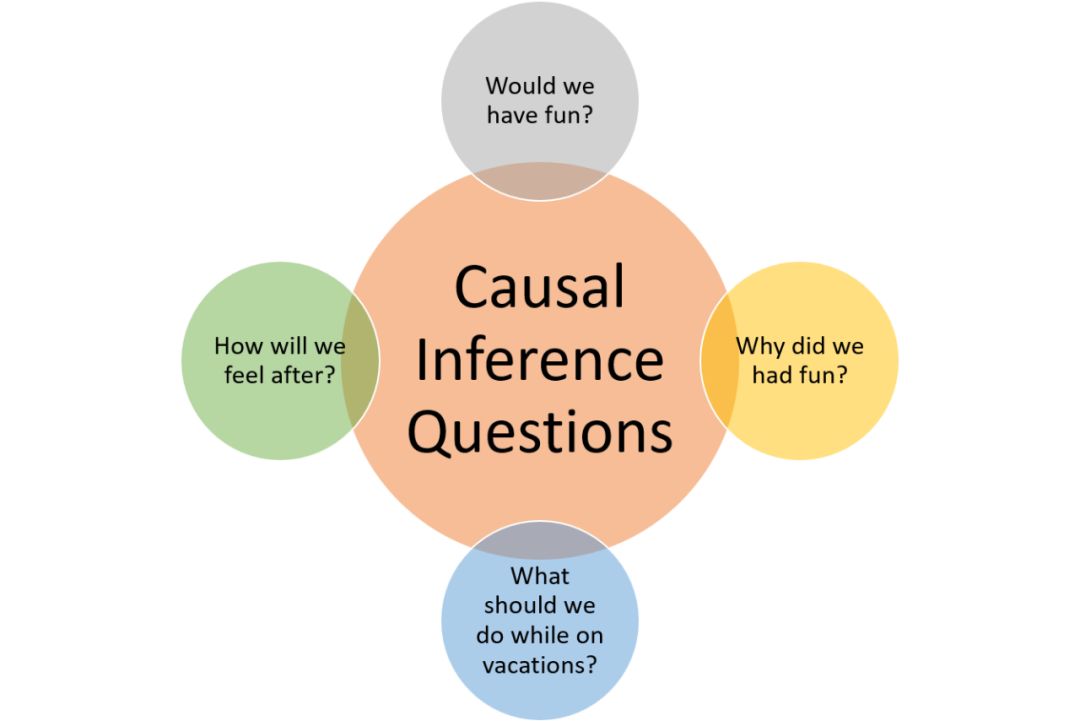
因果推理所关注的正是如何回答这些问题。不同于监督学习,因果推理取决于对未观测量的估计。这就是通常所说的因果推理的「基本问题」,也就是说模型从未对留出测试集进行纯粹客观的评估。在上文旅行的例子中,你可以通过去旅行或者不去旅行来观测效果,但不能同时进行。这就迫使因果推理对数据生成过程做出关键假设。传统因果推理的机器学习框架试图围绕「基本问题」寻找捷径,结果却给数据科学家和开发者带来了令人沮丧的体验。
微软 DoWhy 简介
微软的 DoWhy 是一个基于 Python 的因果推理分析库,致力于简化机器学习应用中因果推理的使用。受到 Judea Pearl 关于因果推理的 do-calculus 的启发,DoWhy 在一个简单的编程模型下结合了几种因果推理方法,从而消除了传统方法中的许多复杂性。与之前的方法相比,DoWhy 为实现因果推理模型做出了三项重要贡献。
提供了一种原则性方法,对给定的问题进行因果图建模,从而显化所有假设。
结合两种主流图形模型框架及其可能输出,为许多流行的因果推理方法提供统一接口。
在可能的情况下对假设有效性进行自动测试,并且评估在假设失效时估计的鲁棒性。
从概念上讲,DoWhy 的创建基于两个指导原则:1. 要求因果假设的明确性;2. 当假设失效时,测试估计的鲁棒性。换句话说,DoWhy 将因果效应的识别与其相关性的估计区分开,这使得推理出非常复杂的因果关系成为可能。
为实现这一目标,DoWhy 通过四个基本步骤对工作流中的任意因果推理问题进行建模:建模(model)、识别(identify)、估计(estimate)、反驳(refute)。
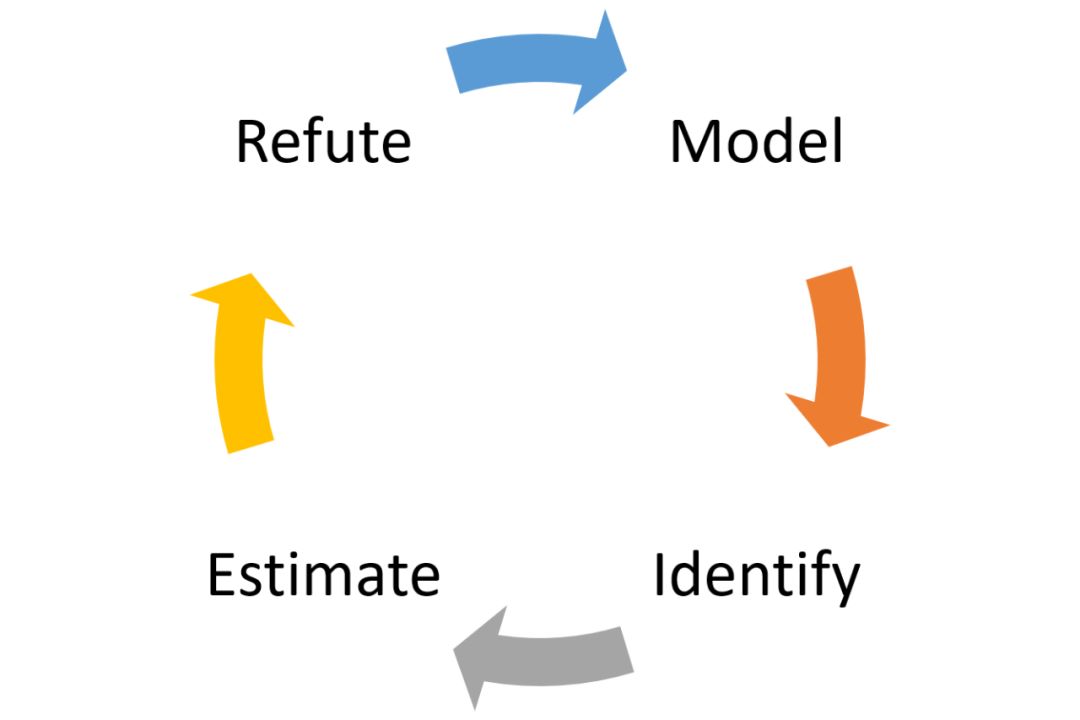
建模:DoWhy 使用因果关系图对问题进行建模。DoWhy 目前的版本支持两种图形输入格式:gml(首选)和 dot。图中可能包括变量中因果关系的先验知识,但 DoWhy 并不立即作出假设。
识别:DoWhy 基于图模型,使用输入图寻找所有可能的方法来识别所需的因果效应。
估计:DoWhy 使用统计方法来估计因果效应,如匹配或工具变量。DoWhy 目前的版本支持侧重于估计处理分配的技术,如基于倾向分层(propensity-based-stratification)或倾向分数匹配(propensity-score-matching)的估计方法;同时支持侧重于估计响应面的回归技术。
验证:最后,DoWhy 使用不同的鲁棒性方法来验证因果效应的有效性。
使用 DoWhy
想要使用 DoWhy,开发者首先需要使用以下命令安装 Python 模块:
python setup.py install
与其它机器学习程序相同,DoWhy 应用程序的第一步就是加载数据集。本例中,假设我们试图推理出以下数据集中所述的不同疗法及其效果之间的相关性。
Treatment Outcome w0
0 2.964978 5.858518 -3.173399
1 3.696709 7.945649 -1.936995
2 2.125228 4.076005 -3.975566
3 6.635687 13.471594 0.772480
4 9.600072 19.577649 3.922406
DoWhy 使用 pandas 库获取输入数据:
rvar *=* 1 *if* np*.*random*.*uniform() *>*0.5 *else* 0
data_dict *=* dowhy*.*datasets*.*xy_dataset(10000, effect*=*rvar, sd_error*=*0.2)
df *=* data_dict['df']
print(df[["Treatment", "Outcome", "w0"]]*.*head())
此时,我们只需要四个步骤来推理变量之间的因果关系。这四个步骤对应于 DoWhy 的四个操作:建模,估计,推理和反驳。首先将问题建模为因果图:
model= CausalModel(
data=df,
treatment=data_dict["treatment_name"],
outcome=data_dict["outcome_name"],
common_causes=data_dict["common_causes_names"],
instruments=data_dict["instrument_names"])
model.view_model(layout="dot")
from IPython.display import Image, display
display(Image(filename="causal_model.png"))
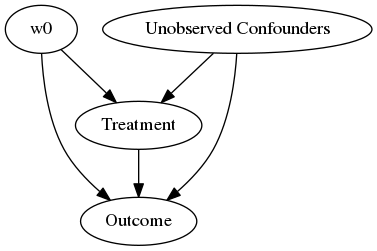
接下来在图中识别因果关系:
identified_estimand *=* model*.*identify_effect()
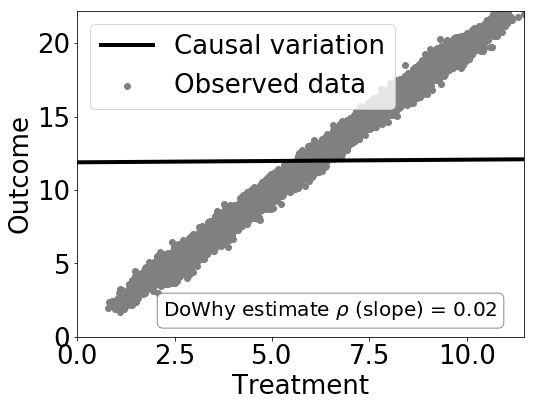
现在我们可以估计因果效应,并且判断估计结果是否正确。简单起见,本例使用线性回归:
estimate *=* model*.*estimate_effect(identified_estimand,
method_name*=*"backdoor.linear_regression")
# Plot Slope of line between treamtent and outcome =causal effect
dowhy*.*plotter*.*plot_causal_effect(estimate, df[data_dict["treatment_name"]], df[data_dict["outcome_name"]])
最后,我们可以用不同的技术来反驳该因果估计:
res_random*=*model*.*refute_estimate(identified_estimand, estimate, method_name*=*"random_common_cause")
DoWhy 是一种实现因果推理模型的简单有效的框架。当前版本可以作为一个独立库,也可以集成到流行的深度学习框架中,如 TensorFlow 或 PyTorch。DoWhy 在单一框架下结合了多种因果推理方法,它的四步简单程序模型使得数据科学家非常易于解决因果推理问题。

参考链接:https://towardsdatascience.com/introducing-dowhy-cc58b75d61ac
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com



