什么是中心极限定理?这里有一份可视化解释
编者按:中心极限定理是概率论中的一组重要定理,它的中心思想是无论是什么分布的数据,当我们从中抽取相互独立的随机样本,且采集的样本足够多时,样本均值的分布将收敛于正态分布。为了帮助更多学生理解这个概念,今天,UW iSchool的教师Mike Freeman制作了一些直观的可视化图像,让不少统计学教授大呼要把它们用在课堂上。
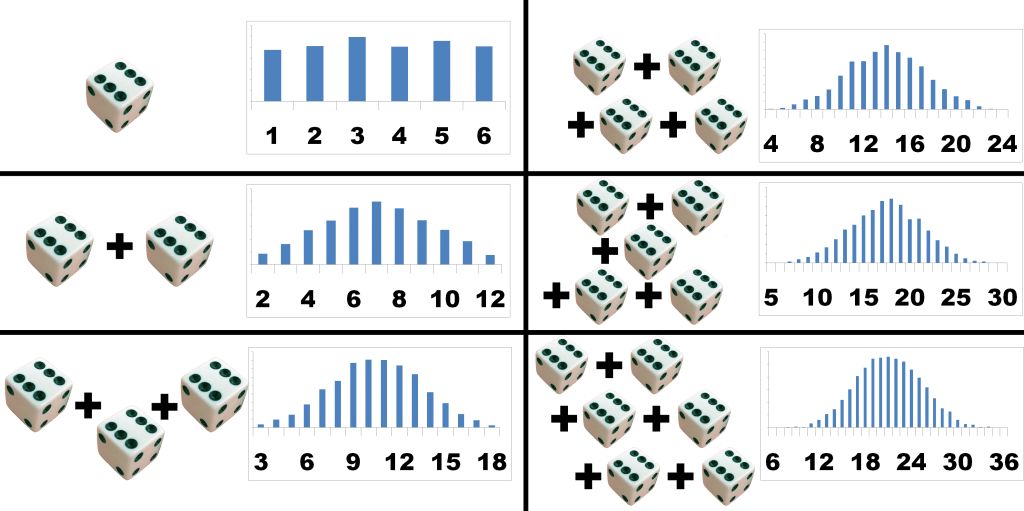
本文旨在尽可能直观地解释统计学基础理论之一——中心极限定理的核心概念。通过下文中的一系列动图,读者应该能真正理解这个定理,并从中汲取应用灵感,把它用于决策树等其他项目。
需要注意的是,这里我们不会介绍具体推理过程,所以它不涉及定理解释。
教科书上的中心极限定理
在看可视化前,我们先来回顾一下统计学课程对中心极限定理的描述。

来源:LthID
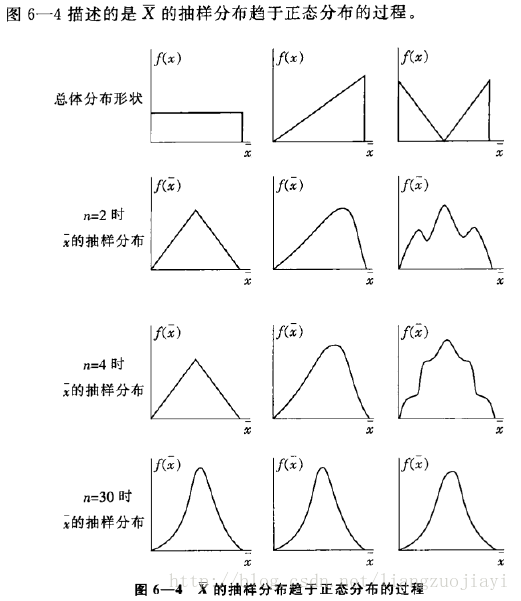
n>30一般为大样本的分界线 来源:LthID

来源:LthID
一个简单的例子
为了降低这个定理的理解门槛,首先我们来举个简单的例子。假设有一个包含100人的团体,他们在某些问题上的意见分布在0-100之间。如果以可视化的方式把他们的意见分数表示在水平轴上,我们可以得到下面这幅图:深色竖线表示所有人意见分数的平均值。

假如你是一名社会科学家,你想知道这个团体的立场特点,并用一些信息,比如上面的“平均意见得分”来描述他们。但可惜的是,由于时间、资金有限,你没法一一询问。这时候,你就可能需要对这100人进行抽样。比方说,在有限的时间、资金条件内,你可以从中随机抽取10个人作为自己的采访对象(n=10),向他们询问有关特定问题的具体想法:

随机抽取10个样本
如你所见,这些样本的均值可能会和整个团体的总体均值有很大差异。那么,怎么采样才能更可靠呢?
考虑多个样本
假设我们可以从团体中采集多个样本。虽然这种做法在现实中是客观存在的(尤其是在政治民意调查中),但在这里,我们会更多地将其作为一种解释工具(当你进行重复采样时,实际上会有一些意料之外的因素出现)。对于每个样本,我们在每次采样时都跟踪样本均值与整体平均值的差。
多次重复该过程,我们就能获得样本均值的分布,它通常被称为样本均值分布,或者(更简单的)抽样分布。下面是对100人的团体进行多次抽样后(每次10人),样本均值的变化情况:
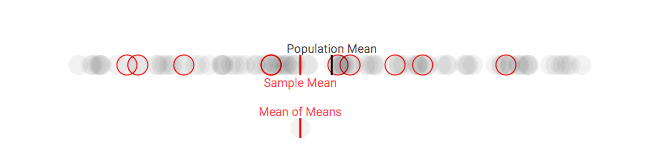
第一次采样,样本均值和总体均值有明显偏差
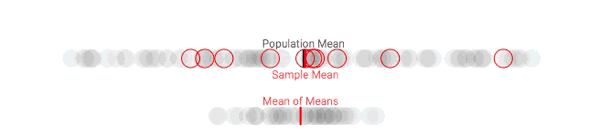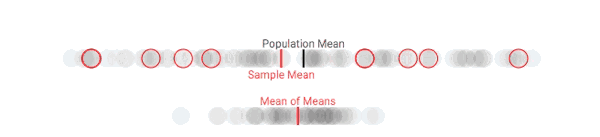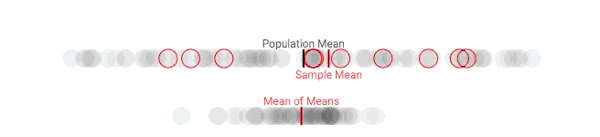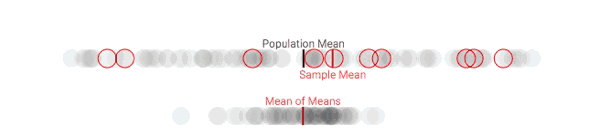
多次采样后,样本均值和总体均值的偏差变小了
可以发现,随着抽样次数逐渐增多,总体均值和样本均值之间的差距正在不断缩小。这是可以理解的,因为整个过程就相当于从100人中抽取更多样本。但之前我们也说了,资金、时间是有限的,这没有解决资源受限的问题,也无法反映人整个团体在特定问题上的立场。
为了了解每次计算样本均值的效果,我们得先看看抽样分布的分布情况。
理解分布
鉴于上述可视化图像在分布上不够直观,所以在这里,我们把原先表示每个意见的圆圈变成方块,以直方图的形式展现总体分布的情况:

显然,我们的数据分布并不正常。虽然上图中有些部分的曲线是符合正态分布的,但大多数是不符合的,这段曲线没法帮助我们理解这100个人的习性。相反地,我们可以从样本均值的分布情况着手,看看抽样分布的变化情况:
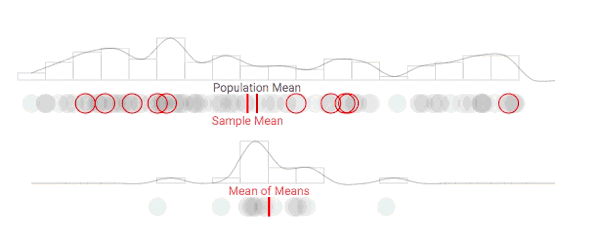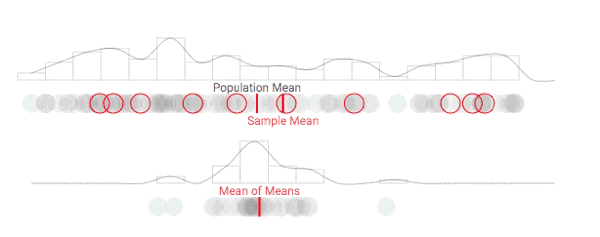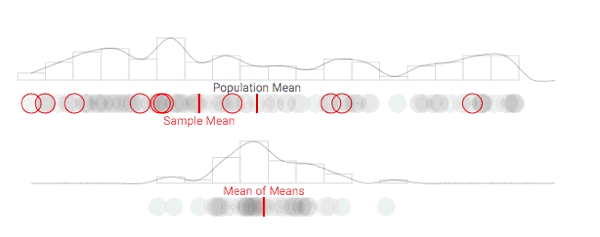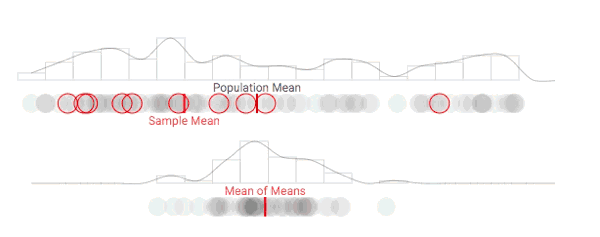
随着采样次数上升,抽样分布正在发生变化
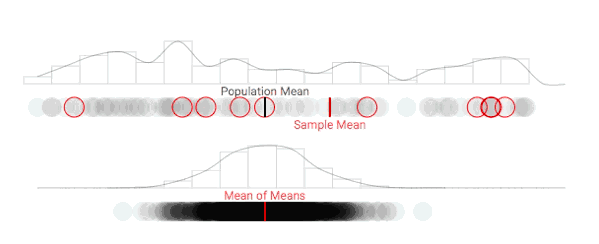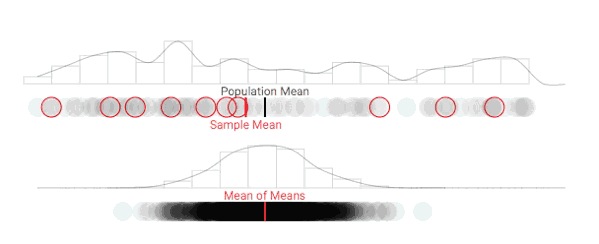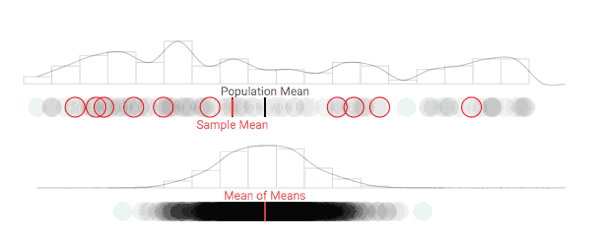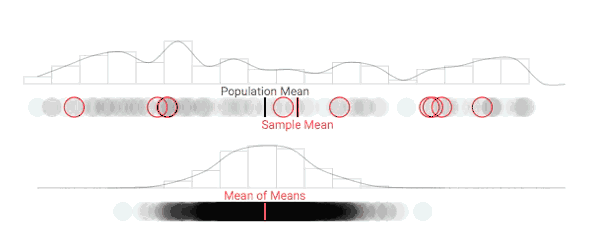
进一步增加采样次数,抽样分布的形状逐渐趋于稳定
随着采样数量的增加,采样分布在可视化中形成了一条钟形曲线,符合正态分布。如上所述,随着重复采样次数的增加,样本均值(抽样分布的平均值)会变得越来越准确。
为什么重要
当采样的数量接近无穷大时,我们的抽样分布就会近似于正态分布。这个统计学基础理论意味着我们能根据个体样本推断所有样本。结合正态分布的其他知识,我们可以轻松计算出给定平均值的值的概率。同样的,我们也可以根据观察到的样本均值估计总体均值的概率。
维基百科对于“中心极限定理”的定义:中心极限定理是概率论中的一组定理。中心极限定理说明,在适当的条件下,大量相互独立随机变量的均值经适当标准化后依分布收敛于正态分布。
在留言中,美国田纳西州范德堡大学的医学院生物统计学教授Frank Harrell留下了自己的风趣评论:“但是在所有定理中,中心极限定理是最后一个我想教给学生的东西。我想他们得先学好第一堂课,它包括一些设计、数据的意义、数据的稳健性、bootstrap、一些贝叶斯、高精度数据图等等。”
读完他的话,是不是觉得即便了解了这个定理,自己要学的东西还是很多呢?
原文地址(提供交互式可视化,建议去看看):mfviz.com/central-limit/
Github(包含可视化组件代码):github.com/mkfreeman/central-limit





