专心做搜索也能登顶CLUE分类榜?在快手做搜索是一种怎样的体验
文 | 快手搜索
短视频和直播,越来越成为重要的内容供给形式,而内容供给侧的改变,也在潜移默化地推动着用户搜索习惯的变化。据报道,截止今年4月,超过50%的用户都在使用快手搜索功能,每天搜索达到2.5亿次,每天有超百万部作品被用户搜索到,截止今年8月,快手搜索日均搜索次数超过3亿,用户利用快手搜索的习惯似乎在逐步养成。

区别于传统的网页搜索,在快手的短视频搜索场景中的主要挑战为:
主要内容是短视频
网页的主要信息载体为文字,往往具备比较丰富的上下文描述,而相对来说,短视频的表达载体更加多元化,一部分上下文信息可以通过视觉或者听觉的方式传递给用户,而不再需要额外的文本描述,最终导致短视频的文本信息往往相对网页来说更加短小精悍;上下文的缺乏,就对模型的文本语义刻画能力和多模态理解能力有了更高的要求。
较显著的社区特性
快手搜索的内容生产者和消费者,都带有比较显著的社区特性:由于快手更加强调其社交属性,用户在日常的相互沟通和讨论中,往往会产生一系列这个社区内独有的“黑话”,这些社区文化的产生,一定程度上就会造成相同的文字在快手社区内和全网范围内,表义完全不同的现象,例如:同样是搜索“礼物”,在传统搜索引擎中,获取到的往往是例如“礼物如何购买”,“礼物推荐”等相关内容,而在快手社区内,term“礼物”还有另一层含义,就是网红“小礼物”,这类具有特色的社区文化,就会使得一些开源的模型和算法,在实际场景中难以发挥出较强的作用。

破圈挑战
满足社区内需求的同时,也需要不断应对破圈过程中的各种挑战:用户规模的不断增加和搜索需求的不断增加,就需要相应的搜索算法能够未雨绸缪,想办法具备更强的泛化能力,能够同时处理社区内(in-domain)和社区外(out-of-domain)的不同输入和信息,从而达到为整体业务破圈保驾护航的作用。
PERKS
为了应对上述挑战,快手搜索的NLPers针对快手搜索场景,打造了一套更加全面的模型评估体系,同时涵盖了内部业务数据集和外部公开数据集,以此来模拟对in-domain任务和out-of-domain任务的处理能力,同时,面向快手搜索业务特点,打造了一个具有快手搜索特色的预训练语言模型:PERKS(Pre-trained Embedding Representation for Kuai Search),相比于其他开源的预训练语言模型,PERKS在技术上具有以下特点:
数据准备层面
分别收集了TB级别的内部和外部语料,其中,内部语料包括视频中文字标题,高置信度的视频ocr识别结果,和高置信度的视频asr识别结果,该视频的相关评论和点击query,通过视觉学习到的视频tag等文本内容,并通过文字出现的位置和时间等信息,将一个视频中的文字组织成一个文档,以便于进行训练。外部语料中,除了常见的开源百科数据,还包括一些开源的新闻网站内容。经过各种预处理过滤掉不置信内容,去除冗余信息后,一个高质量,同时包含内部特色和外部特色的数据集就构造出来了。
训练任务层面
为了让模型能够同时学习到不同领域,不同粒度的语言知识,参考MMOE思想,设计了一个多阶段,多任务的学习模式,包括,第一阶段(pre-pretrain)使用百科数据学习Masked Langauge Model(采用了dynamic whole-word-masking),去学习基础的语言知识。
二阶阶段(pre-train),使用内部语料和外部语料进行混合,并且将训练任务扩展为:dynamic-whold-word-masking,char-reorder,knowledge-masking(通过百科和内部关键实体识别技术,对齐到的知识信息进行mask),important-whole-word-masking等,并在这个阶段引入sentence-order-prediction,sentence-distance-prediction,sentence-source-prediction(这段文本是来自于ocr,asr,网页数据,还是其他部分)等任务,用于刻画句子级知识,通过课程学习的方式,在训练过程中逐步调整不同任务的配比,让模型逐渐学习到更具有挑战的知识。
经过第二阶段,模型就学习到了一个比较大而全面的通用语言知识。在最终阶段(post-pretrain),PERKS会针对下游任务的特点,对in-domain和out-of-domain的语料,进行不同比例的采样,并根据当前下游任务是处理word-level还是sentence-level任务的特点,对于训练任务进行调整,并在一个精选数据上,进行微调,例如针对ANN召回任务和双塔语义模型,PERKS在最终阶段采用了采用对比学习作为主任务,并使用其他部分任务作为辅助任务,进行最终阶段的学习。
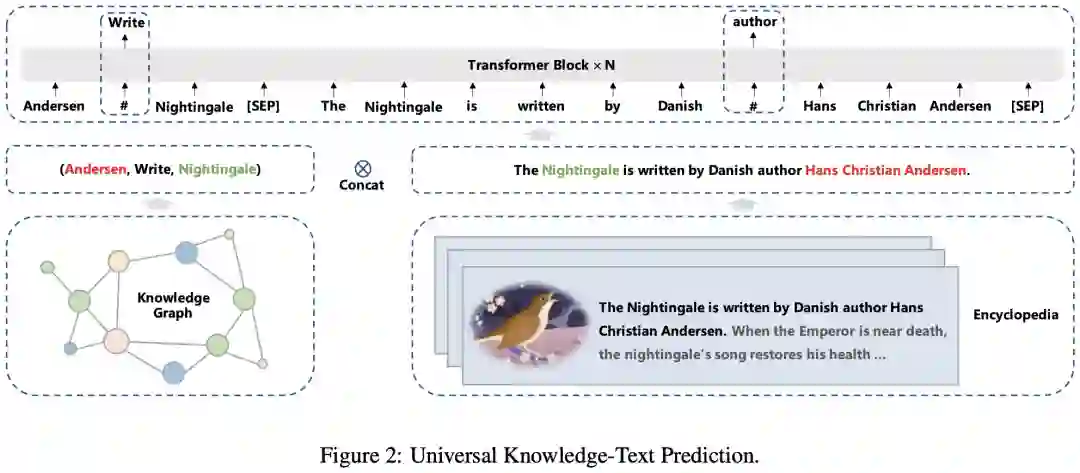
模型结构层面
针对不同下游任务的特点:视频内容理解,语义相关性,query分析等,PERKS提供了一系列不同规模和不同特点的模型。同时一些常见的模型结构优化,如pre-layer-norm,采用相对位置编码和绝对位置编码的混合模式等方式,也都在PERKS的训练过程中被验证为有效并融入到模型中。
工程优化层面
为了让TB级的语料可以更容易被使用,以及方便未来可以兼容BM25,ANN等hard negatives的生成和训练,PERKS在分布式训练过程中,抽象了一个分布式的DataSet用于挂载整体训练样本,其中,不同GPU节点使用ring-all-reduce进行梯度更新,在GPU计算和梯度更新过程中,异步data-loader不停跟这个分布式data-set进行交互,实时获取不同的训练样本,从而提升整体训练的迭代速度。此外,一些常见的训练trick,如fp16,recompute,梯度累积,lamb等,也都被作为标配应用于PERKS中。
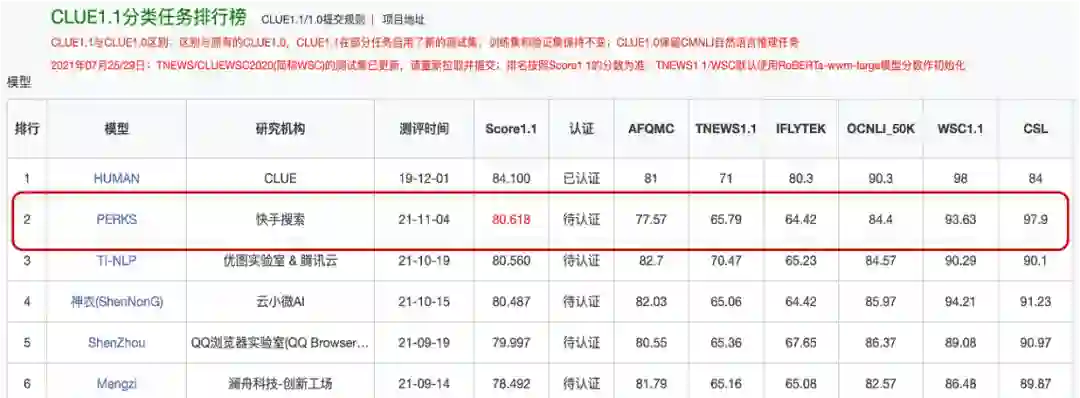
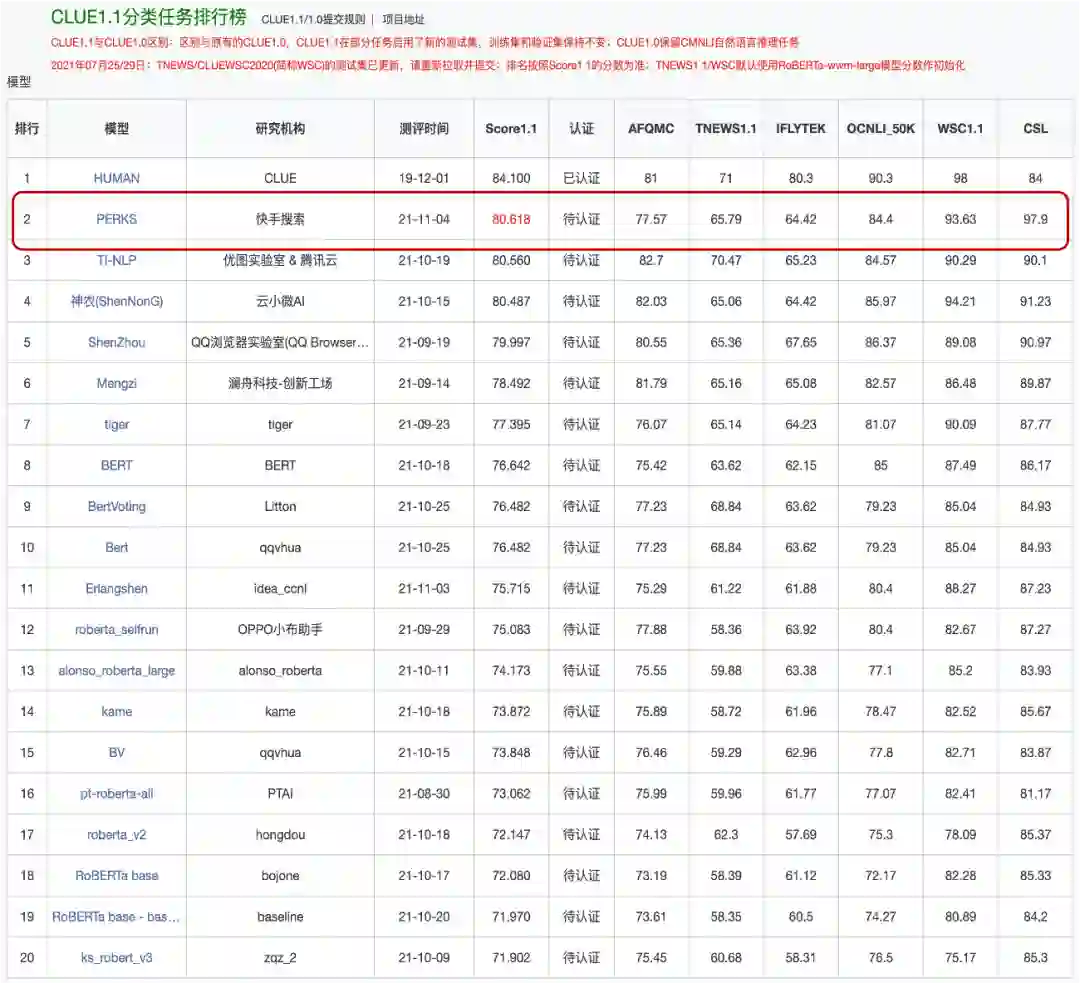
模型评估
如何评价 PERKS 在圈外场景的效果展现,快手搜索的NLPers把目光投向了公开数据集 CLUE 上,因搜索场景与分类的场景更加接近,由此选择 CLUE 中的分类任务来验证模型。在模型的迭代过程中,PERKS 在 CLUE 1.1分类任务中展现出了较好的表现,于11月4日成功登顶 CLUE 1.1分类任务排行榜,这也是给快手搜索的NLPers的一次激励!
再来看看破圈后的 PERKS 在探针实验上的表现。如图5所示,可以惊奇的发现破圈后的模型不仅能够准确预测“小红心”,就连“小红书”这样的圈外知识也被模型吸收了进来!

最后
自然语言处理工程师在快手搜索场景中能够施展才华的机会和空间还有很多,研究者也欢迎更多的 NLPer 加入进来,一起进步,一起用生活回答每一种生活!
后台回复关键词【入群】
加入卖萌屋NLP/IR/Rec与求职讨论群
后台回复关键词【顶会】
获取ACL、CIKM等各大顶会论文集!
![]()
 后台回复关键词【
后台回复关键词【